
前言 當共用變數被聲明為volatile後,對這個變數的讀/寫操作都會很特別,下麵我們就揭開volatile的神秘面紗。 1.volatile的記憶體語義 1.1 volatile的特性 一個volatile變數自身具有以下三個特性: 1. 可見性:即當一個線程修改了聲明為volatile變數的值,新 ...
前言
當共用變數被聲明為volatile後,對這個變數的讀/寫操作都會很特別,下麵我們就揭開volatile的神秘面紗。
1.volatile的記憶體語義
1.1 volatile的特性
一個volatile變數自身具有以下三個特性:
可見性:即當一個線程修改了聲明為volatile變數的值,新值對於其他要讀該變數的線程來說是立即可見的。而普通變數是不能做到這一點的,普通變數的值線上程間傳遞需要通過主記憶體來完成。
有序性:volatile變數的所謂有序性也就是被聲明為volatile的變數的臨界區代碼的執行是有順序的,即禁止指令重排序。
受限原子性:這裡volatile變數的原子性與synchronized的原子性是不同的,synchronized的原子性是指只要聲明為synchronized的方法或代碼塊兒在執行上就是原子操作的。而volatile是不修飾方法或代碼塊兒的,它用來修飾變數,對於單個volatile變數的讀/寫操作都具有原子性,但類似於volatile++這種複合操作不具有原子性。所以volatile的原子性是受限制的。並且在多線程環境中,volatile並不能保證原子性。
1.2 volatile寫-讀的記憶體語義
volatile寫的記憶體語義:當寫線程寫一個volatile變數時,JMM會把該線程對應的本地記憶體中的共用變數值刷新到主記憶體。
volatile讀的記憶體語義:當讀線程讀一個volatile變數時,JMM會把該線程對應的本地記憶體置為無效,線程接下來將從主記憶體讀取共用變數。
2.volatile語義實現原理
在介紹volatile語義實現原理之前,我們先來看兩個與CPU相關的專業術語:
- 記憶體屏障(memory barriers):一組處理器指令,用於實現對記憶體操作的順序限制。
- 緩存行(cache line):CPU高速緩存中可以分配的最小存儲單位。處理器填寫緩存行時會載入整個緩存行。
2.1 volatile可見性實現原理
volatile可見性的記憶體語義是如何實現的呢?下麵我們看一段代碼,並將代碼生成的處理器的彙編指令列印出來(關於如何列印彙編指令,我會在文章末尾附上),看下對volatile變數進行寫操作時,CPU會做什麼事情:
public class VolatileTest {
private static volatile VolatileTest instance = null;
private VolatileTest(){}
public static VolatileTest getInstance(){
if(instance == null){
instance = new VolatileTest();
}
return instance;
}
public static void main(String[] args) {
VolatileTest.getInstance();
}
}
以上的代碼是一個我們非常熟悉的在多線程環境中不能保證線程安全的單例模式代碼,這段代碼中特殊的地方是,我將實例變數instance加上了volatile修飾,下麵看列印的彙編指令:
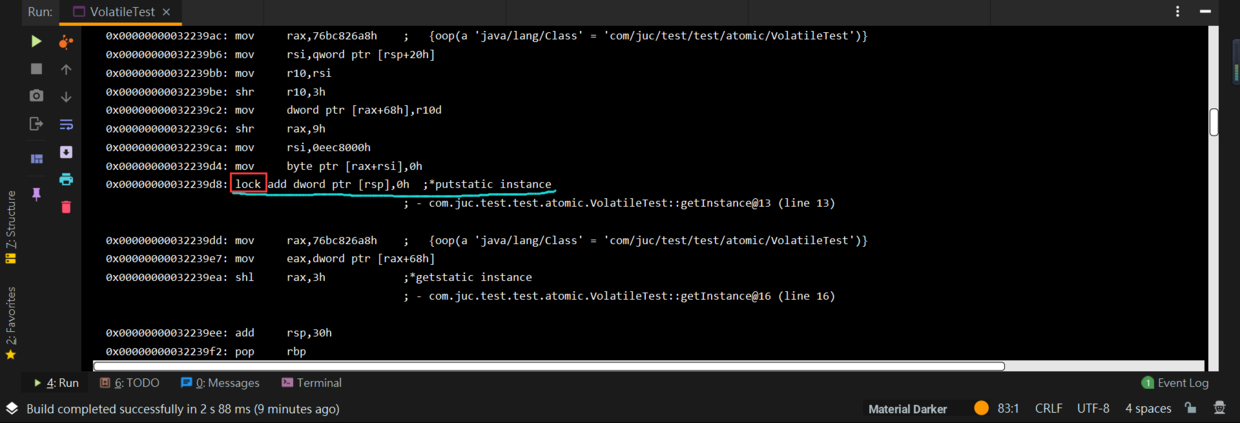
上面截圖中,我們看到我劃線的一行的末尾有一句彙編註釋:putstatic instance,瞭解JVM 位元組碼指令的小伙伴都知道,putstatic的含義是給一個靜態變數設置值,在上述代碼中也就是給靜態變數instance賦值,對應代碼:instance = new VolatileTest();在getInstance方法中為instance實例化,因為instance加了volatile修飾,所以給靜態變數instance設置值也是在寫一個volatile變數。
看到上述有彙編指令,也有位元組碼指令,大家會不會混淆這兩種指令,這裡我指明一下位元組碼指令和彙編指令的區別:
我們都知道java是一種跨平臺的語言,那麼java是如何實現這種平臺無關性的呢?這就需要我們瞭解JVM和java的位元組碼文件。這裡我們需要有一點共識,就是任何一門編程語言都需要轉換為與平臺相關的彙編指令才能夠最終被硬體執行,比如C和C++都將我們的源代碼直接編譯成與CPU相關的彙編指令給CPU執行。 不同系列的CPU的體系架構不同,所以它們的彙編指令也有不同,比如X86架構的CPU對應於X86彙編指令,arm架構的CPU對應於arm彙編指令。如果將程式源代碼直接編譯成與硬體相關的底層彙編指令,那麼程式的跨平臺性也就大打折扣,但執行性能相對較高。為了實現平臺無關性,java的編譯器javac並不是將java的源程式直接編譯成與平臺相關的彙編指令,而是編譯成一種中間語言,即java的class位元組碼文件。位元組碼文件,顧名思義存的就是位元組碼,即一個一個的位元組。有打開過java位元組碼文件研讀過的小伙伴可能會發現,位元組碼文件裡面存的並不是二進位,而是十六進位,這是因為二進位太長了,一個位元組要由8位二進位組成。所以用十六進位標表示,兩個十六進位就可以表示一個位元組。java源碼編譯後的位元組碼文件是不能夠直接被CPU執行的,那麼該如何執行呢?答案是JVM,為了讓java程式能夠在不同的平臺上執行,java官方提供了針對於各個平臺的java虛擬機,JVM運行於硬體層之上,屏蔽各種平臺的差異性。javac編譯後的位元組碼文件統一由JVM來載入,最後再轉化成與硬體相關的機器指令被CPU執行。知道了通過JVM來載入位元組碼文件,那麼還有一個問題,就是JVM如何將位元組碼中的每個位元組和我們寫的java源代碼相關聯,也就是JVM如何知道我們寫的java源代碼對應於class文件中的哪段十六進位,這段十六進位是乾什麼的,執行了什麼功能?並且一大堆的十六進位,我們也看不懂啊。所以這就需要定義一個JVM層面的規範,在JVM層面抽象出一些我們能夠認識的指令助記符,這些指令助記符就是java的位元組碼指令。
再看上面的截圖,當寫instance這個volatile變數時,發現add前面加個一個lock指令,我在截圖中框了出來,如何不加volatile修飾,是沒有lock的。
lock指令在多核處理器下會引發下麵的事件:
將當前處理器的緩存行的數據寫回到系統記憶體,同時使其他CPU里緩存了該記憶體地址的數據置為無效。
為了提高處理速度,處理器一般不直接和記憶體通信,而是先將系統記憶體的數據讀到內部緩存後再進行操作,但操作完成後並不知道處理器何時將緩存數據寫回到記憶體。但如果對加了volatile修飾的變數進行寫操作,JVM就會向處理器發送一條lock首碼的指令,將這個變數在緩存行的數據寫回到系統記憶體。這時只是寫回到系統記憶體,但其他處理器的緩存行中的數據還是舊的,要使其他處理器緩存行的數據也是新寫回的系統記憶體的數據,就需要實現緩存一致性協議。即在一個處理器將自己緩存行的數據寫回到系統記憶體後,其他的每個處理器就會通過嗅探在匯流排上傳播的數據來檢查自己緩存的數據是否已過期,當處理器發現自己緩存行對應的記憶體地址的數據被修改後,就會將自己緩存行緩存的數據設置為無效,當處理器要對這個數據進行修改操作的時候,會重新從系統記憶體中把數據讀取到自己的緩存行,重新緩存。
總結下:volatile可見性的實現就是藉助了CPU的lock指令,通過在寫volatile的機器指令前加上lock首碼,使寫volatile具有以下兩個原則:
- 寫volatile時處理器會將緩存寫回到主記憶體。
- 一個處理器的緩存寫回到記憶體會導致其他處理器的緩存失效。
2.2 volatile有序性的實現原理
volatile有序性的保證就是通過禁止指令重排序來實現的。指令重排序包括編譯器和處理器重排序,JMM會分別限制這兩種指令重排序。
那麼禁止指令重排序又是如何實現的呢?答案是加記憶體屏障。JMM為volatile加記憶體屏障有以下4種情況:
- 在每個volatile寫操作的前面插入一個StoreStore屏障,防止寫volatile與後面的寫操作重排序。
- 在每個volatile寫操作的後面插入一個StoreLoad屏障,防止寫volatile與後面的讀操作重排序。
- 在每個volatile讀操作的後面插入一個LoadLoad屏障,防止讀volatile與後面的讀操作重排序。
- 在每個volatile讀操作的後面插入一個LoadStore屏障,防止讀volatile與後面的寫操作重排序。
上述記憶體屏障的插入策略是非常保守的,比如一個volatile的寫操作後面需要加上StoreStore和StoreLoad屏障,但這個寫volatile後面可能並沒有讀操作,因此理論上只加上StoreStore屏障就可以,的確,有的處理器就是這麼做的。但JMM這種保守的記憶體屏障插入策略能夠保證在任意的處理器平臺,volatile變數都是有序的。
3.JSR-133對volatile記憶體語義的增強
在JSR-133之前的舊的java記憶體模型中,雖然不允許對volatile變數之間的操作進行重排序,但允許對volatile變數與普通變數之間進行重排序。比如記憶體屏障前面是一個寫volatile變數的操作,記憶體屏障後面的操作是一個寫普通變數的操作,即使這兩個寫操作可能會破壞volatile記憶體語義,但JMM是允許這兩個操作進行重排序的。
在JSR-133以及後面的新的java記憶體模型中,增強了volatile的記憶體語義。只要volatile變數與普通變數之間的重排序可能會破壞volatile的記憶體語義,這種重排序就會被編譯器重排序規則和處理器記憶體屏障出入策略禁止。
附:配置idea列印彙編指令
工具包下載地址:鏈接:https://pan.baidu.com/s/11yRnsOHca5EVRfE9gAuVxA
提取碼:gn8z
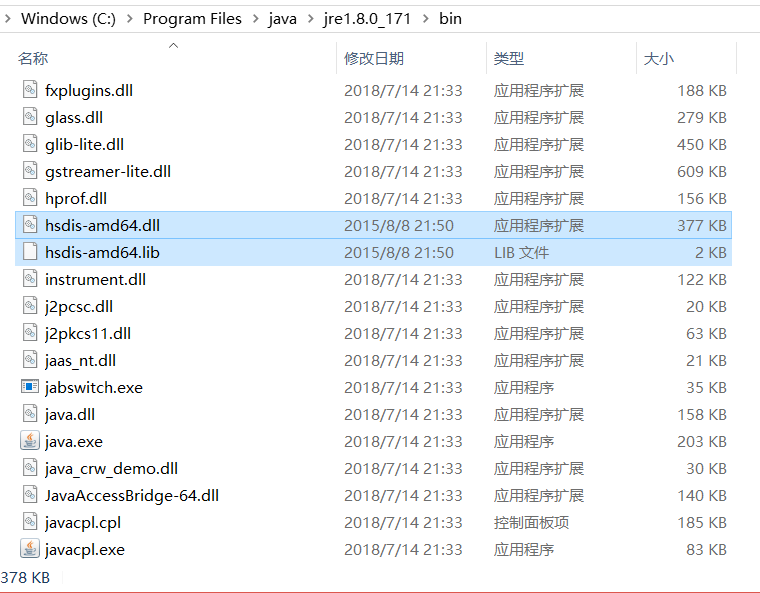
將下載的工具包解壓,複製到jdk安裝目錄的jre路徑下的bin目錄中,如圖:
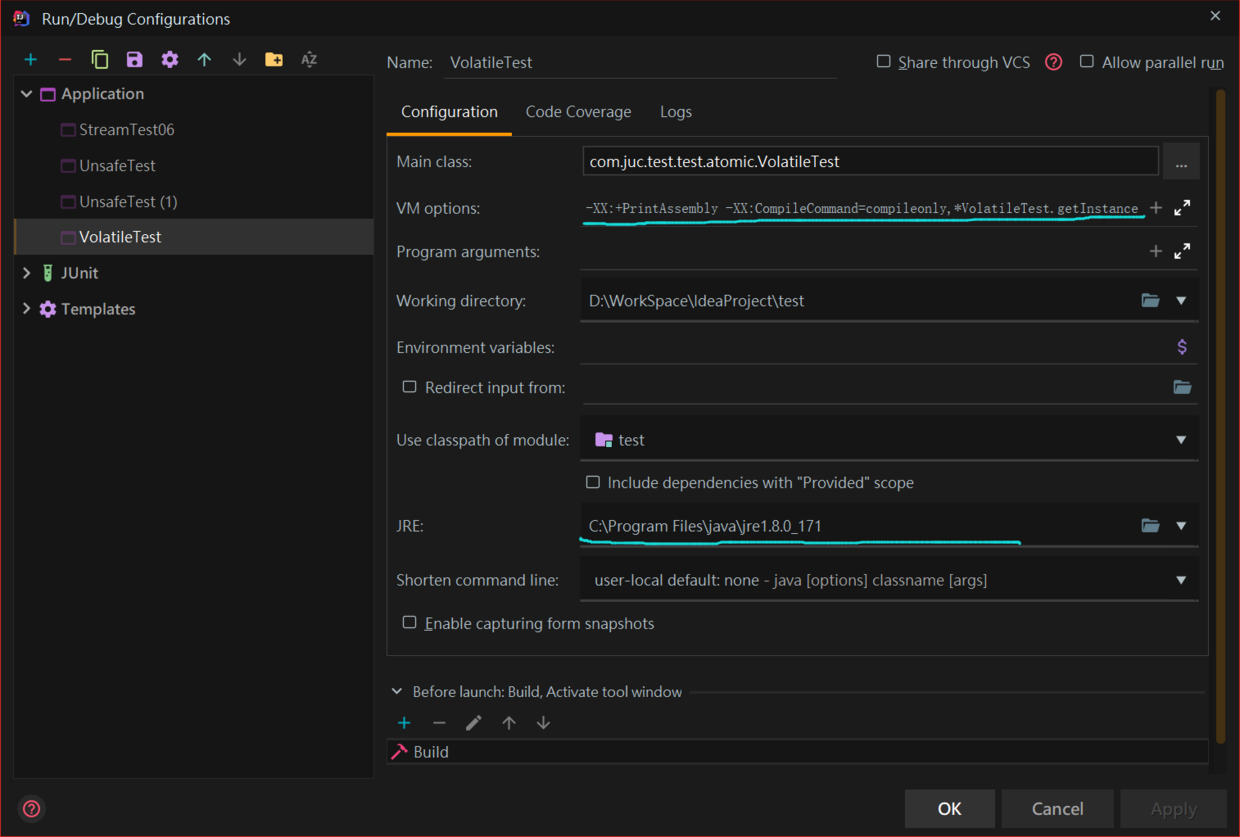
然後配置idea,在 VM options 選項中輸入:-server -Xcomp -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -XX:CompileCommand=compileonly,*類名.方法名
JRE選項選擇已放入工具包的jre路徑。
下圖是我的idea配置:
以上配置好後運行就可以列印彙編指令了。


