
講redolog和binlog之前,先要講一下一條mysql語句的執行過程。 1、client的寫請求到達連接器,連接器負責管理連接、驗證許可權; 2、然後是分析器,負責複習語法,如果這條語句有執行過,在緩存內,那麼就從緩存去寫; 3、緩存沒有的話,那就到了優化器部分。負責優化sql讀寫,選擇索引; ...
講redolog和binlog之前,先要講一下一條mysql語句的執行過程。
1、client的寫請求到達連接器,連接器負責管理連接、驗證許可權;
2、然後是分析器,負責複習語法,如果這條語句有執行過,在緩存內,那麼就從緩存去寫;
3、緩存沒有的話,那就到了優化器部分。負責優化sql讀寫,選擇索引;
4、接下來是執行器,負責操作引擎,並返回結果。
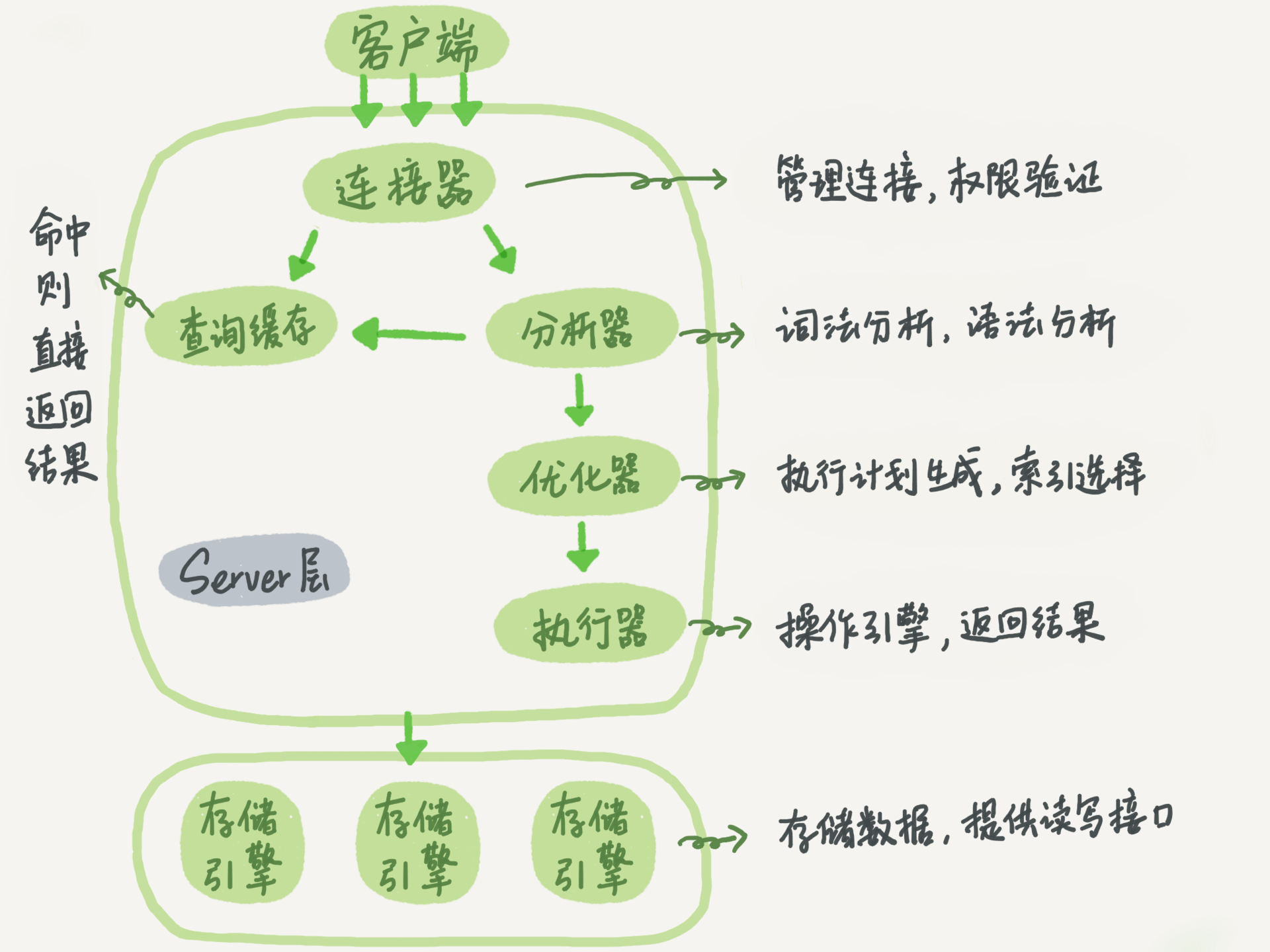
接下來就要進入正題,說一下第四步是如何執行的。
redo log
與查詢不一樣的是,更新流程還涉及兩個重要的日誌模塊,它們正是我們今天要討論的主角:redo log(重做日誌)和bin log(歸檔日誌)。
innodb的更新操作不是直接寫入磁碟的,而是先記錄日誌,也就是redo log,然後等到db沒那麼忙碌的時候刷到磁碟上。這樣保證了mysql的高效寫操作。為什麼會這麼設計呢?因為每次更新操作先要查詢,這裡有磁碟io,查到後修改數據,刷入磁碟,又是一次io,每次都這樣做的話會非常慢,所以就先記錄在記憶體中,然後記錄在redo-log中,然後按照策略刷入磁碟。這個技術叫做WAL技術。因為如果只記錄在記憶體中的話,mysql崩潰會導致改動的數據丟失。所以redo log保證了innodb的crash-safe。(註意:mysql是沒有redo log的,它是innodb特有的。不過現在mysql大部分情況下都會選用innnodb。)mysql crash後,故障恢復會從redo log中讀取數據。
不過redo log是有大小限制的,比如設置了4個1G的redo log,那麼第3個寫滿的時候會覆蓋第0個的log文件。
bin log
redo log是在存儲引擎層面的日誌,負責存儲和crash恢復。bin log 是server層的日誌。
為什麼會有兩份日誌呢?
因為只依靠bin log是沒有crash safe能力的。而且redo log是有大小限制的。
redo log和bin log主要有如下幾個區別:
1、所屬層不一樣,bin log是server層,redo log是存儲層的日誌,只有innodb才有。
2、redo log有大小限制,是迴圈寫的,而binlog沒有這樣的限制;
3、redo log是物理日誌,記錄的是“在某個數據頁上做了什麼修改”,bin log是邏輯日誌,記錄的是語句的原始邏輯,比如給id=3的這一行的count做加一操作。
接下來看一下一條update語句的執行過程:
1、首先查到這一行或者多行數據;
2、然後修改數據,寫入記憶體,並將修改寫入redo log,此時redo log處於prepare階段,並告訴執行器可以提交了;
3、返回ok給server的執行器,執行器收到ok後在binlog中記錄原始語句,寫入磁碟;
4、binlog記錄完成後,執行器告訴引擎層,引擎層將對應的redo log從prepare狀態改成commit狀態。
這就是2PC。
如果我們要將資料庫恢復到某一個時刻點,比如本周二,那麼找到周二前最近的全量備份,然後執行備份時間到本周二的binlog,得到一個臨時的資料庫。
可不可以不要做兩階段提交,而改成把這兩步操作獨立做呢?可以考慮一下如下兩個場景(把某一行的count列從0改成1):
1、先做redo log,後寫bin log
如果先寫redo log成功後,還沒寫binlog就崩了,此時count列已經變為1,而數據恢復時,用的是bin log,bin log里少了這一個操作,那麼就出現用bin log恢復出來的db和當前的db比,出現了不一致。
2、如果先做bin log,然後寫redo log
如果寫完bin log後,redo log還沒寫,就崩了,也就是說崩潰時的db是沒有count=1這個修改的。而用bin log恢復出來的db里是有這行記錄的,那麼也出現了不一致。
所以,update時針對redo log和bin log做2PC還是很有必要的。
此外。redo log有個配置項innodb_flush_log_at_trx_commit設置成1,保證每次事務後時redo log都能更新到磁碟。這樣就不會出現丟失的現象。
innodb_flush_log_at_trx_commit=0表示每秒寫入磁碟。這樣有可能最多丟失1秒鐘的數據。
設置為2時,表示每次事務後將redo log的緩存寫入os buffer,然後是每秒調用fsync()將os buffer中的日誌寫入到log file on disk。這樣的話,如果系統崩了會丟失一秒的數據,如果mysql崩了,則不會丟失數據。
sync_binlog也建議設置成1,表示每次事務後的binlog會持久化到磁碟,這樣可以保證mysql異常重啟後的binlog不會丟失記錄。
最有有個問題,寫日誌也是寫磁碟,直接更新數據也是寫磁碟,都是寫磁碟,效率不是一樣的嗎?這樣innodb的redo log不是多此一舉嗎?因為redo log是追加的形式寫磁碟,所以效率很高,而修改資料庫的數據是隨即寫,效率就低了很多。


