
相信大家都接觸過Mysql資料庫,而且也肯定都會寫sql。我不知道大家有沒有這樣的感受,反正我是有過這樣的想法。就是當我把一條sql語句寫完了,並且執行完得到想要的結果。這時我就在想為什麼我寫這樣的一條sql語句,就能給我查詢出我想要的結果,為什麼我寫了update就能更新一條語句?它們的執行過程是 ...
相信大家都接觸過Mysql資料庫,而且也肯定都會寫sql。我不知道大家有沒有這樣的感受,反正我是有過這樣的想法。就是當我把一條sql語句寫完了,並且執行完得到想要的結果。這時我就在想為什麼我寫這樣的一條sql語句,就能給我查詢出我想要的結果,為什麼我寫了update就能更新一條語句?它們的執行過程是什麼樣的?它們的原理是什麼?那麼接下來我就來談談這個。
select * from user where id=6
上面這條查詢語句非常簡單,就是查詢一個id為6的用戶信息。那麼它的執行流程是怎麼樣的?別急,咱們先看一張圖,
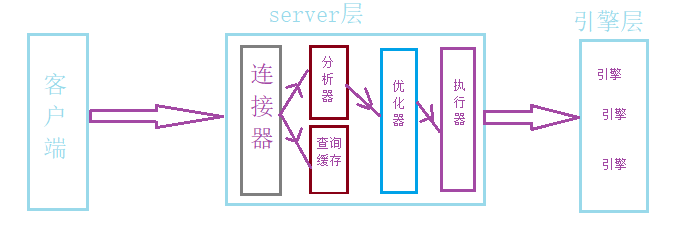
根據上面的圖,咱們一步一步來分析。從圖中可以看出整個執行過程大致可以分為兩部分,分別是server層和引擎層。
server層中又分為連接器、分析器、查詢緩存、優化器以及執行器幾部分。
引擎層則是主要負責存儲數據,提供讀寫介面。
那麼接下來從頭開始分析。
1、連接器
首先要操作資料庫,那麼必須得連接上資料庫,所以這時候就用到了連接器。當你輸入 “mysql -h$ip -P$埠 -u$登錄名 -p ” 時就表示要進行連接資料庫了,然後輸入密碼進行連接。如果密碼或者用戶名錯了,則會報如下錯誤:
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)
如果輸入用戶名和密碼正確,那麼連接器接下來就去許可權表中查詢你登錄用戶所擁有的許可權,之後此用戶操作數據的許可權判斷邏輯都將依賴查詢到的許可權。哪怕你修改了此用戶的許可權也還是沒用,必須重新新建連接,修改的許可權才會生效。
另外說到這裡就順便提一下,客戶端連接mysql伺服器時,如果連接一直處於空閑狀態,那麼到了一定的時候就會斷開連接,多長時間是由 wait_timeout 控制的,其預設是8個小時。如果超過8個小時,你執行操作資料庫時就回提示 “Lost connection to MySQL server during query”,這時只有重新連接資料庫方能進行操作。
說到連接器,咱們得說一下長連接和短鏈接。長連接就是如果客戶端一直都有請求操作資料庫,那麼就會一直使用這個連接進行操作。短鏈接就是每次執行完很少的資料庫操作就斷開連接了,如果再有請求就必須重新連接。
所以這裡建議減少資料庫的連接操作,儘量使用長連接。但是長時間使用長連接會導致一個問題,那就是mysql的占用的記憶體會越來越大,甚至到最後可能會出現OOM情況,導致mysql異常重啟,那麼這就尷尬了。
針對上面的情況有兩種解決辦法:
(1)、定期斷開長連接,或者斷開一些查詢占用記憶體比較大的操作的連接,釋放資源。
(2)、如果是5.7及以上版本,可以使用 mysql_reset_connection 來重置連接,但是需要註意以下幾點
- 活躍事務會被回滾,自動提交模式也會被重置;
- 釋放所有表鎖;
- 關閉&刪除所有臨時表;
- 會話變數(選項)被重置成和全局變數一致;
- 用戶級變數丟失;
- PREPARE語句會被釋放(其相應的HANDLER也會被關閉);
- LAST_INSERT_ID值重置為0;
- 利用GET_LOCK獲取的鎖會被釋放。
以上是mysql官微給出的解釋,所以重置連接的時候以上因素,以免對資料庫中的數據產生影響。
2、查詢緩存
客戶端連接成功mysql伺服器後,執行上面的一條sql時,首先會去緩存中查詢是否有數據,如果有數據,那麼直接把數據返回給客戶端,後面的步驟都省略了。它的原理怎樣的呢?請接著往下看,一條查詢sql的首次執行完成後,會把sql語句作為key,把查詢出來的數據作為value放入到緩存中,如果後面再有相同的查詢,那麼直接從緩存中取值便可。
看到這裡也許你們會想緩存這麼好用,那以後要多用緩存。別急,請接著往下看。查詢緩存用起來確實好用,但是它有一個弊端,那就是當這個表做了更新操作時,那麼此表的緩存將會全部清空。也許當你辛辛苦苦緩存起來的數據,還沒來得及用時就可能被一條update語句給全部幹掉。
所以如果更新比較頻繁的表是不適合使用緩存的,如果是某些配置表倒是比較適合緩存的使用。
在mysql中的查詢語句使不使用緩存時看query_cache_type的值,當為0時關閉緩存,當為1時表示開啟緩存,當為2(DEMAND)時表示只有在sql語句中帶有 SQL_CACHE 關鍵字才會使用緩存,如下sql
select SQL_CACHE * from user where id=6
不過需要註意的一點是 mysql 8.0 版本已經把緩存功能完全移除,所以這一塊需要註意一下。
3、分析器
當執行一條查詢sql時,會優先取查詢緩存,如果緩存中沒有數據,那麼便會開始sql的真正的執行流程。首先是分析器,其主要就是對sql語句進行 “詞法分析” 和 “語法分析”。
詞法分析 就是對sql中的單詞進行逐個的分析,比如 從 select 可以識別出要執行查詢操作,user則是識別成表user,id則識別成user表中欄位id。
語法分析就是分析整條sql是否符合mysql的語句,比如 你故意把sql中的 where 後面不跟條件,那麼語法就肯定會問題,那麼此時就會給你提示 “You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '' at line 1” 。如果給出類似的提示,那麼基本就是語法錯了,那就得仔細檢查一下寫的sql語句了。
4、優化器
經過了分析器這一層,那麼接下來就要進入優化器了。從分析器中我們已經知道這條sql是要執行更新還是查詢操作。那麼優化器便是要對這條sq執行之前l進行優化處理,有哪些優化處理呢?例如 某表有多個索引的時候 決定用哪一個索引;或者多關聯(join)查詢的時候,決定關聯的順序。比如下麵一條sql
select * from user u join score s using(ID) where u.id=10 and s.scores=60;
上面一條 sql 可以分為兩種情況
- 既可以先從表user裡面取出id=10的記錄的ID值,再根據ID值關聯到表socre,再判斷score表裡scores的值是否等於20。
- 也可以先從表score裡面取出scores=20的記錄的ID值,再根據ID值關聯到user,再判斷user表裡面id的值是否等於10。
這兩種方案得出的結果是一樣的,但是執行的效率是不一樣的,而優化器作用便是從中選擇一個方案。
5、執行器
當優化器選擇好了方案,那麼便進入執行器階段,這時候就要開始執行sql了。執行sql前要查詢一下你對需要操作的表是否有對應的操作許可權,如果沒有操作許可權,則會給出提示 “ERROR 1142 (42000): SELECT command denied to user 'b'@'localhost' for table 'XXX‘ “ 。
如果有對應表的操作許可權,那麼便打開表繼續執行,執行器會根據定義的表的引擎,來執行引擎提供的對應讀寫的介面,mysql 5.5版本之後 預設的引擎為 InnoDB。
其大致流程如下:(假如 id 是沒有索引的)
-
調用InnoDB引擎介面取這個表的第一行,判斷ID值是不是6,如果不是則跳過,如果是則將這行存在結果集中;
-
調用引擎介面取“下一行”,重覆相同的判斷邏輯,直到取到這個表的最後一行。
-
執行器將上述遍歷過程中所有滿足條件的行組成的記錄集作為結果集返回給客戶端。
如果是 id 是有索引的,第一次調用的是“取滿足條件的第一行”這個介面,之後迴圈取“滿足條件的下一行”這個介面,基本和上面差不多。這些介面都是引擎中已經定義好的。
至此 一條 sql 便執行完成。


