
上一篇文章咱們說了一條查詢sql的執行過程。如果沒有看過上一篇文章的可以去看下上一篇文章,今天咱們說說一條更新sql的執行過程。 上面一條sql是將id為1的分數加上10。 那麼它的執行流程是怎樣的呢?借用上篇文章的圖,如下: 我這邊就再簡單的說一下這個流程,首先客戶端連接mysql伺服器,連接後執 ...
上一篇文章咱們說了一條查詢sql的執行過程。如果沒有看過上一篇文章的可以去看下上一篇文章,今天咱們說說一條更新sql的執行過程。
update scores set score=c+10 where id=1
上面一條sql是將id為1的分數加上10。
那麼它的執行流程是怎樣的呢?借用上篇文章的圖,如下:
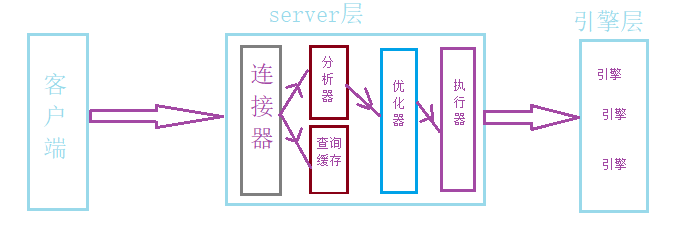
我這邊就再簡單的說一下這個流程,首先客戶端連接mysql伺服器,連接後執行sql語句,執行sql的過程需要經過分析器得出它是需要做update操作,再接著經過優化器它決定使用id這個索引,然後經過執行器通過索引找到這一行,最後進行更新操作。
以上就是整個更新操作得整個流程。說到這你肯定以為說完了,不過很遺憾的告訴你,這才剛剛開始呢。
因為更新操作和查詢操作不一樣,更新操作涉及到兩個非常重要的日誌模塊。redo log (重做日誌) 和 bin log(歸檔日誌)。這個兩個才是今天要說的重點。
首先咱們得知道這兩個日誌是什麼?然後再得知道它們是乾什麼的?
redo log 是 InnoDB 引擎特有,它是屬於物理日誌,主要用於記錄 “某個數據頁上做了什麼修改” ,而且它的記錄空間是固定的並且是會用完的。
bin log 是屬於 server 層持有的,主要是再執行器中記錄日誌,所以mysql所有的引擎都可以使用它。bin log 是屬於邏輯日誌,它有 statement 和 row 兩種模式,statement記錄的是執行的sql語句,row記錄的是更新行的內容,所以是記錄兩條,一條是更新前的內容,另外一條是更新後的內容。預設模式是 row 模式。另外 bin log 是會追加寫入日誌,當日誌文件寫到一定大小的時候,就會切換到下一個繼續寫入日誌,並且不會覆蓋之前的日誌文件。
以上就是這兩種日誌的概念以及作用,那麼現在我們說說它們的記錄流程。咱們先看下麵一張圖,黃填充色的為執行器的操作,藍填充色為InnoDB引擎的操作
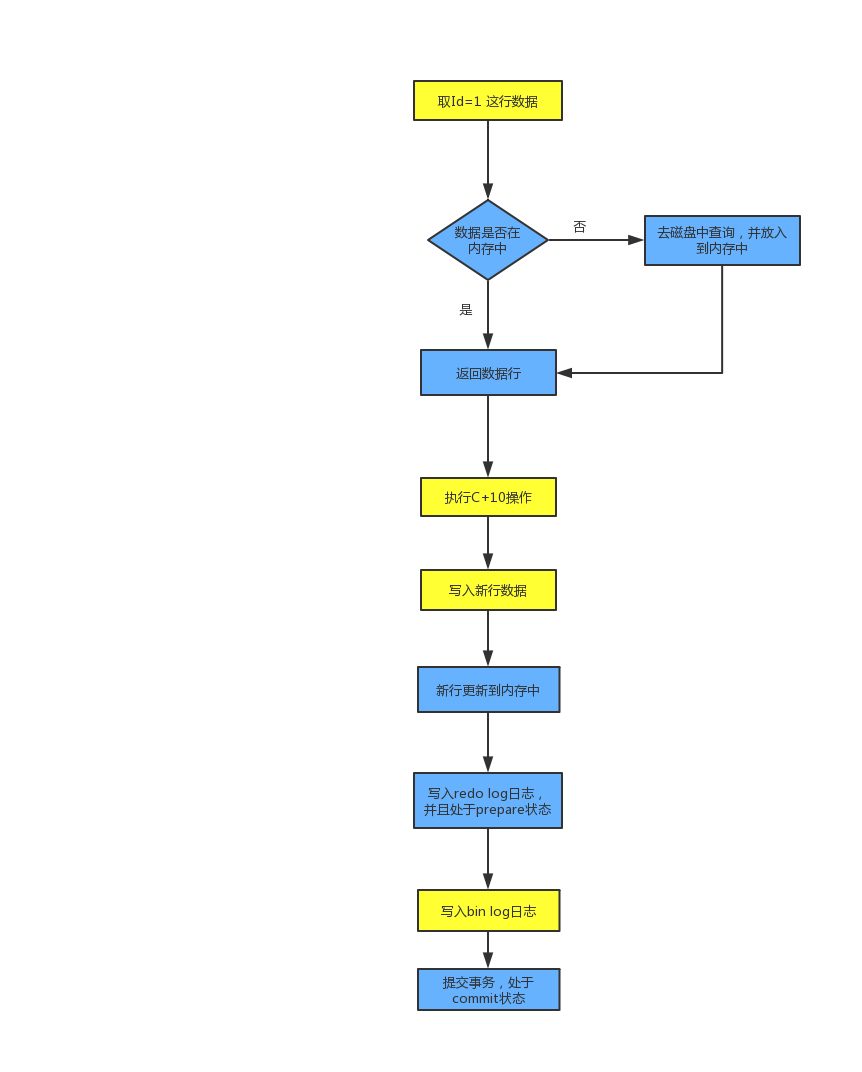
圖有點長,不過應該很容易看懂。那麼現在就來一步一步的分析。
1、首先執行器會找引擎取id=1這條數據;
2、因為id是主鍵,所以使用樹來找到一行數據。不過引擎先去記憶體中查找是否有這一頁數據;
3、如果有則直接返回數據給執行器;如果沒有就會去磁碟把數據讀入到記憶體中,然後返回數據給執行器。
4、執行器就會執行C+10操作;
5、執行器生成新的一行數據;
6、再調用 InnoDB 引擎的寫入介面,把數據更新到記憶體中;
7、InnoDB 引擎寫入 redo log 日誌,標記狀態為 prepare,並且告訴執行器已經更新數據完成,可以隨時提交事務;
8、執行器把此操作寫入 bin log ,並且把 bin log 寫入磁碟;
9、最後執行器調用引擎的提交事務介面,引擎把 redo log 的狀態改 commit ,至此整個更新操作完成。
看到這裡也許你會冒出幾個問題?
1、redo log 空間是固定,那它會不會用完呢?
首先不用擔心 redo log 會用完空間,因為它是迴圈利用的。例如 redo log 日誌配置為一組4個文件,每個文件分別為1G。它寫的流程如下圖:

上圖中有兩塊填充色,黃色和紅色,黃色標記著 check point,這表示這當前擦除掉 redo log 的位置,紅色標記著 write pos ,這表示著當前記錄 redo log 的位置。當 redo log 寫滿了之後,就會停下來,不再寫入數據,會執行擦除 redo log 操作,當然在擦除這些日誌之前,都會把數據寫入到磁碟中,把數據進行持久化。這樣才能保住數據的準確性。
2、為什麼要用這兩種日誌呢?因為在沒有 InnoDB 引擎的時候是沒有 redo log 日誌的。
因為 InnoDB 引擎的 redo log 可以保證即使資料庫突然宕機了或者異常重啟了,之前提交的數據是不會丟失的。這個能力咱們稱之為 crash-safe。
3、當mysql伺服器在執行過程中突然間宕機了,數據會不會丟失?
答案是不會。為什麼這麼肯定呢?我們可以從第二張圖就可以看出來。比如有以下幾種情況:
1、寫入 redo log 之前宕機了,那麼原始數據是不會發送改變的,因為還沒有進行事務的提交。
2、如果寫入 redo log 之後,寫入 bin log之前宕機,那麼原始數據還是不會變,因為資料庫重啟後,因為兩種日誌的記錄沒有同步,所以不會有新數據生成。
3、在 redo log 生成commit之前宕機了,資料庫重啟後 數據會變成更新後的數據,因為這個時候 redo log 和 bin log 都有了記錄,所以資料庫重啟後會自己進行commit,所以這時候的數據就是更新後的數據了。
我們使用 redo log 主要是需要保證 crash-safe 能力,innodb_flush_log_at_trx_commit這個參數設置成1的時候,表示每次事務的redo log都直接持久化到磁碟。這個參數我建議你設置成1,這樣可以保證MySQL異常重啟之後數據不丟失。
sync_binlog這個參數設置成1的時候,表示每次事務的binlog都持久化到磁碟。這個參數我也建議你設置成1,這樣可以保證MySQL異常重啟之後binlog不丟失。
好了,今天就說到這裡,如果寫的有誤的地方歡迎大家指出,咱們一起討論學習。

