
最近將萬方數據的爬取代碼進行了重構,速度大概有10w每小時吧,因為屬於公司項目,代碼暫時就不開源了,所以在這裡先說說思路和一些註意事項吧,順帶吐槽一下萬方。 先上圖: 其實邏輯也蠻簡單的,醫學類的期刊分了16個大類,那麼首先手動將這16大類所對應的唯一id拿下來拼接出該類型的url,然後翻頁請求它就 ...
最近將萬方數據的爬取代碼進行了重構,速度大概有10w每小時吧,因為屬於公司項目,代碼暫時就不開源了,所以在這裡先說說思路和一些註意事項吧,順帶吐槽一下萬方。
先上圖:
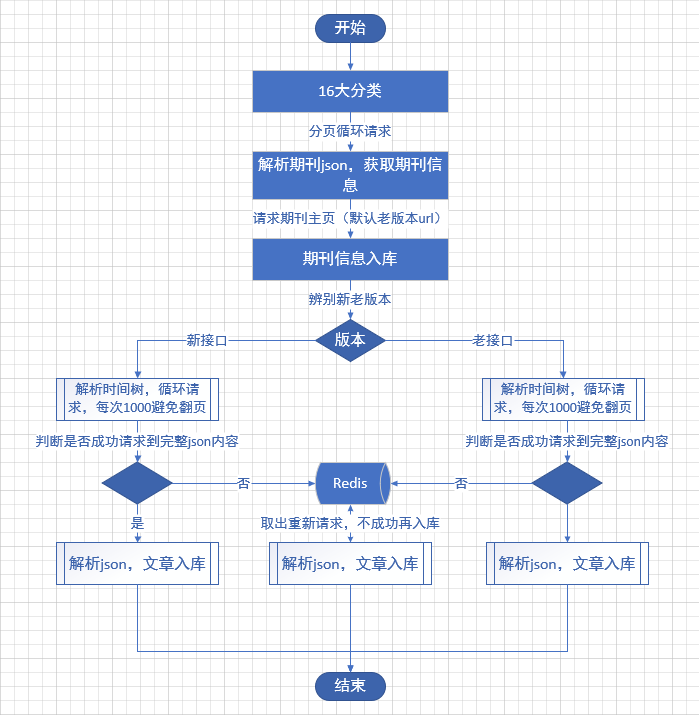
其實邏輯也蠻簡單的,醫學類的期刊分了16個大類,那麼首先手動將這16大類所對應的唯一id拿下來拼接出該類型的url,然後翻頁請求它就可以獲得該類型下的每一篇期刊的信息。
然後我們拿到了每個期刊的id,就可以拼接出每一個期刊的主頁url,但是這時就會發現,萬方中的期刊主頁路由是有兩套的:我將其稱之為新版/老版
新版:http://www.wanfangdata.com.cn/sns/user/qkzgf4
老版:http://www.wanfangdata.com.cn/perio/detail.do?perio_id=zgjhmy
這兩個版本的url是不同的,那麼如何甄別那一篇期刊是新版還是老版呢?畢竟我們現在只知道期刊的id,這裡我用的辦法是預設將每一篇期刊均視為老版,然後利用期刊id拼接出老版的url,
如果這篇期刊真是老版,那麼就可以請求到期刊主頁,如果它是新版,那麼他就會被重定向到新版主頁,最終我們只需要觀察它的response.url就清楚了。
為什麼說要分辨期刊屬於新版還是老版呢,以為關係到下一步請求該期刊中所有文章的問題。
因為萬方中每一個期刊都是規則的,有一個時間樹,表明這篇文章屬於哪個期刊、哪一年、哪一期,所以我們想要獲取這個期刊中的所有文章,首先就需要解析這個期刊的時間樹,但是新版和老版時間樹是不一樣的。
看圖:

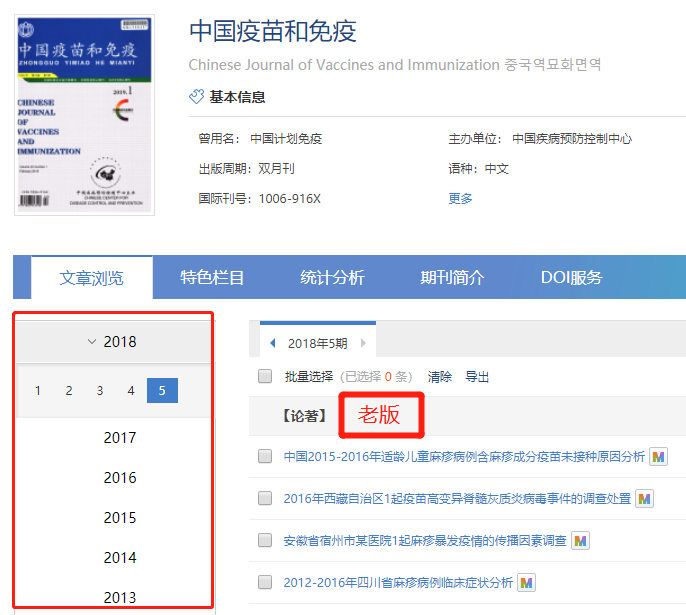
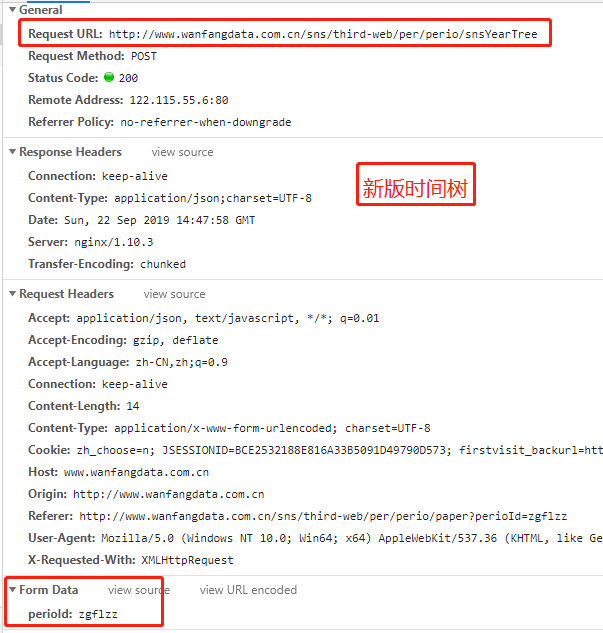
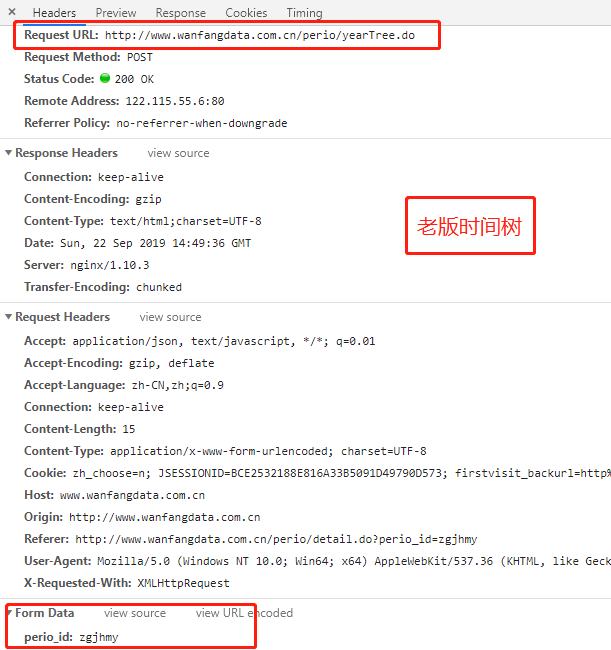
看到沒,這就是上一步我們要來辨別期刊是新版還是老版的原因了。
既然知道了期刊是新版還是老版,那麼下一步我們就需要來請求時間樹以獲得這個期刊的所有年份和每一年有多少期,以為下一步請求文章內需要用到這些信息。
本來請求到時間樹再進行解析,拿到有用信息後根據每一期每一期的請來求文章json應該是美滋滋的事情,但是得到的反饋卻並不怎麼好,因為我發現最終請求到的文章只有很少一部分,其他的都請求不到,返回空json,
我百思不得其解,然後就各種開始搗鼓,像什麼換代理啊,換UA啊,加cookie啊是一頓操作,結果是一頓操作猛如虎,一看結果250,這就很尷尬,最終折騰了好久終於被我發現了問題得關鍵所在,那就是這個:


看到沒,時間樹解析下來2019年共出了7期文章,給的是01,02直到07, 但是在請求時卻是 1到 7,0沒了。。。所以導致請求的結果都是空的。
但即使是這樣,在請求每一期文章時還會有問題,只是這個問題只在老版本中出現,那就是在解析時間樹後一期一期請求文章,按理說請求的結果都會是一個json,
但是在老版本這兒會是不是返回一個html,導致我程式報錯,因為我都是將返回結果按照json來處理的,直到現在我都沒搞明白為什麼回突然不返回json而返回html,我猜應該是請求過快了吧。
所以我多加了一部處理,當發現返回的不是json時就將這個期刊的id+年份+期數放到redis中,然後另起一個job來從redis中將其取出來再此進行請求,請求到json就其從set中去除,不然就又將其放到set中,迴圈請求。
這樣最終再解析請求到的這一期的文章json就得到文章內容了,文章的作者信息也在這個json中。
這就是整個流程了。 接下來是吐槽環節:
不得不說萬方真的是太愛改版了,最開始叫萬方醫學,後來改為了萬方數據,然後好巧不巧在我這次採集期間又又又改版了,而且被我當場發現了,並且從中發現了一個介面:
http://www.wanfangdata.com.cn/perio/page.do
這個介面是在萬方改版期間出現的,改版前沒有,改版後也沒有,就只出現了一小會兒,現在網頁中是看不到它的
這個介面是用來請求那16個大類中又哪些期刊的,返回的json中包含了各個期刊的所有信息,比期刊主頁展示的信息要全的多,並且有兩點對我的工作有了很大的幫助,本身每個期刊的時間樹都是要請求一次的,這樣無疑會拖慢爬蟲的速度,而且會出現請求不到的情況,在這個介面中卻包含了期刊的時間樹,還有一個就是本身想要獲取這個期刊的影響因數的話,是需要請求期刊主頁來解析頁面的,現在也不用了,json中也有了,省了不少事兒,但是這個介面是不在萬方官網中顯示的,說明他們現在展示時用的不是這個介面,當初只是臨時用了一會兒,以後會不會消失,不清楚。
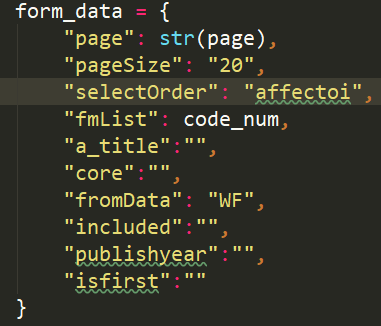
這是請求這個介面的formdata: (code_name是那16大類的唯一標識)
最後,打個廣告: 想瞭解更多Python關於爬蟲、數據分析的內容,獲取大量爬蟲爬取到的源數據,歡迎大家關註我的微信公眾號:悟道Python



