
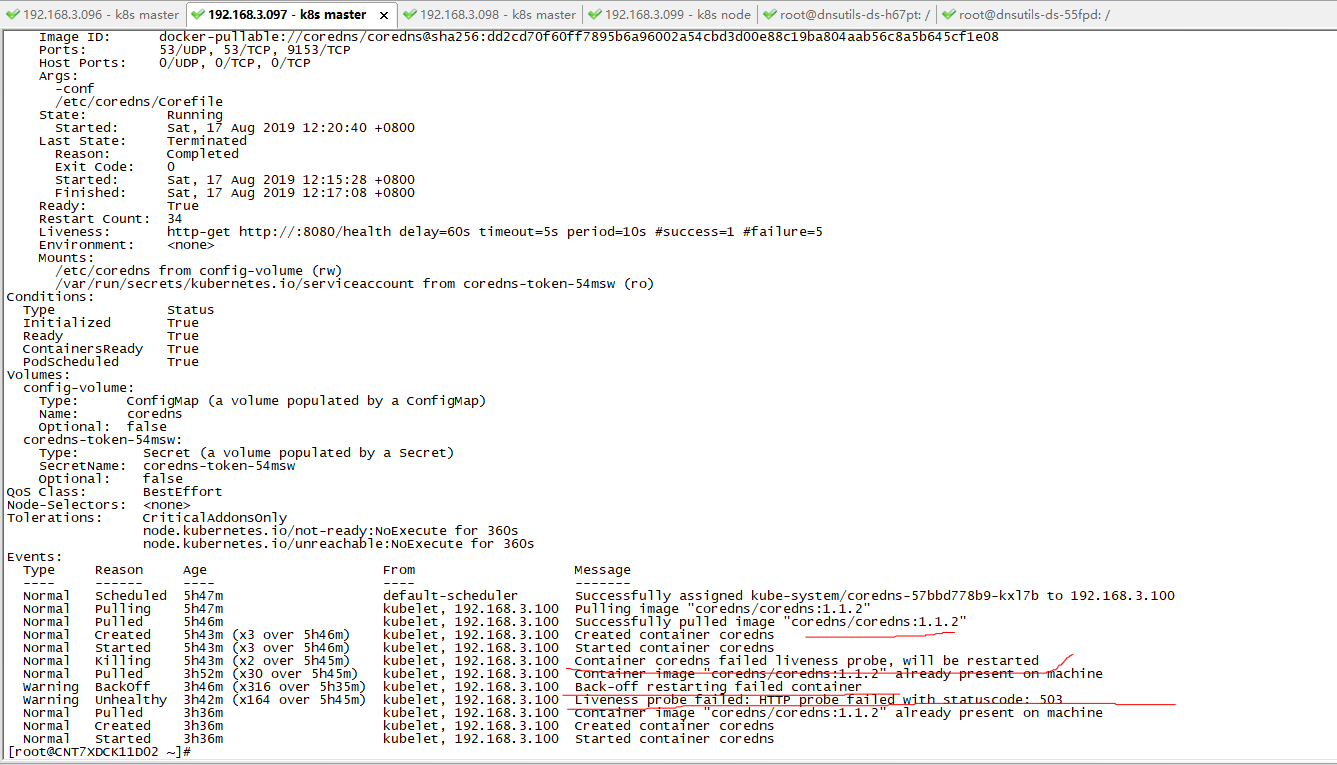
1. 查詢k8s集群部署pod的基本情況 如下圖,我們可知容器coredns和dnsutils都部署成功,但是由於功能變數名稱解析的問題,導致coredns和dnsutils的容器不斷重啟(原因heath檢查,無法請求成功,被kubelet重啟了pod) 命令如下: root >> kubectl get ...
1. 查詢k8s集群部署pod的基本情況
如下圖,我們可知容器coredns和dnsutils都部署成功,但是由於功能變數名稱解析的問題,導致coredns和dnsutils的容器不斷重啟(原因heath檢查,無法請求成功,被kubelet重啟了pod)
命令如下:
root >> kubectl get all --all-namespaces -o wide
root >> kubectl describe pod coredns-57bbd778b9-kxl7b -n kube-system
root >> kubectl logs coredns-57bbd778b9-kxl7b -n kube-system

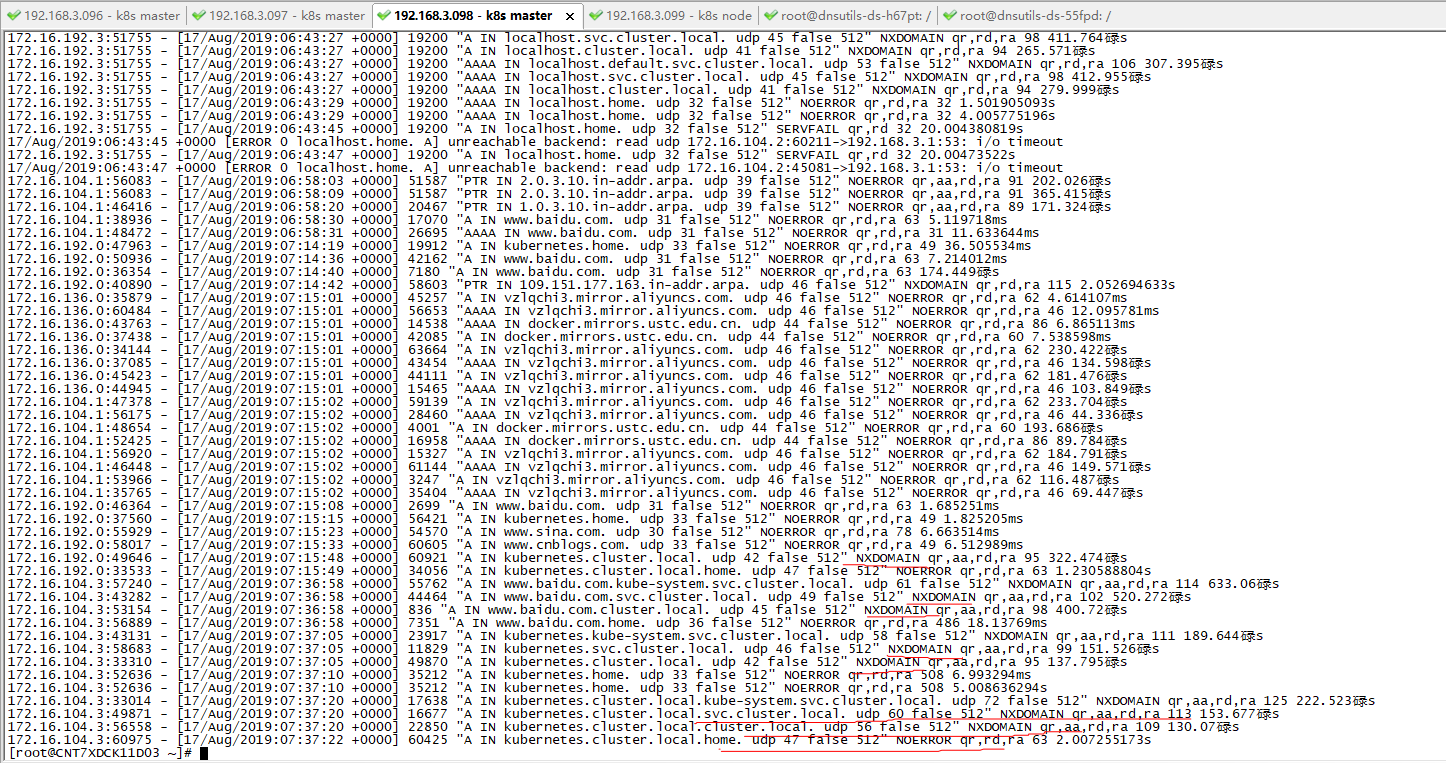
2. 修改VM的DNS解析文件之前,
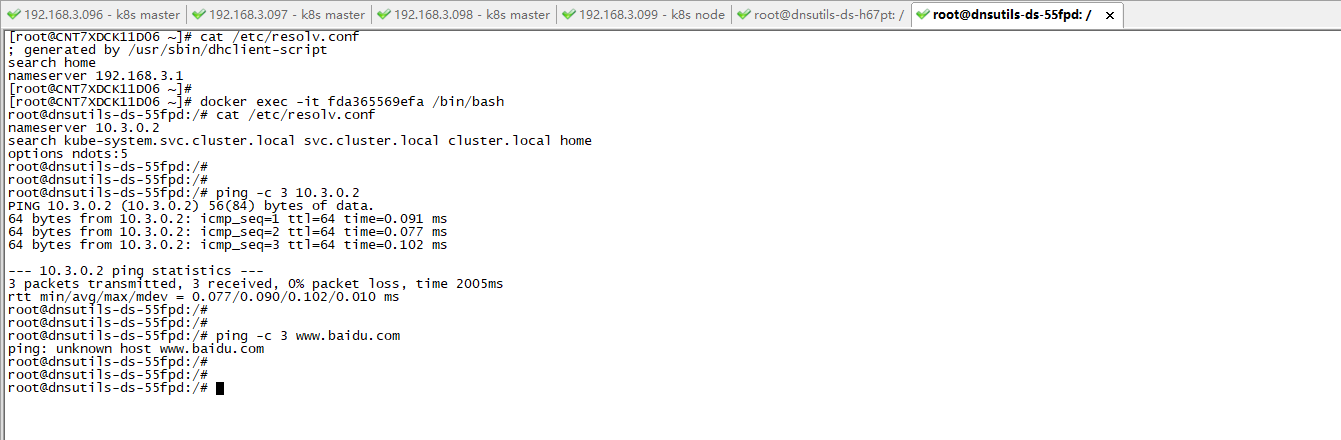
如下圖:cat /etc/resolv.conf 中192.168.3.1是我VM物理機的網卡設置的DNS名稱,這個是一個虛擬的錯誤的DNS地址,實際上是我路由器的IP。
docker exec -it fda365569efa /bin/bash,表示進入k8s容器dnsutils-ds-55fpd內部。
10.3.0.2,這個是我k8s集群中定義和創建的CoreDNS容器的ClusterIP,如果部署成功的話,內外網的功能變數名稱或服務訪問,都可以通過它做地址解析。
問題:如下圖,在容器內部,不能正常解析 外網地址www.baidu.com 和 內部地址cluster.local。這裡說明是物理機VM的nameserver配置錯誤導致的。
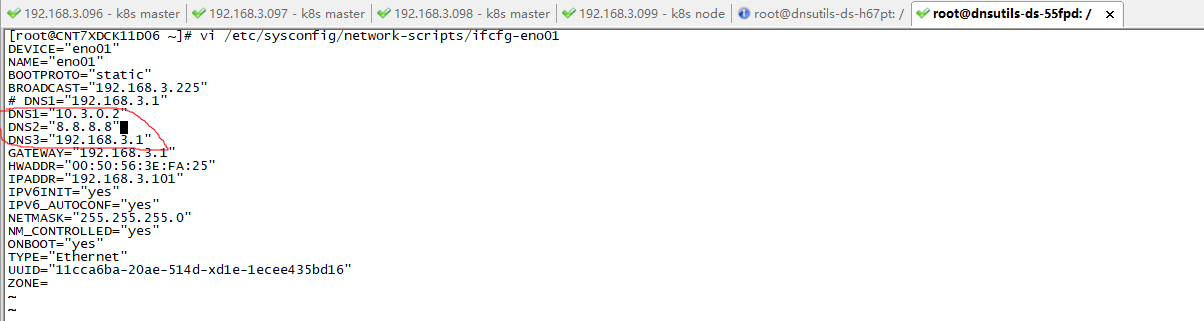
3. 修改VM的DNS解析文件之後,
# 修改VM機器上的網卡配置文件eno01,如下圖替換為正確的DNS地址。
# 這裡我們用谷歌的DNS功能變數名稱地址8.8.8.8 和 本地K8S集群CoreDNS的CluterIP地址10.3.0.2。
root >> vi /etc/sysconfig/network-scripts/ifcfg-eno01
# 然後記得保存,重啟VM機器之後,我們在重新檢查CoreDNS解析是否正常,操作如下:
root >> cat /etc/sysconfig/network-scripts/ifcfg-eno01
root >> cat /etc/resolv.conf
root >> ping -c 1 www.baidu.com
root >> ping -c 1 10.3.0.2
root >> ping -c 1 kubernetes
root >> nslookup www.baidu.com
root >> nslookup kubernetes
root >> nslookup kube-dns.kube-system.svc
root >> nslookup kube-dns.kube-system.svc.cluster.local
root >> nslookup cluster.local
#### docker 內部檢查dns 解析
root >> docker ps | grep dns
dnsutils root >>

