列子: 一條語句實現將'a,b,c'拆分成'a','b','c'三條記錄。 一、REGEXP_SUBSTR函數的使用說明: Regexp_Substr(String,pattern,position,occurrence ,modifier )一共包含了五個參數: String:操作的字元串; pa ...
列子: 一條語句實現將'a,b,c'拆分成'a','b','c'三條記錄。 一、REGEXP_SUBSTR函數的使用說明: Regexp_Substr(String,pattern,position,occurrence ,modifier )一共包含了五個參數: String:操作的字元串; pattern:正則表達式匹配規則,匹配到則返回; position:開始匹配的位置,預設當然是1; occurrence:標識第幾個匹配組,預設為1 modifier:模式(‘i‘不區分大小寫進行檢索,‘c‘區分大小寫進行檢索。預設為‘c‘) 二、 REGEXP_COUNT函數的使用說明
Oracle的11g引入此函數
REGEXP_COUNT ( source_char, pattern [, position [, match_param]])
REGEXP_COUNT 返回pattern 在source_char 串中出現的次數。如果未找到匹配,則函數返回0。position 變數告訴Oracle 在源串的什麼位置開始搜索。在開始位置之後每出現一次模式,都會使計數結果增加1。
match_param 變數支持下麵幾個值:
‘i’ 用於不區分大小寫的匹配
‘c’ 用於區分大小寫的匹配
‘n’ 允許句點(.)作為通配符去匹配換行符。如果省略該參數,則句點將不匹配換行符
‘m’ 將源串視為多行。即Oracle 將^和$分別看作源串中任意位置任何行的開始和結束,而不是僅僅看作整個源串的開始或結束。如果省略該參數,則Oracle將源串看作一行。
‘x’ 忽略空格字元。預設情況下,空格字元與自身相匹配。
select REGEXP_COUNT('GEORGE','GE',1,'i')
from DUAL;
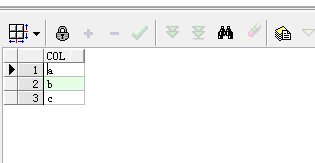
SELECT REGEXP_SUBSTR('a,b,c', '[^,]+', 1, LEVEL) AS COL
FROM DUAL
CONNECT BY LEVEL <= REGEXP_COUNT('a,b,c' , ',') + 1 結果: