
一、Storm 1.1 簡介 Storm 是一個開源的分散式實時計算框架,可以以簡單、可靠的方式進行大數據流的處理。通常用於實時分析,線上機器學習、持續計算、分散式 RPC、ETL 等場景。Storm 具有以下特點: + 支持水平橫向擴展; + 具有高容錯性,通過 ACK 機制每個消息都不丟失; + ...
一、Storm
1.1 簡介
Storm 是一個開源的分散式實時計算框架,可以以簡單、可靠的方式進行大數據流的處理。通常用於實時分析,線上機器學習、持續計算、分散式 RPC、ETL 等場景。Storm 具有以下特點:
- 支持水平橫向擴展;
- 具有高容錯性,通過 ACK 機制每個消息都不丟失;
- 處理速度非常快,每個節點每秒能處理超過一百萬個 tuples ;
- 易於設置和操作,並可以與任何編程語言一起使用;
- 支持本地模式運行,對於開發人員來說非常友好;
- 支持圖形化管理界面。
1.2 Storm 與 Hadoop對比
Hadoop 採用 MapReduce 處理數據,而 MapReduce 主要是對數據進行批處理,這使得 Hadoop 更適合於海量數據離線處理的場景。而 Strom 的設計目標是對數據進行實時計算,這使得其更適合實時數據分析的場景。
1.3 Storm 與 Spark Streaming對比
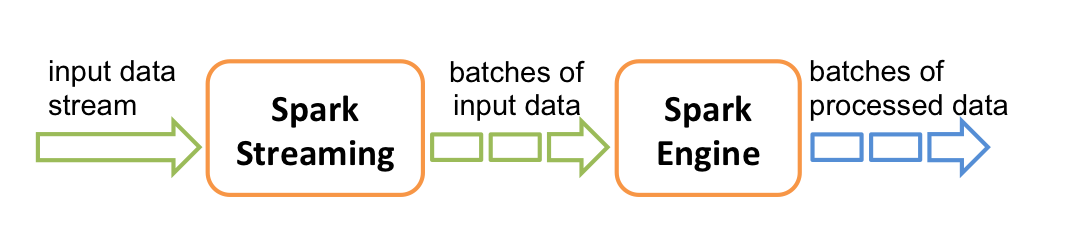
Spark Streaming 並不是真正意義上的流處理框架。 Spark Streaming 接收實時輸入的數據流,並將數據拆分為一系列批次,然後進行微批處理。只不過 Spark Streaming 能夠將數據流進行極小粒度的拆分,使得其能夠得到接近於流處理的效果,但其本質上還是批處理(或微批處理)。
1.4 Strom 與 Flink對比
storm 和 Flink 都是真正意義上的實時計算框架。其對比如下:
| storm | flink | |
|---|---|---|
| 狀態管理 | 無狀態 | 有狀態 |
| 視窗支持 | 對事件視窗支持較弱,緩存整個視窗的所有數據,視窗結束時一起計算 | 視窗支持較為完善,自帶一些視窗聚合方法, 並且會自動管理視窗狀態 |
| 消息投遞 | At Most Once At Least Once |
At Most Once At Least Once Exactly Once |
| 容錯方式 | ACK 機制:對每個消息進行全鏈路跟蹤,失敗或者超時時候進行重發 | 檢查點機制:通過分散式一致性快照機制, 對數據流和運算元狀態進行保存。在發生錯誤時,使系統能夠進行回滾。 |
註 : 對於消息投遞,一般有以下三種方案:
- At Most Once : 保證每個消息會被投遞 0 次或者 1 次,在這種機制下消息很有可能會丟失;
- At Least Once : 保證了每個消息會被預設投遞多次,至少保證有一次被成功接收,信息可能有重覆,但是不會丟失;
- Exactly Once : 每個消息對於接收者而言正好被接收一次,保證即不會丟失也不會重覆。
二、流處理
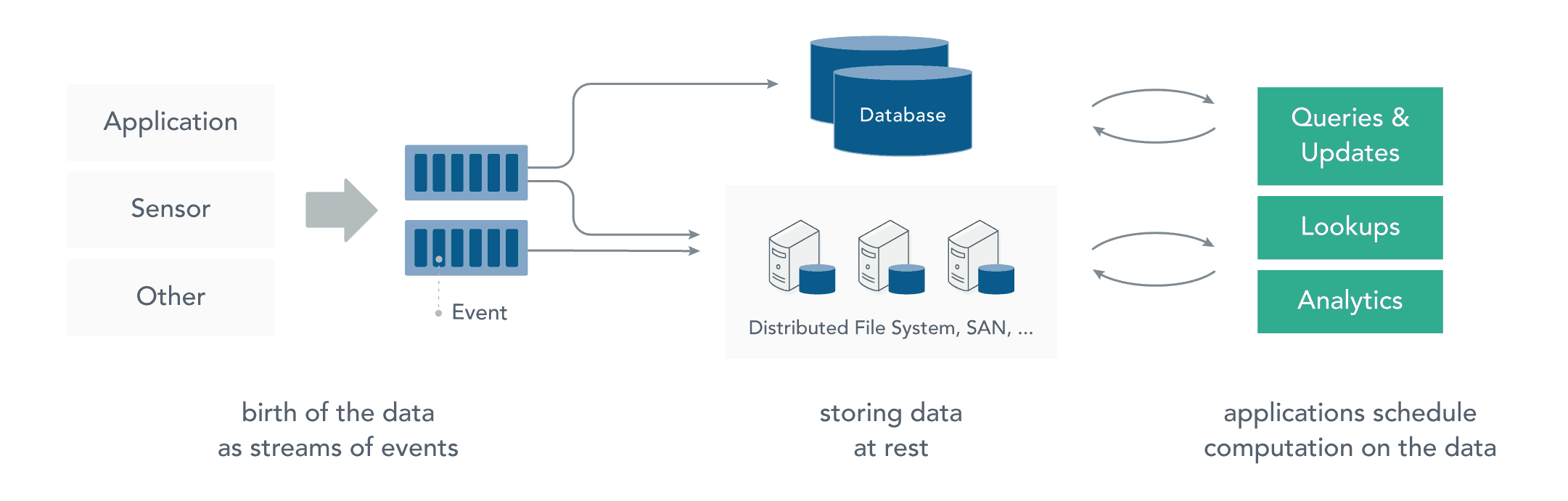
2.1 靜態數據處理
在流處理之前,數據通常存儲在資料庫或文件系統中,應用程式根據需要查詢或計算數據,這就是傳統的靜態數據處理架構。Hadoop 採用 HDFS 進行數據存儲,採用 MapReduce 進行數據查詢或分析,這就是典型的靜態數據處理架構。
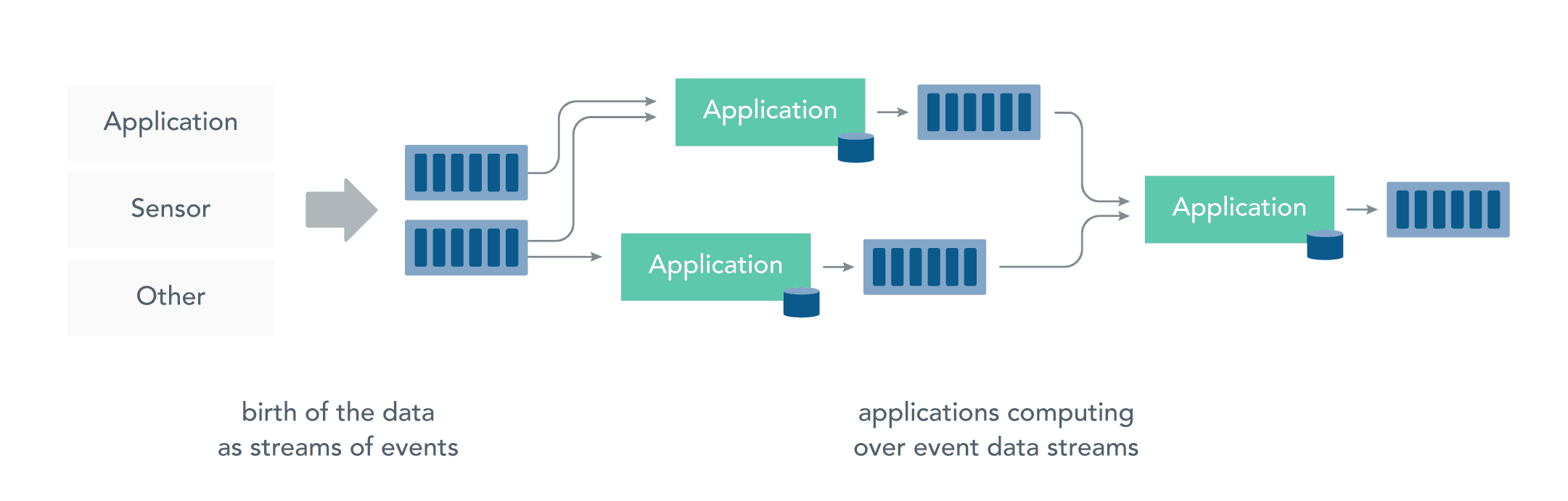
2.2 流處理
而流處理則是直接對運動中數據的處理,在接收數據的同時直接計算數據。實際上,在真實世界中的大多數數據都是連續的流,如感測器數據,網站用戶活動數據,金融交易數據等等 ,所有這些數據都是隨著時間的推移而源源不斷地產生。
接收和發送數據流並執行應用程式或分析邏輯的系統稱為流處理器。流處理器的基本職責是確保數據有效流動,同時具備可擴展性和容錯能力,Storm 和 Flink 就是其代表性的實現。
流處理帶來了很多優點:
可以立即對數據做出反應:降低了數據的滯後性,使得數據更具有時效性,更能反映對未來的預期;
可以處理更大的數據量:直接處理數據流,並且只保留數據中有意義的子集,然後將其傳送到下一個處理單元,通過逐級過濾數據,從而降低實際需要處理的數據量;
更貼近現實的數據模型:在實際的環境中,一切數據都是持續變化的,想要通過歷史數據推斷未來的趨勢,必須保證數據的不斷輸入和模型的持續修正,典型的就是金融市場、股票市場,流處理能更好地處理這些場景下對數據連續性和及時性的需求;
分散和分離基礎設施:流式處理減少了對大型資料庫的需求。每個流處理程式通過流處理框架維護了自己的數據和狀態,這使其更適合於當下最流行的微服務架構。
參考資料
更多大數據系列文章可以參見 GitHub 開源項目: 大數據入門指南


