一、數據挖掘 中文分詞 • 一段文字不僅僅在於字面上是什麼,還在於怎麼切分和理解。• 例如: – 阿三炒飯店: – 阿三 / 炒飯 / 店 阿三 / 炒 / 飯店• 和英文不同,中文詞之間沒有空格,所以實現中文搜索引擎,比英文多了一項分詞的任務。• 如果沒有中文分詞會出現: – 搜索“達內”,會出現 ...
一、數據挖掘---中文分詞
• 一段文字不僅僅在於字面上是什麼,還在於怎麼切分和理解。
• 例如:
– 阿三炒飯店:
– 阿三 / 炒飯 / 店 阿三 / 炒 / 飯店
• 和英文不同,中文詞之間沒有空格,所以實現中文搜索引擎,比英文多了一項分
詞的任務。
• 如果沒有中文分詞會出現:
– 搜索“達內”,會出現“齊達內”相關的信息
• 要解決中文分詞準確度的問題,是否可以提供一個免費版本的通用分詞程式?
– 像分詞這種自然語言處理領域的問題,很難徹底完全解決
– 每個行業或業務側重不同,分詞工具設計策略也是不一樣的
二、切分方案

• 切開的開始位置對應位是1,否則對應位是0,來表示“有/意見/分歧”的bit內容是:11010
• 還可以用一個分詞節點序列來表示切分方案,例如“有/意見/分歧”的分詞節點序列是{0,1,3,5}
三、最常見的方法
• 最常見的分詞方法是基於詞典匹配
– 最大長度查找(前向查找,後向查找)
• 數據結構
– 為了提高查找效率,不要逐個匹配詞典中的詞
– 查找詞典所占的時間可能占總的分詞時間的1/3左右,為了保證切分速度,需要選擇一個好
的查找詞典方法
– Trie樹常用於加速分詞查找詞典問題
四、Trie樹

切分詞圖
五、概率語言模型
• 假設需要分出來的詞在語料庫和詞表中都存在,最簡單的方法是按詞計算概率,
而不是按字算概率。
• 從統計思想的角度來看,分詞問題的輸入是一個字串C=c1,c2……cn ,輸出是一
個詞串S=w1,w2……wm ,其中m<=n。對於一個特定的字元串C,會有多個切
分方案S對應,分詞的任務就是在這些S中找出一個切分方案S,使得P(S|C)的值
最大。
• P(S|C)就是由字元串C產生切分S的概率,也就是對輸入字元串切分出最有可能的
詞序列
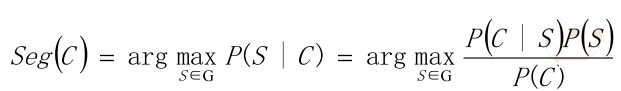
例子:
• 例如:對於輸入字元串C“南京市長江大橋”,有下麵兩種切分可能:
– S1:南京市 / 長江 / 大橋
– S2:南京 / 市長 / 江大橋
• 這兩種切分方法分別叫做S1和S2。計算條件概率P(S1|C)和P(S2|C),然後根據
P(S1|C)和P(S2|C)的值來決定選擇S1還是S2。
• P(C)是字串在語料庫中出現的概率。比如說語料庫中有1萬個句子,其中有一句
是 “南京市長江大橋”那麼P(C)=P(“南京市長江大橋”)=萬分之一。
• 因為P(C∩S) = P(S|C)*P(C) = P(C|S)*P(S),所以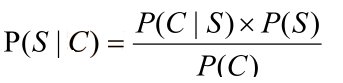
• 貝葉斯公式:

• P(C)只是一個用來歸一化的固定值
• 另外:從詞串恢復到漢字串的概率只有唯一的一種方式,所以P(C|S)=1。
• 所以:比較P(S1|C)和P(S2|C)的大小變成比較P(S1)和P(S2) 的大小
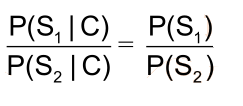
• 因為P(S1)=P(南京市,長江,大橋)=P(南京市)*P(長江)*P(大橋) > P(S2)=P(南京,市
長,江大橋),所以選擇切分方案S1
例子三:
• 為了容易實現,假設每個詞之間的概率是上下文無關的,則:

• 其中,P(w) 就是這個詞出現在語料庫中的概率。因為函數y=log(x),當x增大,
y也會增大,所以是單調遞增函數。∝是正比符號。因為詞的概率小於1,所以取
log後是負數。
• 最後算 logP(w)。取log是為了防止向下溢出,如果一個數太小,例如0.000000000000000000000000000001 可能會向下溢出。
• 如果這些對數值事前已經算出來了,則結果直接用加法就可以得到,而加法比乘法速度更快。
六、一元模型
• 對於不同的S,m的值是不一樣的,一般來說m越大,P(S)會越小。也就是說,分出的詞越多,概率越小。

七、N元模型
• 假設在日本,[和服]也是一個常見的詞。按照一元概率分詞,可能會把“產品和服務”分成[產品][和服][務]。為了切分更準確,要考慮詞所處的上下文。
• 給定一個詞,然後猜測下一個詞是什麼。當我說“NBA”這個詞時,你想到下
一個詞是什麼呢?我想大家有可能會想到“籃球”,基本上不會有人會想到“足
球”吧。
• 之前為了簡便,所以做了“前後兩詞出現概率是相互獨立的”的假設在實際中是
不成立的
• N元模型使用n個單片語成的序列來衡量切分方案的合理性:
• 估計單詞w1後出現w2的概率。根據條件概率的定義: 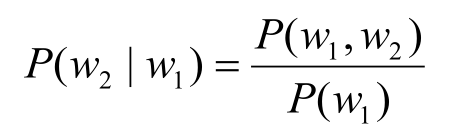
• 可以得到:P(w1,w2)= P(w1)P(w2|w1)
• 同理:P(w1,w2,w3)= P(w1,w2)P(w3|w1,w2)
• 所以有:P(w1,w2,w3)= P(w1)P(w2|w1)P(w3|w1,w2)
• 更加一般的形式:
• P(S)=P(w1,w2,...,wn)= P(w1)P(w2|w1)P(w3|w1,w2)…P(wn|w1w2…wn-1)
• 這叫做概率的鏈規則。
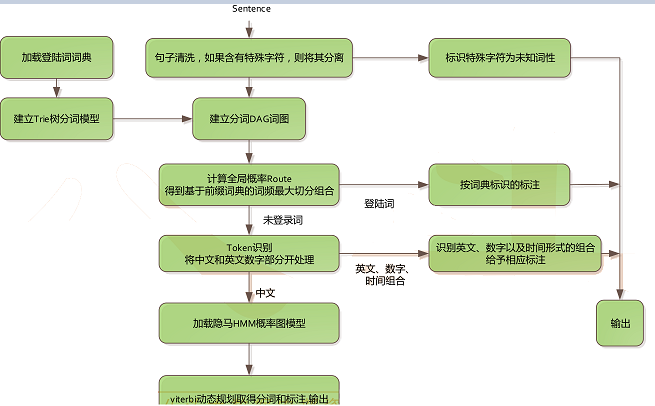
八、Jieba分詞簡介
• 源碼下載的地址:https://github.com/fxsjy/jieba
• 支持三種分詞模式
– 精確模式:將句子最精確的分開,適合文本分析
– 全模式:句子中所有可以成詞的詞語都掃描出來,速度快,不能解決歧義
– 搜索引擎模式:在精確模式基礎上,對長詞再次切分,提高召回
• 支持繁體分詞
• 支持自定義字典
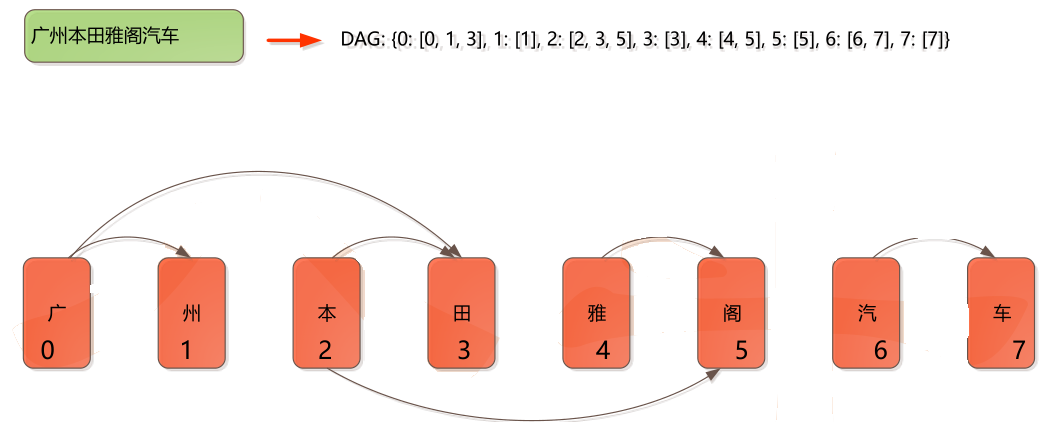
• 基於Trie樹結構實現高效的詞圖掃描,生成句子中漢字所有可能成詞情況所構成
的有向無環圖(DAG)
• 採用了動態規劃查找最大概率路徑, 找出基於詞頻的最大切分組合
• 對於未登錄詞,採用了基於漢字成詞能力的HMM模型,使用了Viterbi演算法
九、Jieba分詞細節