
【作者】 王棟:攜程技術保障中心資料庫專家,對資料庫疑難問題的排查和資料庫自動化智能化運維工具的開發有強烈的興趣。 【問題描述】 我們知道當mysqld進程使用到SWAP時,就會嚴重影響到MySQL的性能。SWAP的問題比較複雜,本文會從SWAP的原理開始,分享我們碰到的案例和分析思路。 【SWAP ...
【作者】
王棟:攜程技術保障中心資料庫專家,對資料庫疑難問題的排查和資料庫自動化智能化運維工具的開發有強烈的興趣。
【問題描述】
我們知道當mysqld進程使用到SWAP時,就會嚴重影響到MySQL的性能。SWAP的問題比較複雜,本文會從SWAP的原理開始,分享我們碰到的案例和分析思路。
【SWAP原理】
swap是把一部分磁碟空間或文件,當作記憶體來使用。它有換出和換入兩種方式,換出是進程把不活躍的記憶體數據存儲到磁碟上,並釋放數據占用的記憶體空間,換入是進程再次訪問這部分數據的時候,從磁碟讀到記憶體中。
swap擴展了記憶體空間,是為了回收記憶體。記憶體回收的機制,一種是當記憶體分配沒有足夠的空間時,系統需要回收一部分記憶體,稱為直接記憶體回收。另外還有一個專門的kswapd0進程用來定期回收記憶體。為了衡量記憶體的使用情況,定義了三個記憶體閥值,分為頁最小水位(min)、頁低水位(low)、頁高水位(high)
執行下麵命令,可以看到水位線對應的值,如下圖所示
cat /proc/zoneinfo |grep -E "Node|pages free|nr_inactive_anon|nr_inactive_file|min|low|high"|grep -v "high:"
記憶體回收行為主要有
1、當系統剩餘記憶體低於low時,kswapd開始起作用進行記憶體回收,直到記憶體達到high水位。
2、當剩餘記憶體達到min時就會觸發直接回收。
3、當觸發全局回收,並且file+free<=high時,一定會進行針對匿名頁的swap。
【NUMA與SWAP】
有些案例我們發現系統還有大量剩餘空間的情況下,已經使用了swap。這正是NUMA架構導致的。NUMA架構下每個Node都有本地的記憶體空間,Node間記憶體使用不均衡,當某個Node的記憶體不足時,就可能導致swap的產生。
【swappiness】
我們大概理解了記憶體回收的機制,回收的記憶體包括文件頁和匿名頁。對文件頁的回收就是直接回收緩存,或者把臟頁寫回到磁碟再進行回收。對匿名頁的回收,就是通過swap,將數據寫入磁碟後再釋放記憶體。
通過調整/proc/sys/vm/swappiness的值,可以調整使用swap的積極程度,swappiness值從0-100,值越小,傾向於回收文件頁,儘量少的使用swap。我們最初將這個值調整為1,但發現並不能避免swap的產生。實際上即使將這個值設置0,當滿足file+free<=high時,還是會發生swap。
【關閉NUMA的方案】
在NUMA開啟的情況,由於NUMA節點間記憶體使用不均衡,可能導致swap,解決這個問題主要有下麵一些方案
1、 在mysqld_safe腳本中加上“numactl –interleave all”來啟動mysqld
2、 Linux Kernel啟動參數中加上numa=off,需要重啟伺服器
3、 在BIOS層面關閉NUMA
4、 MySQL 5.6.27/5.7.9開始引用innodb_numa_interleave選項對於2、3、4關閉NUMA的方案比較簡單,不做詳細描述,下麵重點描述下方案1
【開啟numa interleave訪問的步驟】
1、 yum install numactl -y
2、修改/usr/bin/mysqld_safe文件
cmd="`mysqld_ld_preload_text`$NOHUP_NICENESS"下新增一條腳本
cmd="/usr/bin/numactl --interleave all $cmd"
3、service mysql stop
4、寫入硬碟,防止數據丟失
sync;sync;sync
5、延遲10秒
sleep 10
6、清理pagecache、dentries和inodes
sysctl -q -w vm.drop_caches=3
7、service mysql start
8、驗證numactl –interleave all是否生效,可以通過下麵命令,interleave_hit是採用interleave策略從該節點分配的次數,沒有啟動interleave策略的伺服器,這個值會很低
numastat -mn -p `pidof mysqld`至此我們MySQL5.6的伺服器通過上面方案解決了由於NUMA Node間記憶體分配不均導致的swap的問題。對於MySQL5.7.23版本的伺服器,我們使用了innodb_numa_interleave選項,但問題並沒有徹底解決。
【使用MySQL5.7新增innodb_numa_interleave選項的問題】
在開啟innodb_numa_interleave選項的伺服器中,仍然會存在NUMA Node間記憶體分配不均衡的問題,會導致swap產生。針對這個問題做了進一步分析:
1、 MySQL 版本為5.7.23,已經開啟了innodb_numa_interleave
2、 使用命令查看mysqld進程的記憶體使用情況,numastat -mn `pidof mysqld`
可以看出Node 0使用了約122.5G記憶體,Node 1使用了約68.2G記憶體,其中Node0上的可用空間只剩566M,如果後面申請Node 0節點分配記憶體不足,就可能產生swap
Per-node process memory usage (in MBs) for PID 1801 (mysqld)
Node 0 Node 1 Total
--------------- --------------- ---------------
Huge 0.00 0.00 0.00
Heap 0.00 0.00 0.00
Stack 0.01 0.07 0.09
Private 125479.61 69856.82 195336.43
---------------- --------------- --------------- ---------------
Total 125479.62 69856.90 195336.523、是innodb_numa_interleave沒有生效嗎,通過分析/proc/1801/numa_maps文件可以進一步查看mysqld進程的記憶體分配情況
以其中一條記錄為例,
7f9067850000 表示記憶體的虛擬地址
interleave:0-1 表示記憶體所用的NUMA策略,這裡使用了Interleave方式
anon=5734148 匿名頁數量
dirty=5734148 臟頁數量
active=5728403 活動列表頁面的數量
N0=3607212 N1=2126936 節點0、1分配的頁面數量
kernelpagesize_kB=4 頁面大小為4K
7f9067850000 interleave:0-1 anon=5734148 dirty=5734148 active=5728403 N0=3607212 N1=2126936 kernelpagesize_kB=44、通過解析上面文件,對Node 0和Node 1節點分配的頁面數量做統計,可以計算出Node 0通過interleave方式分配了約114.4G記憶體,Node 1通過interleave方式分配了約64.7G記憶體
說明innodb_numa_interleave開關是實際生效的,但是即使mysql使用了interleave的分配方式,仍然存在不均衡的問題
5、通過innodb_numa_interleave相關的源碼,可以看出當開關開啟時,MySQL調用linux的set_mempolicy函數指定MPOL_INTERLEAVE策略跨節點來分配記憶體set_mempolicy(MPOL_INTERLEAVE, numa_all_nodes_ptr->maskp, numa_all_nodes_ptr->size)
當開關關閉時,set_mempolicy(MPOL_DEFAULT, NULL, 0),使用預設的本地分配策略
my_bool srv_numa_interleave = FALSE;
#ifdef HAVE_LIBNUMA
#include <numa.h>
#include <numaif.h>
struct set_numa_interleave_t
{
set_numa_interleave_t()
{
if (srv_numa_interleave) {
ib::info() << "Setting NUMA memory policy to"
" MPOL_INTERLEAVE";
if (set_mempolicy(MPOL_INTERLEAVE,
numa_all_nodes_ptr->maskp,
numa_all_nodes_ptr->size) != 0) {
ib::warn() << "Failed to set NUMA memory"
" policy to MPOL_INTERLEAVE: "
<< strerror(errno);
}
}
}
~set_numa_interleave_t()
{
if (srv_numa_interleave) {
ib::info() << "Setting NUMA memory policy to"
" MPOL_DEFAULT";
if (set_mempolicy(MPOL_DEFAULT, NULL, 0) != 0) {
ib::warn() << "Failed to set NUMA memory"
" policy to MPOL_DEFAULT: "
<< strerror(errno);
}
} }};【測試對比開啟innodb_numa_interleave開關和numactl –interleave=all啟動mysqld進程兩種方式NUMA節點的記憶體分配情況】
場景一、numactl --interleave=all啟動mysqld進程的方式
1、 修改systemd配置文件,刪除my.cnf中innodb_numa_interleave=on開關配置,重啟MySQL服務
/usr/bin/numactl --interleave=all /usr/sbin/mysqld --daemonize --pid-file=/var/run/mysqld/mysqld.pid $MYSQLD_OPTS2、 運行select count(*) from test.sbtest1語句,這個表中有2億條記錄,運行14分鐘,會將表中的數據讀到buffer pool中
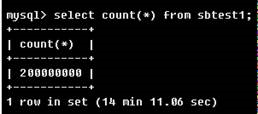
3、運行結束後,分析numa_maps文件可以看到mysqld進程採用了interleave跨節點訪問的分配方式,兩個Node間分配的記憶體大小基本一致
7f9a3c5b3000 interleave:0-1 anon=1688811 dirty=1688811 N0=842613 N1=846198 kernelpagesize_kB=4
7f9a3c5b3000 interleave:0-1 anon=2497435 dirty=2497435 N0=1247949 N1=1249486 kernelpagesize_kB=44、mysqld進程總的分配也是均衡的
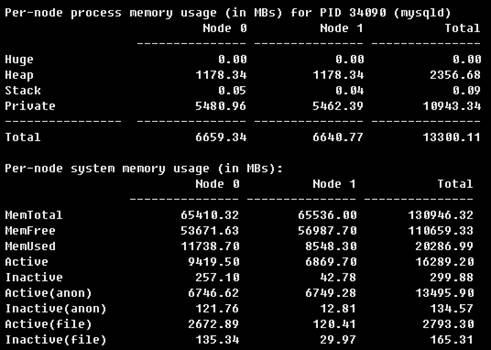
場景二、開啟innodb_numa_interleave的方式
1、增加my.cnf中innodb_numa_interleave=on開關配置,重啟MySQL服務,執行與場景一相關的SQL語句
2、運行結束後,分析numa_maps文件可以看到mysqld進程採用interleave方式分配的在不同Node間是基本平衡的
7f71d8d98000 interleave:0-1 anon=222792 dirty=222792 N0=111652 N1=111140 kernelpagesize_kB=4
7f74a2e14000 interleave:0-1 anon=214208 dirty=214208 N0=107104 N1=107104 kernelpagesize_kB=4
7f776ce90000 interleave:0-1 anon=218128 dirty=218128 N0=108808 N1=109320 kernelpagesize_kB=43、不過仍有部分記憶體使用了default的本地分配策略,這部分記憶體全部分配到了Node 0上
7f31daead000 default anon=169472 dirty=169472 N0=169472 kernelpagesize_kB=44、最終mysqld進程分配的記憶體Node 0 比Node 1大了約1G
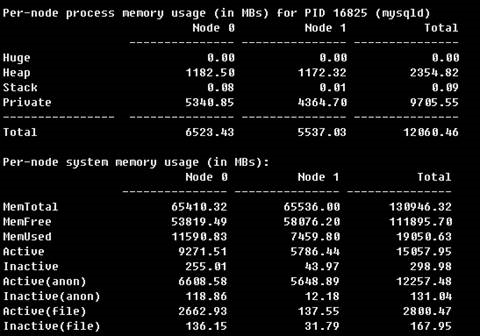
【MySQL5.7.23啟用numactl –interleave=all的方法】
MySQL5.7版本不再使用mysqld_safe文件,所以啟用numactl –interleave=all的方式,與MySQL 5.6的方法不同,總結如下:
1、修改vim /etc/my.cnf文件,刪除innodb_numa_interleave配置項
2、修改systemd 的本地配置文件,vim /usr/lib/systemd/system/mysqld.service,增加/usr/bin/numactl --interleave=all命令
# Start main service
ExecStart=/usr/bin/numactl --interleave=all /usr/sbin/mysqld --daemonize --pid-file=/var/run/mysqld/mysqld.pid $MYSQLD_OPTS
3、停止MySQL服務
systemctl stop mysqld.service
4、重新載入配置文件
systemctl daemon-reload
5、寫入硬碟,防止數據丟失
sync;sync;sync
6、延遲10秒
sleep 10
7、清理pagecache、dentries和inodes
sysctl -q -w vm.drop_caches=3
8、啟動MySQL服務
systemctl start mysqld.service
9、驗證是否生效,
首先確認show global variables like ' innodb_numa_interleave';開關為關閉狀態
正常情況下mysqld進程會全部採用interleave跨節點訪問的分配方式,如果可以查詢到其他訪問方式的信息,表示interleave方式沒有正常生效
less /proc/`pidof mysqld`/numa_maps|grep -v 'interleave'【結論】
numactl –interleave=all啟動mysqld進程的方式NUMA不同Node間分配的記憶體會更加均衡。
這個差異是與innodb_numa_interleave參數執行的策略有關,開啟後,全局記憶體採用了interleave的分配方式,但線程記憶體採用了default的本地分配方式。
而如果使用numactl –interleave=all啟動mysqld進程,所有記憶體都會採用interleave的分配方式。


