
什麼是索引? 索引是一種數據結構,具體表現在查找演算法上。 索引目的 提高查詢效率 【類比字典和借書】 如果要查“mysql”這個單詞,我們肯定需要定位到m字母,然後從下往下找到y字母,再找到剩下的sql。如果沒有索引,那麼你可能需要把所有單詞看一遍才能找到你想要的。 去圖書館借書也是一樣,如果你要借 ...
什麼是索引?
索引是一種數據結構,具體表現在查找演算法上。
索引目的
提高查詢效率
【類比字典和借書】
如果要查“mysql”這個單詞,我們肯定需要定位到m字母,然後從下往下找到y字母,再找到剩下的sql。如果沒有索引,那麼你可能需要把所有單詞看一遍才能找到你想要的。
去圖書館借書也是一樣,如果你要借某一本書,一定是先找到對應的分類科目,再找到對應的編號,這是生活中活生生的例子,通用索引,可以加快查詢速度,快速定位。
數據結構——樹
樹

二叉樹
每個節點最多含有兩個子樹的樹稱為二叉樹。
二叉查找樹ADT Tree
左子樹的鍵值小於根的鍵值,右子樹的鍵值大於根的鍵值。

平衡二叉樹AVL Tree
在符合二叉查找樹的條件下,還滿足任何節點的兩個子樹的高度最大差為1。
BTree
BTree也稱為平衡多路查找樹
B-Tree是為磁碟等外存儲設備設計的一種平衡查找樹。
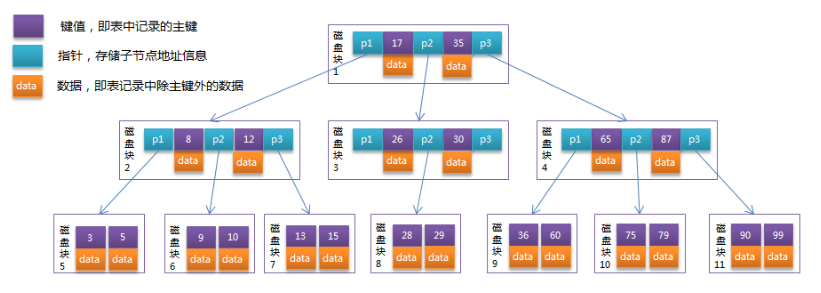
B+Tree
B+Tree是在B-Tree基礎上的一種優化
- 非葉子結點只存儲鍵值信息,不存儲數據
- 所有的葉子結點都有一個鏈指針
- 數據記錄都存放在葉子結點中
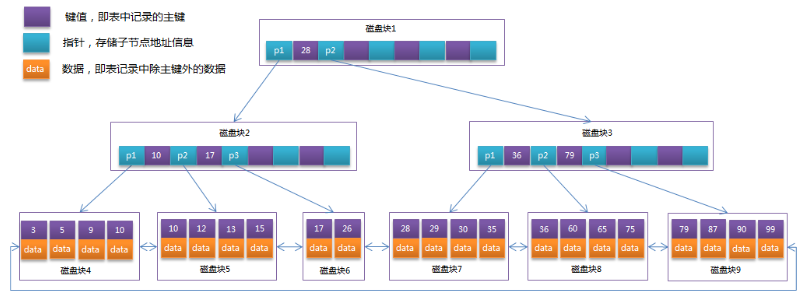
MySQL預設使用B+Tree索引
索引本身也很大,所以存儲在磁碟中,需要載入到記憶體中執行。
故:索引結構優劣標準:磁碟I/O次數
BTree是為了充分利用磁碟預讀功能而創建出來的一種數據結構。
局部性原理和磁碟預讀
局部性原理:當一個數據被用到,其附近的數據很可能會馬上用到
磁碟預讀:由於存儲介質的特性,磁碟本身存取就比主存慢很多,再加上機械運動耗費,磁碟的存取速度往往是主存的幾百分分之一,因此為了提高效率,要儘量減少磁碟I/O。為了達到這個目的,磁碟往往不是嚴格按需讀取,而是每次都會預讀,即使只需要一個位元組,磁碟也會從這個位置開始,順序向後讀取一定長度的數據放入主存。
為什麼平衡二叉樹無法利用磁碟預讀功能而BTree可以?
平衡二叉樹也稱為紅黑數,在邏輯上是平衡二叉樹,但是在物理存儲上使用的是數組,邏輯上相近的節點可能在物理上相差很遠。
BTree如何利用磁碟預讀功能?
將節點大小設為等於一個頁,BTree新建節點時,也是按照頁為單位申請,同時電腦存儲分配也是按頁對齊,那麼一個節點只需一次IO就可以讀取全部節點數據。
【如果節點大小和BTree大小不對齊,那麼同一頁節點可能需要兩次IO讀取】
綜上所述,用B-Tree作為索引結構效率是非常高的。
為什麼B+Tree比BTree更適合作為索引結構?
BTree解決了磁碟IO的問題但沒有解決元素遍歷複雜的問題。
B+Tree的葉子節點用鏈指針相連,極大提高區間訪問速度。【比如查詢50到100的記錄,查出50後,順著指針遍歷即可】
為什麼不使用Hash索引而使用B+Tree索引?
Hash索引本質上是Hash表,是一種KV鍵值對的存儲結構。
無法提高區間訪問速度。
B+Tree的葉子結點可以存哪些東西?
可能是整行數據,也可能是主鍵的值。
前者被稱為聚簇索引,後者稱為非聚簇索引。
聚簇索引更快!!!
為什麼???聚簇索引已經查到整行數據了,而非聚簇索引還可能根據主鍵值再進行查詢一次。
例外:覆蓋索引——數據直接從索引中取得。


