
在上一篇中,我們談到過 要提升電腦的性能,可以從上面這三方面著手。 通過指令數/CPI,好像都太難了。 因此工程師們,就在CPU上多放晶體管,不斷提升CPU的時鐘頻率,讓CPU更快,程式的執行時間就會縮短。 從1978年Intel發佈的8086 CPU開始,電腦的主頻從5MHz開始,不斷攀升 1 ...

在上一篇中,我們談到過
程式的CPU執行時間 = 指令數×CPI×Clock Cycle Time要提升電腦的性能,可以從上面這三方面著手。
通過指令數/CPI,好像都太難了。
因此工程師們,就在CPU上多放晶體管,不斷提升CPU的時鐘頻率,讓CPU更快,程式的執行時間就會縮短。

- 從1978年Intel發佈的8086 CPU開始,電腦的主頻從5MHz開始,不斷攀升
- 1980年代中期的80386能夠跑到40MHz
- 1989年的486能夠跑到100MHz
- 直到2000年的奔騰4處理器,主頻已經到達了1.4GHz
1 功耗:CPU的“人體極限”
奔騰4的CPU主頻從來沒有達到過10GHz,最終它的主頻上限定格在3.8GHz
而且奔騰4的主頻雖然高,但是實際性能卻配不上同樣的主頻
想要用在筆記本上的奔騰4 2.4GHz處理器,其性能只和基於奔騰3架構的奔騰M 1.6GHz匹配
於是不僅讓Intel的對手AMD獲得了喘息之機,更是代表著“主頻時代”的終結。
後面幾代Intel CPU主頻不但沒有上升,反而下降了。
到如今,2019年的最高配置Intel i9 CPU,主頻也不過是5GHz
相較於1978年到2000年,這20年裡300倍的主頻提升,從2000年到現在的這19年,CPU的主頻大概提高了3倍
- CPU的主頻變化,奔騰4時進入瓶頸期

奔騰4的主頻為什麼沒能超3.8GHz?
就因為功耗.
一個3.8GHz的奔騰4處理器,滿載功率是130瓦
130瓦是什麼概念呢?機場允許帶上飛機的充電寶的容量上限是100瓦時
如果我們把這個CPU安在手機裡面,不考慮屏幕記憶體之類的耗電,這個CPU滿載運行45分鐘,充電寶裡面就沒電了
而iPhone X使用ARM架構的CPU,功率則只有4.5瓦左右。
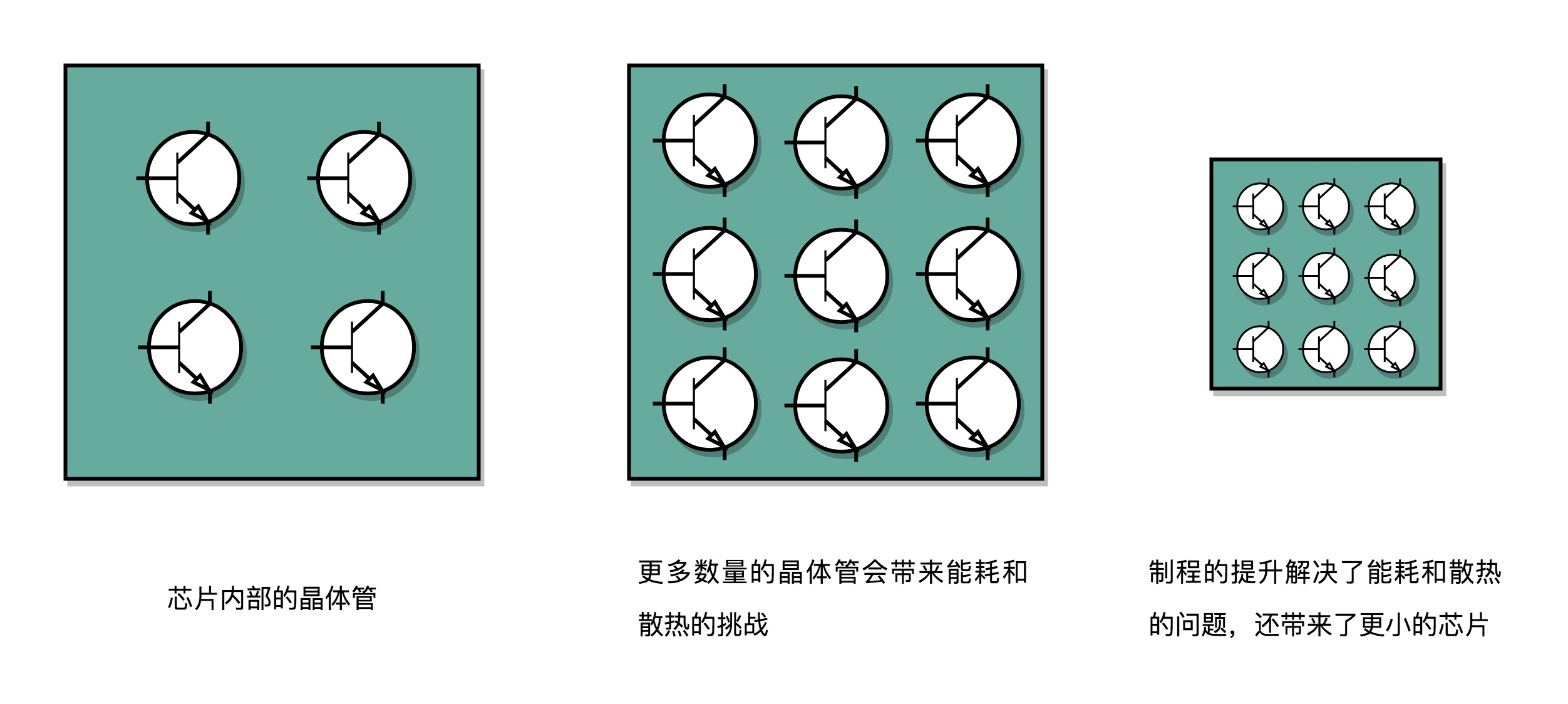
CPU,也稱作超大規模集成電路(Very-Large-Scale Integration,VLSI
由一個個晶體管組成
CPU的計算過程,其實就是讓晶體管裡面的“開關”不斷“打開”/“關閉”,組合完成各種運算和功能。
要想算得快
- 增加密度
在CPU同樣的面積,多放晶體管 - 提升主頻
讓晶體管“打開”/“關閉”得快點
這兩者,都會增加功耗,帶來耗電和散熱的問題!!!
可以把CPU想象成一個工廠,有很多工人
就如CPU上面的晶體管,互相之間協同工作。
為了工作快點完成,在工廠里多塞一點人
你可能會問,為什麼不把工廠造得大點?
這是因為,人和人之間如果離得遠了,互相之間走過去需要花的時間就會變長,這也會導致性能下降!
這就如如果CPU的面積大,晶體管之間的距離變大,電信號傳輸的時間就會變長,運算速度自然就慢了。
除了多塞一點人,還希望每個人動作快點,同樣時間就可多幹活了
這就相當於提升CPU主頻,但是動作快,每個人就要出汗散熱
要是太熱了,對工廠裡面的人來說會休克,對CPU來說就會崩潰出錯。
我們會在CPU上面抹硅脂、裝風扇,乃至用上水冷或者其他更好的散熱設備
就好像在工廠裡面裝風扇、空調,發冷飲一樣
但是同樣的空間下,裝上風扇空調能夠帶來的散熱效果也是有極限的
因此,在CPU裡面,能夠放下的晶體管數量和晶體管的“開關”頻率也都是有限的。
一個CPU的功率,可以用這樣一個公式來表示:
功耗 ≈ 1/2 ×負載電容 × 電壓的平方 × 開關頻率 × 晶體管數量為了提升性能,要不斷地增加晶體管數量
同樣的面積下,想要多放一點晶體管,就要把晶體管造得小一點
這個就是平時我們所說的提升“製程”
從28nm到7nm,相當於晶體管本身變成了原來的1/4大小
這個就相當於我們在工廠里,同樣的活兒,我們要找瘦小一點的工人,這樣一個工廠裡面就可以多一些人
我們還要提升主頻,讓開關的頻率變快,也就是要找手腳更快的工人
但功耗增加過多,CPU散熱就跟不上
這時就需要降低電壓
這裡有一點非常關鍵,在整個功耗的公式裡面,功耗和電壓的平方是成正比的
這意味著電壓下降到原來的1/5,整個的功耗會變成原來的1/25。
事實上,從5MHz主頻的8086到5GHz主頻的Intel i9,CPU的電壓已經從5V左右下降到了1V左右
這也是為什麼我們CPU的主頻提升了1000倍,但是功耗只增長了40倍
2 並行優化 - 阿姆達爾定律
雖然製程的優化和電壓的下降,在過去的20年裡,讓CPU性能有所提升
但是從上世紀九十年代到本世紀初,軟體工程師們所用的“面向摩爾定律編程”的套路越來越用不下去了
“寫程式不考慮性能,等明年CPU性能提升一倍,到時候性能自然就不成問題了”,這種想法已經不可行了。
於是,從奔騰4開始,Intel意識到通過提升主頻比較“難”去實現性能提升
開始推出Core Duo這樣的多核CPU,通過提升“吞吐率”而不是“響應時間”,來達到目的。
提升響應時間,就好比提升你用的交通工具的速度
原本你是開汽車,現在變成了高鐵乃至飛機
但是,在此之上,再想要提升速度就不太容易了
CPU在奔騰4的年代,就好比已經到了飛機這個速度極限
那你可能要問了,接下來該怎麼辦呢?
相比於給飛機提速,工程師們又想到了新的辦法,可以一次同時開2架、4架乃至8架飛機,這就好像我們現在用的2核、4核,乃至8核的CPU。
雖然從上海到北京的時間沒有變,但是一次飛8架飛機能夠運的東西自然就變多了,也就是所謂的“吞吐率”變大了。所以,不管你有沒有需要,現在CPU的性能就是提升了2倍乃至8倍、16倍。
這也是一個最常見的提升性能的方式,通過並行提高性能。
這個思想在很多地方都可以使用
舉個例子,我們做機器學習程式的時候,需要計算向量的點積,比如向量
$W = [W_0, W_1, W_2, …, W_{15}]$和向量
$X = [X_0, X_1, X_2, …, X_{15}]$$W·X = W_0 * X_0 + W_1 * X_1 +$$W_2 * X_2 + … + W_{15} * X_{15}$這些式子由16個乘法和1個連加組成。如果你自己一個人用筆來算的話,需要一步一步算16次乘法和15次加法。
如果這個時候我們把這個人物分配給4個人,同時去算\(W_0~W\_3\), \(W\_4~W\_7\), \(W\_8~W_{11}\), \(W_{12}~W_{15}\)這樣四個部分的結果,再由一個人進行彙總,需要的時間就會縮短。

但並不是所有問題,都可以通過並行提高性能來解決
要使用這種思想,需要滿足以下條件:
- 需要進行的計算,本身可以分解成幾個可以並行的任務
好比上面的乘法和加法計算,幾個人可以同時進行,不會影響最後的結果。 - 需要能夠分解好問題,並確保幾個人的結果能夠彙總到一起
- 在“彙總”這個階段,是沒有辦法並行進行的,還是得順序執行,一步一步來。
這就引出了性能優化中一個經驗定律
- 阿姆達爾定律(Amdahl’s Law)
對於一個程式進行優化之後,處理器並行運算之後效率提升的情況
具體可以用這樣一個公式來表示:
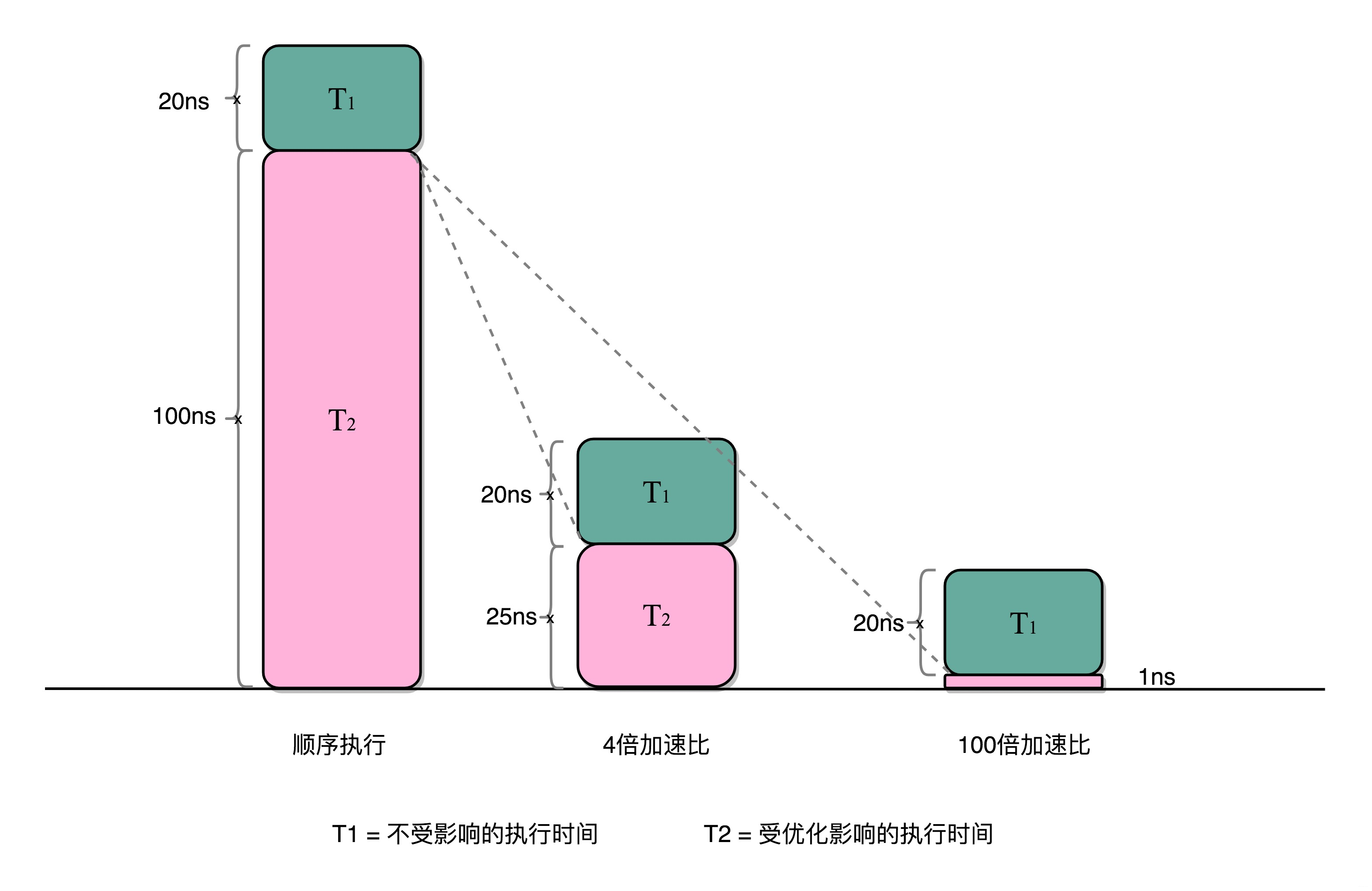
優化後的執行時間 = 受優化影響的執行時間/加速倍數+不受影響的執行時間在剛剛的向量點積例子里,4個人同時計算向量的一小段點積,就是通過並行提高了這部分的計算性能
但是,這4個人的計算結果,最終還是要在一個人那裡進行彙總相加
這部分彙總相加的時間,是不能通過並行來優化的,也就是上面的公式裡面不受影響的執行時間部分
比如上面的各個向量的一小段
- 點積,需要100ns
- 加法需要20ns
總共需要120ns。這裡通過並行4個CPU有了4倍的加速度。那麼最終優化後,就有了100/4+20=45ns
即使我們增加更多的並行度來提供加速倍數,比如有100個CPU,整個時間也需要100/100+20=21ns。
3 總結
無論是簡單地通過提升主頻,還是增加更多的CPU核心數量,通過並行提升性能,都會遇到相應的瓶頸
僅靠簡單地通過“堆硬體”的方式,在今天已經不能很好地滿足我們對於程式性能的期望了。
於是,工程師們需要從其他方面開始下功夫了。
在“摩爾定律”和“並行計算”之外,在整個電腦組成層面,還有這樣幾個原則性的性能提升方法。
3.1 加速大概率事件
深度學習,整個計算過程中,99%都是向量和矩陣計算
於是,工程師們通過用GPU替代CPU,大幅度提升了深度學習的模型訓練過程
本來一個CPU需要跑幾小時甚至幾天的程式,GPU只需要幾分鐘就好了
Google更是不滿足於GPU的性能,進一步地推出了TPU
通常我們使用 O 表示一個演算法的好壞,我們優化一個演算法也是基於 big-O
但是 big-O 其實是一個近似值,就好比一個演算法時間複雜度是 O(n^2) + O(n)
這裡的 O(n^2) 是占大比重的,特別是當 n 很大的時候,通常我們會忽略掉 O(n),著手優化 O(n^2) 的部分
3.2 通過流水線提高性能
現代的工廠里的生產線叫“流水線”。
我們可以把裝配iPhone這樣的任務拆分成一個個細分的任務,讓每個人都只需要處理一道工序,最大化整個工廠的生產效率。
我們的CPU其實就是一個“運算工廠”
我們把CPU指令執行的過程進行拆分,細化運行,也是現代CPU在主頻沒有辦法提升那麼多的情況下,性能仍然可以得到提升的重要原因之一
3.3 通過預測提高性能
預測下一步該乾什麼,而不是等上一步運行結果,提前進行運算,也是讓程式跑得更快一點的辦法
在一個迴圈訪問數組的時候,憑經驗,你也會猜到下一步我們會訪問數組的下一項
後面要講的“分支和冒險”、“局部性原理”這些CPU和存儲系統設計方法,其實都是在利用我們對於未來的“預測”,提前進行相應的操作,來提升我們的程式性能。
深度優先搜索演算法裡面的 “剪枝策略”,防止沒有必要的分支搜索,這會大幅度提升演算法效率
- 整個組成乃至體繫結構,都是基於馮·諾依曼架構組成的軟硬體一體的解決方案
- 這裡面的方方面面的設計和考慮,除了體繫結構層面的抽象和通用性之外,核心需要考慮的是“性能”問題
參考
深入淺出電腦組成原理
X 交流學習



