
RDMA (Remote Direct Memory Access) 全稱為 遠程直接記憶體訪問 其出現的目的:為瞭解決網路傳輸中服務端數據處理的延遲而產生的。其將數據直接從一臺電腦的記憶體傳輸到另一臺電腦,無需雙方操作系統的介入。這允許高吞吐、低延遲的網路通信,尤其適合在大規模並行電腦集群中使用 ...
RDMA (Remote Direct Memory Access) 全稱為 遠程直接記憶體訪問
其出現的目的:為瞭解決網路傳輸中服務端數據處理的延遲而產生的。其將數據直接從一臺電腦的記憶體傳輸到另一臺電腦,無需雙方操作系統的介入。這允許高吞吐、低延遲的網路通信,尤其適合在大規模並行電腦集群中使用。RDMA通過網路把資料直接傳入電腦的存儲區,將數據從一個系統快速移動到遠程系統存儲器中,而不對操作系統造成任何影響,這樣就不需要用到多少電腦的處理能力。它消除了外部存儲器複製和上下文切換的開銷,因而能解放記憶體帶寬和CPU周期用於改進應用系統性能。
RDMA三大特性:CPU offload 、kernel bypass、zero-copy。
RDMA提供了基於消息隊列的點對點通信,每個應用都可以直接獲取自己的消息,無需OS和協議棧的介入。
調用棧:
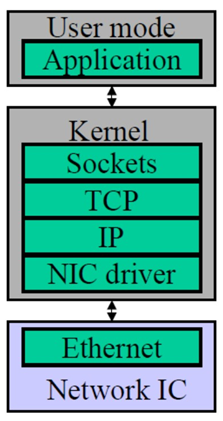
傳統tcp/ip數據流動方式:
進程 buffer (用戶空間)-> socket buffer(內核空間) -> 添加包頭(內核空間)-> NIC buffer (網卡設備)-> 網路->接收端反向解析<--
特點:各層次分工完善,但是數據在傳輸過程中出現多次拷貝;產生延遲較高,也一定程度上浪費了記憶體和計算資源;
網路測試的五項指標:
- 可用性(availability):可使用ping 命令測試網路是否通暢;
- 響應時間(response time):ping 命令echo request/reply 一次往返所花費的時間;
- 網路利用率(network utilization):指的是網路使用時間和空閑時間的比例;
- 網路吞吐量(network throughput):在網路中兩個節點之間,提供給網路應用的剩餘帶寬,測試網路吞吐的時候,需要在一天的不同時刻來進行測量;
- 網路帶寬容量(network bandwidth capacity):與吞吐不同,網路帶寬容量指的是在網路兩個節點之間的最大可用帶寬。該值是由網路設備本身的能力決定的。
其中兩個最重要的指標是高帶寬和低延遲。
通信延遲 =傳輸延遲 + 處理延遲;
處理延遲:發生在消息的發送端和消息的接收端; 傳輸延遲:發生在消息在發送方和接收方之間網路上;
通信過程中處理開銷主要指:buffer 管理,不同空間的消息複製,消息發送和接收過程中系統的中斷;
網路中傳播的消息的種類:
Large Messages: 此類消息可以理解為:傳輸大塊文件數據;此類模式中,網路傳輸延遲占整個通信中的主導地位;
Small Messages: 此類消息可以理解為:傳輸文件元數據信息;此類模式中,處理延遲在整個通信過程中的主導地位;
傳統TCP/IP存在的問題:
傳統的TCP/IP的問題,主要是IO瓶頸,在高速網路條件下與網路I/O相關的主機處理的高開銷限制了可以在機器之間發送的帶寬。由上面的數據流動方式,我們可以看到,這裡的高開銷主要是數據移動和複製操作;主要是傳統的TCP/IP網路通信是通過內核發送消息。Messaging passing through kernel這種方式會導致很低的性能和很低的靈活性。性能低下的原因主要是由於網路通信通過內核傳遞,這種通信方式存在的很高的數據移動和數據複製的開銷。並且現如今記憶體帶寬性相較如CPU帶寬和網路帶寬有著很大的差異。很低的靈活性的原因主要是所有網路通信協議通過內核傳遞,這種方式很難去支持新的網路協議和新的消息通信協議和發送、接收介面。
高性能網路通信相關研究:
- TCP Offloading Engine(TOE):將加解包的工作下移到網卡上,需要特定網卡支持;
- User-Net Networking(U-Net):將整個協議棧移動到用戶空間中,從數據通信路徑中,徹底刪除內核,帶來高性能和高靈活性的提升;
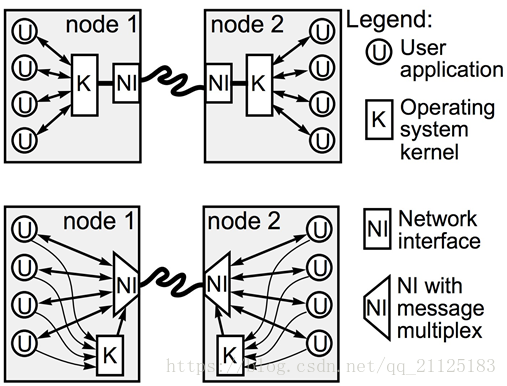
內核介面只涉及到連接步驟,在傳輸過程中,減少了數據在用戶空間和內核空間的複製;
- Virtual interface Architecture(VIA):VIA 通過為每個應用進程提供受保護的,對網路硬體進行存取的介面-Virtual Interface,從而消除了傳統模式下的系統處理開銷;
- Remote Direct Memroy Access(RDMA)
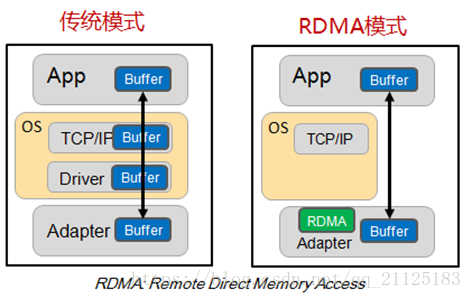
RDMA 通過網路,把數據資料,直接傳入電腦的存儲區,消除了存儲器件的賦值和上下文切換開銷;其有低延遲,低CPU負載和高帶寬三種特性;
RDMA 操作:
應用和RNIC之間的傳輸介面層(software transport interface)被稱為Verbs。
Memory verbs: RDMA read、write 和 atomic 操作。這些操作指定遠程地址進行操作並繞過接收者的CPU; (單邊操作,應用無感知)
Messaging verbs: 包括RDMA send、receive 操作。動作涉及到響應者的CPU,發送的數據被寫入到由響應者CPU先前發佈的接收所指定的地址;(雙邊操作,需應用感知)
send/receive 多用於連接控制類報文,而數據報文多是通過READ/WRITE 來完成的。雙邊操作與傳統網路的底層Buffer Pool 類似,雙方參與的過程並無差別。主要區別在於RDMA的零拷貝和Kernel Bypass。對於RDMA 這是一種負載的消息傳輸模式,多用於傳輸短的控制消息;

RC 表示可靠連接;UC 表示不可靠連接;UD 表示不可靠的數據報,不支持memory verbs;
RDMA 實現:
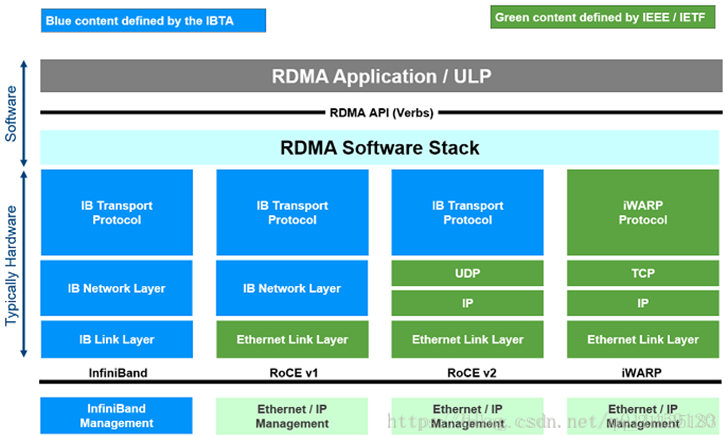
RDMA 目前有三種不同實現:InfiniBand,iWarp(internet Wide Area RDMA Protocol),RoCE(RDMA over Converged Ethernet);
Infiniband是一種專為RDMA設計的網路,從硬體級別保證可靠傳輸 , 而RoCE 和 iWARP都是基於乙太網的RDMA技術,支持相應的verbs介面。從圖中不難發現,RoCE協議存在RoCEv1和RoCEv2兩個版本,主要區別RoCEv1是基於乙太網鏈路層實現的RDMA協議(交換機需要支持PFC等流控技術,在物理層保證可靠傳輸),而RoCEv2是乙太網TCP/IP協議中UDP層實現。從性能上,很明顯Infiniband網路最好,但網卡和交換機是價格也很高,然而RoCEv2和iWARP僅需使用特殊的網卡就可以了,價格也相對便宜很多。
Infiniband:支持RDMA的新一代網路協議。 由於這是一種新的網路技術,因此需要支持該技術的NIC和交換機。
RoCE:允許在乙太網上執行RDMA的網路協議。 其較低的網路標頭是乙太網標頭,其較高的網路標頭(包括數據)是InfiniBand標頭。 這支持在標準乙太網基礎設施(交換機)上使用RDMA。 只有網卡應該是特殊的,支持RoCE。
iWARP:一個允許在TCP上執行RDMA的網路協議。 IB和RoCE中存在的功能在iWARP中不受支持。 這支持在標準乙太網基礎設施(交換機)上使用RDMA。 只有網卡應該是特殊的,並且支持iWARP(如果使用CPU卸載),否則所有iWARP堆棧都可以在SW中實現,並且喪失了大部分RDMA性能優勢。
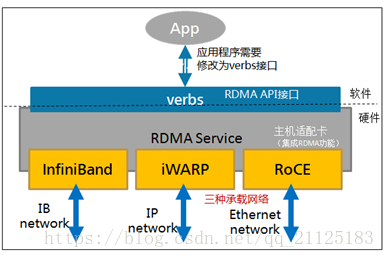
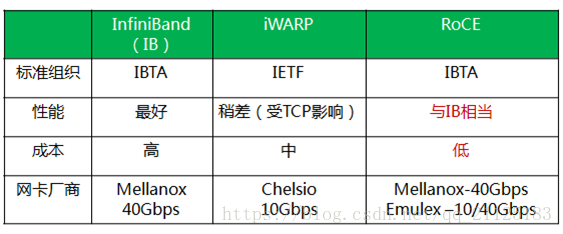
RDMA 結構圖:
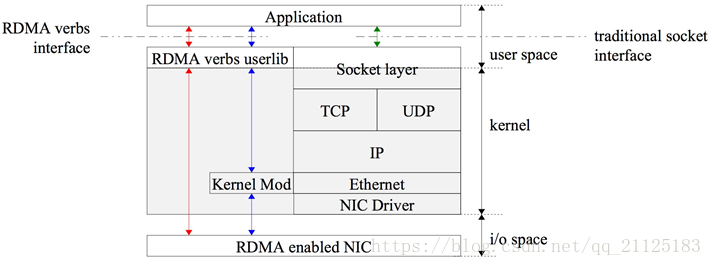

RDMA工作過程:
- 應用執行RDMA讀寫請求的時候,不需要內核記憶體參與,RDMA 請求直接從用戶空間的應用發送到本地NIC(網卡);
- NIC 讀取緩衝區內容,並通過網路傳送到遠程NIC;
- 在網路上傳輸的RDMA信息,包含目標虛擬地址,記憶體鑰匙和數據本身;請求既可以完全在用戶空間中處理(使用主動輪詢機制),又可以在應用一直睡眠到請求完成時的情況下,通過系統中斷處理。RDMA操作使得應用可以從一個遠程應用的記憶體中(遠程應用的虛擬記憶體)讀取數據或者向這個記憶體中寫數據;
- 目標NIC確認記憶體鑰匙(key),直接將數據寫入應用緩存中。用於操作的遠程虛擬記憶體地址包含在RDMA信息中;
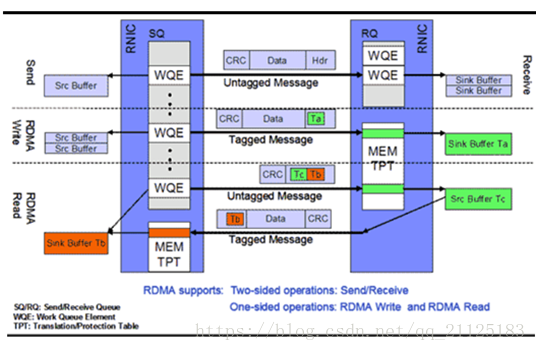
RMDA 中專有名詞和對應縮寫:
Channel-IO:RDMA 在本端應用和遠端應用間創建的一個消息通道;
Queue Pairs(QP):每個消息通道兩端是兩對QP;
Send Queue(SQ): 發送隊列,隊列中的內容為WQE;
Receive Queue(RQ):接收隊列,隊列中的內容為WQE;
Work Queue Element(WQE):工作隊列元素,WQE指向一塊用於存儲數據的Buffer;
Work Queue(WQ): 工作隊列,在發送過程中 WQ = SQ; 在接收過程中WQ = WQ;
Complete Queue(CQ): 完成隊列,CQ用於告訴用戶WQ上的消息已經被處理完成;
Work Request(WR):傳輸請求,WR描述了應用希望傳輸到Channel對端的消息內容,在WQ中轉化為 WQE 格式的信息;
參考鏈接:
https://blog.csdn.net/qq_21125183/article/details/80563463
保持更新,資源來源於對網上資料總結,如果對您有幫助,請關註 cnblogs.com/xuyaowen .


