
最近項目上遇到好幾個崩潰問題,解決過程有點曲折,在此記做個記錄。 項目背景介紹:該項目為語音識別實時分析系統,整套系統架構如下: 接連幾次崩潰的是中間的語音流接入系統,崩潰的情況如下: 1、打開文件過多報錯,導致系統直接卡死。 2、打開線程過多,導致系統直接崩潰。 3、Jetty容器非同步支持bug。 ...
最近項目上遇到好幾個崩潰問題,解決過程有點曲折,在此記做個記錄。
項目背景介紹:該項目為語音識別實時分析系統,整套系統架構如下:
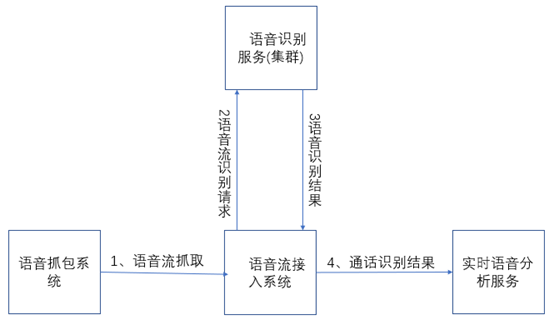
接連幾次崩潰的是中間的語音流接入系統,崩潰的情況如下:
1、打開文件過多報錯,導致系統直接卡死。
2、打開線程過多,導致系統直接崩潰。
3、Jetty容器非同步支持bug。
第一次崩潰:打開文件過多
首先在日誌中大量的刷屏,因為我們的語音流接入系統只是一個中間轉發的服務,這個服務當時是從實時語音分析服務中剝離出來的,當時剝離出來的主要目的是降低實時語音分析服務的帶寬壓力,所以當出現這個問題後,直接指向的是有網路連接沒有釋放。
既然確定了排查方向,使用lsof命令,好家伙,該進程直接占了六萬多個文件句柄,其中eventpoll占了一萬六千多個,打開的pipe有三萬三千多個,就這兩項就占了近五萬個句柄。項目上部署的這套系統最高併發為預計的3000路通話,即使在最高通話併發的情況下,也不可能占用這麼多句柄數,所以情況就是有連接沒有釋放,導致句柄泄漏,並逐漸累積到這個數目,驗證這個情況,使用netstat,果然發現大量的連接一直沒有釋放。
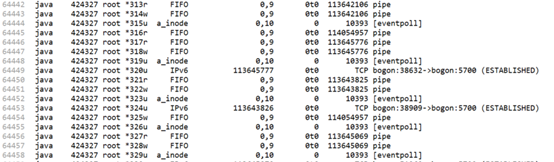
好了,鎖定了目標,接下來就是排查代碼中沒有正確釋放的地方。
如最上,一通新通話進來時,我們的語音流接入系統會接入兩個語音流併發送給語音識別服務進行識別,在這個過程中,語音流發送是一個持續的過程,並且我們要確保同一個語音流由同一臺機器進行識別。所以在新語音流進來時,我們的接入系統與識別服務之間會創建一個session,當通話結束時銷毀這個session,這個session在我們的語音流接入系統(以下簡稱接入系統)中是和語音流ID即streamId一一對應的,在一個流推送結束後我們要根據streamId進行session的關閉。結果在代碼中有一個地方,本來應該是傳streamId的,但是結果卻傳成了toString(這個錯誤很低級!),好了,找到這個地方修改後,項目重新上線。(可是幸福不會來的這樣突然!)
第二次崩潰:打開線程過多
當上面以為問題解決後,第二天線上直接報出進程崩潰的問題,查看崩潰日誌,裡面大量的線程阻塞,一個進程居然有三萬個線程。
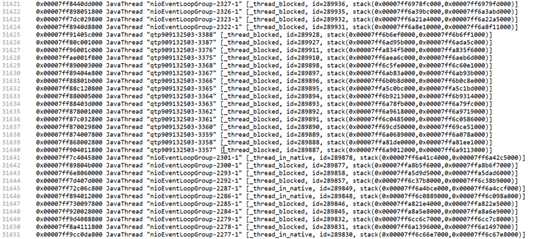
遇到這個情況也只能結合代碼去分析這些線程是在哪裡起的了。因為這個接入系統只是一個中間商,所以起線程的地方只有三個,一個是接入語音流的地方,一個是接收識別結果的地方,剩下的就是推送識別結果。查看語音抓包系統併發數正常,而識別結果推送是同步的,但是我們在接收識別結果的時候採用的是非同步介面,而每收到一個識別結果的時候都會當作一個任務加入線程池等待執行。那麼這時,積壓只能是在接收識別結果這裡了。(說明:在前面通過打時間戳的方式已經確認過了接入系統和分析服務之間發送和接收速度不一致,因為分析服務拿到識別結果後還會有後續的模型、流程分析處理,所以這就是一個典型的快生產者慢消費者問題。)
針對上面的分析結果,確認是消費者過慢問題,那麼快生產者就應該進行控制,查看代碼,發現在處理接收的識別結果的時候,我們使用的線程池是newCachedThreadPool,所以因為這個原因,當分析服務這邊接收過慢時,接入系統在接收識別服務的識別結果時就只能創建大量的線程去等待執行。針對這個情況,所以改為使用newFixedThreadPool。(還有就是如果消費者過慢的話,提高消費者處理能力才是正解,所以後面也有對分析服務的優化,提高響應時間。)
所以在使用生產者消費者模型的時候,可以有快生產者慢消費者存在,但是兩者之間的處理速度不應該相差過大,更不能說是沒有消費者(當分析服務崩潰或者阻塞就是這種情況。)
第三次崩潰:Jetty容器非同步支持bug
再經過上面兩次bug修複後,以為問題徹底解決了,但是還是同樣的到項目上跑上一天後,又出現了崩潰問題。對於這一次從日誌裡面分析,還是文件句柄占用耗盡而崩潰,分析這些鏈接,發現還是我們的接入系統和識別服務之間有大量的連接沒有釋放。這讓人很疑惑,經過最終的確認,所有的連接之間都有得到正確的釋放。然後註意到了之前一直被忽略的一條錯誤日誌:
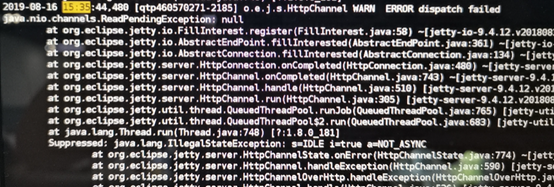
最終確認jetty容器在拋出該異常後,會導致非同步回調永遠得不到調用,這樣的話就會使得我們的接入系統和識別服務之間的連接可能因為非同步回調沒有得到調用而導致連接得不到釋放。(當時使用的jetty版本是9.4.12)
線上的每一次崩潰都讓我的小心臟跳動加速一倍,活著不易,且行且珍惜!


