
大家或許知道,Python 為了提高記憶體的利用效率,採用了一套共用對象記憶體的分配策略。 例如,對於那些數值較小的數字對象([ 5, 256])、布爾值對象、None 對象、較短的字元串對象( 通常 是 20)等等,字面量相等的對象實際上是同一個對象。 我很早的時候曾寫過一篇《 "Python中的“特 ...
大家或許知道,Python 為了提高記憶體的利用效率,採用了一套共用對象記憶體的分配策略。
例如,對於那些數值較小的數字對象([-5, 256])、布爾值對象、None 對象、較短的字元串對象(通常 是 20)等等,字面量相等的對象實際上是同一個對象。
# 共用記憶體地址的例子
a = 100
b = 100
s = "python_cat"
t = "python_cat"
id(a) == id(b) # 結果:True
id(s) == id(t) # 結果:True我很早的時候曾寫過一篇《Python中的“特權種族”是什麼?》,把這些對象統稱為“特權種族”,它們是 Python 在記憶體管理機制上使用的優化技巧。
前不久,我還寫了一篇《Python 記憶體分配時的小秘密》,也是介紹記憶體管理的技巧。
這兩篇文章有所區別:舊文主要涉及了記憶體共用與對象駐留的機制,而新文介紹的是記憶體分配、動態擴容以及記憶體回收的相關機制。
它們令我不由自主地想到兩個詞:共用經濟與供需平衡。
如果你沒有讀過那兩篇文章,我強烈建議你先回看一下,然後再看看我的聯想是否有道理:那幾類特權種族對象其實是在共用記憶體,錶面上的不同對象,其實是在迴圈利用;至於供需平衡也好理解,創建某些對象時,按照預期的訴求去分配記憶體,在擴容時則靈活調節,達到了供需之間的平衡。
透過現象看本質,Python 可以很有趣。
但是,Python 的有趣之處還不止於此,本文要繼續分享另一種記憶體管理機制,在某種程度上,它實現了共用經濟與供需平衡的融合,我們從中可揭開 Python 的另一重身份……
1、不可變對象的共用經濟
上面列出的"特權種族"都是不可變對象(而“供需平衡”主要出現於可變對象),對於這些不變的對象,當出現多處使用時,共用一個對象似乎是種不錯的優化方法。
我曾有一種猜想:Python 的不可變對象都可能是特權種族。
我沒有試圖去完全證實它,本文只想考察其中一種不可變對象:元組。它是不可變對象,那麼,是否有共用對象的機制呢?
下麵把它跟列表作一下對比:
# 空對象的差別
a = []
b = []
c = ()
d = ()
print(id(a)==id(b)) # 結果:False
print(id(c)==id(d)) # 結果:True由此可見,兩個空列表是不同的對象,而兩個空元組其實是同一個對象。這至少說明瞭,空元組在記憶體中只有一個,它屬於已提到的特權種族。
將實驗延伸到集合與字典,它們是可變對象,你會發現結果跟列表一樣,存在多個副本,即不是特權種族。我就不舉例了。
由上述的實驗結果,還能引出兩個問題,但是它們偏離了本文主題,我不打算深入辨析,簡單列一下:
- 除了空元組,還有什麼樣的元組是“特權種族”?(PS:從元素的數量、類型、元素自身的大小考慮,就我小範圍試驗,還沒發現。所以,空元組是獨特的唯一?)
- 編譯期與運行期有所區別,這在之前寫字元串的 intern 機制時(《Intern機制的軟肋》)也分析過。(PS:print(id([]) == id([])),結果為 True,與上例先賦值再比較不同。)
2、可變對象的共用經濟
空元組體現了共用經濟,但由於它是不可變對象,所以不存在動態擴容,就只體現了極少的供需平衡。
作為對照,列表等可變對象充分表現了供需平衡,卻似乎沒辦法體現共用經濟。
比如說,我們把一個列表想象成一個可自增的杯子(畢竟它是某種容器),再把它的元素想象成不同種類的液體(水、可樂、酒……)。
那麼,我們的問題是:兩杯東西是否可以共用為一個對象呢?或者說,有沒有可能共用那隻杯子呢?這樣就可以節省記憶體(在那篇講小秘密的文章中展示過:“空杯子”占用的記憶體可不少),提升效率啦。
對於第一個問題,答案為否,驗證過程略。對於第二個問題,在上一節中,我們已驗證過兩個空杯子(即空列表),答案也為否。
但是,第二個問題還有其它的可能!下麵讓我們換一種實驗方法:
# 實驗版本:Python 3.6.1
a = [[] for i in range(4)]
print(id(a))
for i in range(len(a)):
print(f'{i} -- {id(a[i])}')
# a[i] = 1 # PS:可去除註釋,再執行一次,結果的順序有差別
del a
print("after del")
b = [[] for i in range(4)]
print(id(b))
for i in range(len(b)):
print(f'{i} -- {id(b[i])}')以上代碼在不同環境中,執行結果可能有所差異。我執行的一次結果如下:
2012909395656
0 -- 2012909395272
1 -- 2012909406472
2 -- 2012909395208
3 -- 2012909395144
after del
2012909395656
0 -- 2012909395272
1 -- 2012909406472
2 -- 2012909395208
3 -- 2012909395144分析結果可知:列表對象在被回收之後,並不會徹底消除,它的記憶體地址會傳遞給新創建的列表,也就是說,新創建的列表其實共用了舊列表的記憶體地址!
再結合前面的例子,我們可以說,先後靜態創建的兩個列表會分配不同的記憶體地址,但是,經過動態回收之後,先後創建的列表可能是同一個記憶體地址!(註意:這裡說的是“可能”,因為在新列表創建前,若有其它地方也在創建列表,那後者可能奪去先機。)
延伸到其它基本的可變對象,例如集合與字典,也有同樣的共用策略,其目的顯而易見:迴圈利用這些對象的“殘軀”,可以避免記憶體碎片,提高執行性能。
共用一隻杯子,總比重新創造一隻杯子,要更高效便捷,對吧?
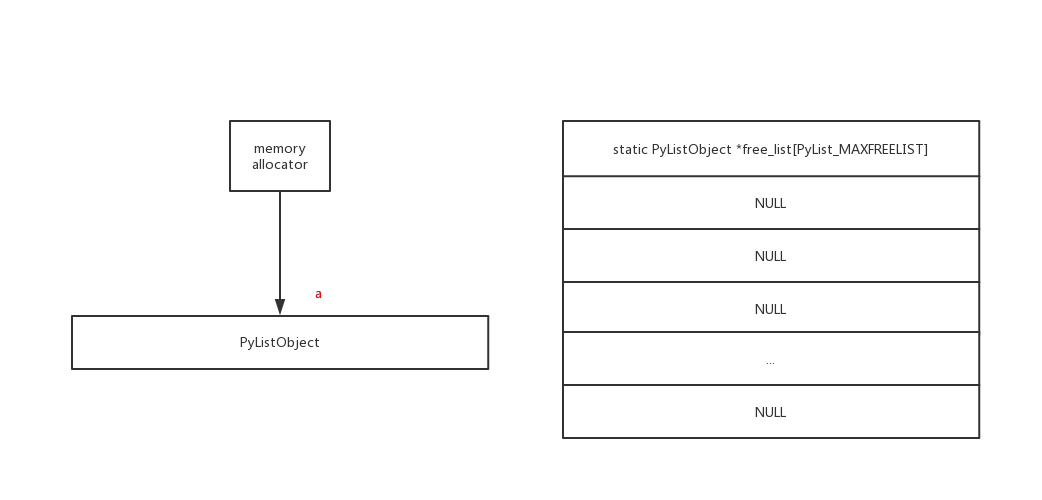
Python 解釋器在實現這個機制時,使用了一個叫做free_list 的全局變數,其工作原理是:
- 當創建新的對象時,則檢查 free_list 內是否有可用對象,有則取出使用,沒有則創建
- 當這些對象被析構時,則檢查 free_list 是否有剩餘空間,有則存入其中
- 某類對象存入 free_list 時,只保留“軀殼”,而清空其內部所有的元素(即只共用杯子,不共用杯中物)
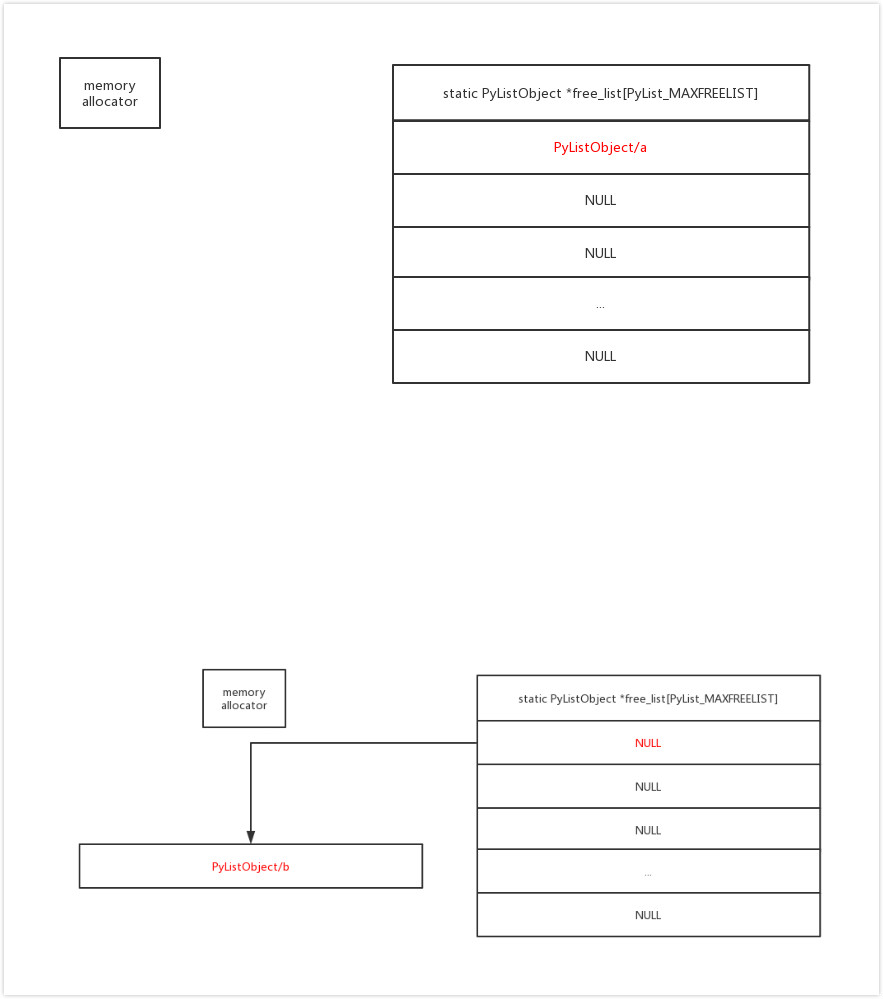
好了,現在我們可以說,列表、集合與字典這些可變對象,它們都不是前文所說的特權種族,但是,在它們背後都藏著迴圈使用的共用思想,這一點卻是相通的。
Python 解釋器在記憶體管理上真是煞費苦心啊,在那些司空見慣的基本對象上,它施加了諸多的小魔法,在我們毫不覺察的時候,它們有條不紊地運作,而當我們終於見識清楚後,就不得不感嘆它的精妙了。
Python 算得上是一個精打細算的“經濟學家”了。
回顧全文,最後作一個小結:
- 較小的數字、較短的字元串、布爾值與空元組等不可變對象,它們存在著“共用經濟”的機制,提升了記憶體的使用效率
- 列表、集合與字典等可變對象,它們存在著預分配及超額分配等“供需平衡”的機制,提升了記憶體的分配效率
- 列表等對象還存在著共用“容器外殼”的機制,迴圈利用空閑資源,綜合提升程式性能
PS:本文寫作過半時,我覺得應該把它寫入“喵星來客”系列,但思前想後,最終作罷了(主要是懶)。它們的思辨力及洞察力是一脈相承的,若你喜歡本文的話,我推薦閱讀“喵星來客”系列(其中兩篇):

公眾號【Python貓】, 本號連載優質的系列文章,有喵星哲學貓系列、Python進階系列、好書推薦系列、技術寫作、優質英文推薦與翻譯等等,歡迎關註哦。


