
作者: Dominik Moritz, Bill Howe, Jeffrey Heer 發表於CHI 2019, 三位作者都來自於University of Washington Interactive Data Lab 項目代碼: 簡介 Linked Visualization(鏈接可視化系統)是 ...
作者: Dominik Moritz, Bill Howe, Jeffrey Heer
發表於CHI 2019, 三位作者都來自於University of Washington Interactive Data Lab
項目代碼:https://github.com/uwdata/falcon
簡介
Linked Visualization(鏈接可視化系統)是通過刷選、放縮等操作,在不同可視化視圖上進行交互,鏈接(link)不同視圖的操作,並更新視圖的一種可視化方式。為了支持有效的探索,Linked Visualization必須提供快速響應來消除延遲敏感。在百萬級以上的數據量時,傳統可視化方法無法實現實時的探索,引出一系列問題。
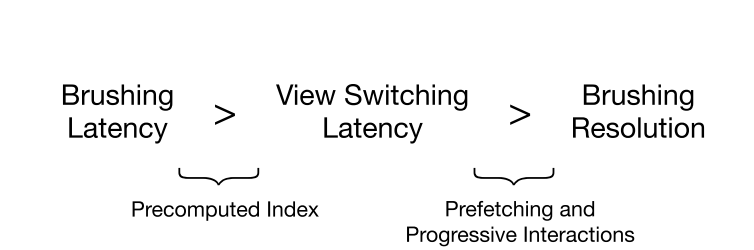
本文提出falcon,一個大數據Linked Visualizations的低延遲方案,實現對十億數據集的冷啟動探索。falcon平衡交互延遲和視圖精度,從查詢和界面系統兩方面對Linked Visualizations進行優化,降低刷選和鏈接(brushing and linking)的延遲。結合數據索引,數據預取和漸進式交互等方法,falcon系統使用載入數據子索引來優化刷選延遲,通過逐步載入互動式解析度,以減少視圖切換時間。實驗表明,falcon實現了50fps的刷選交互延遲,無需昂貴的預計算和存儲代價。
相關工作
- Linked Visualization在商用可視化軟體,如tableau, powerBI, DataV中應用非常廣泛。他們經常使用直方圖作為可視化方式,輔以brushing and linking 作為交互手段,讓用戶在展示不同維度的視圖之間互動式刷選部分子集,同時在其它視圖間同步展示子集結果。
- 在論文The effects of interactive latency on exploratory visual analysis(2014 TVCG)中,Liu and Heer指出超過500ms的延遲會對用戶行為造成較大影響,用戶對刷選(brushing and linking)相比平移(pan)和縮放(zoom)有更高的延遲敏感度。
- 過去的工作採用預處理數據索引或者稀疏數據塊的方案來達到加快可視查詢和交互的目標,但它們無不會導致高昂的計算和存儲代價。這些文章有imMens(2013 EuroVis), Nanocube(2013 VIS)等等。
- falcon分解高維數據索引,分解後它僅支持與單個活動視圖的交互,當用戶與特定視圖交互(active view)時,將其所需部分數據索引進行載入。這樣每次交互所需索引的大小在視圖數量上是線性的,這避免了維度爆炸。
界面設計
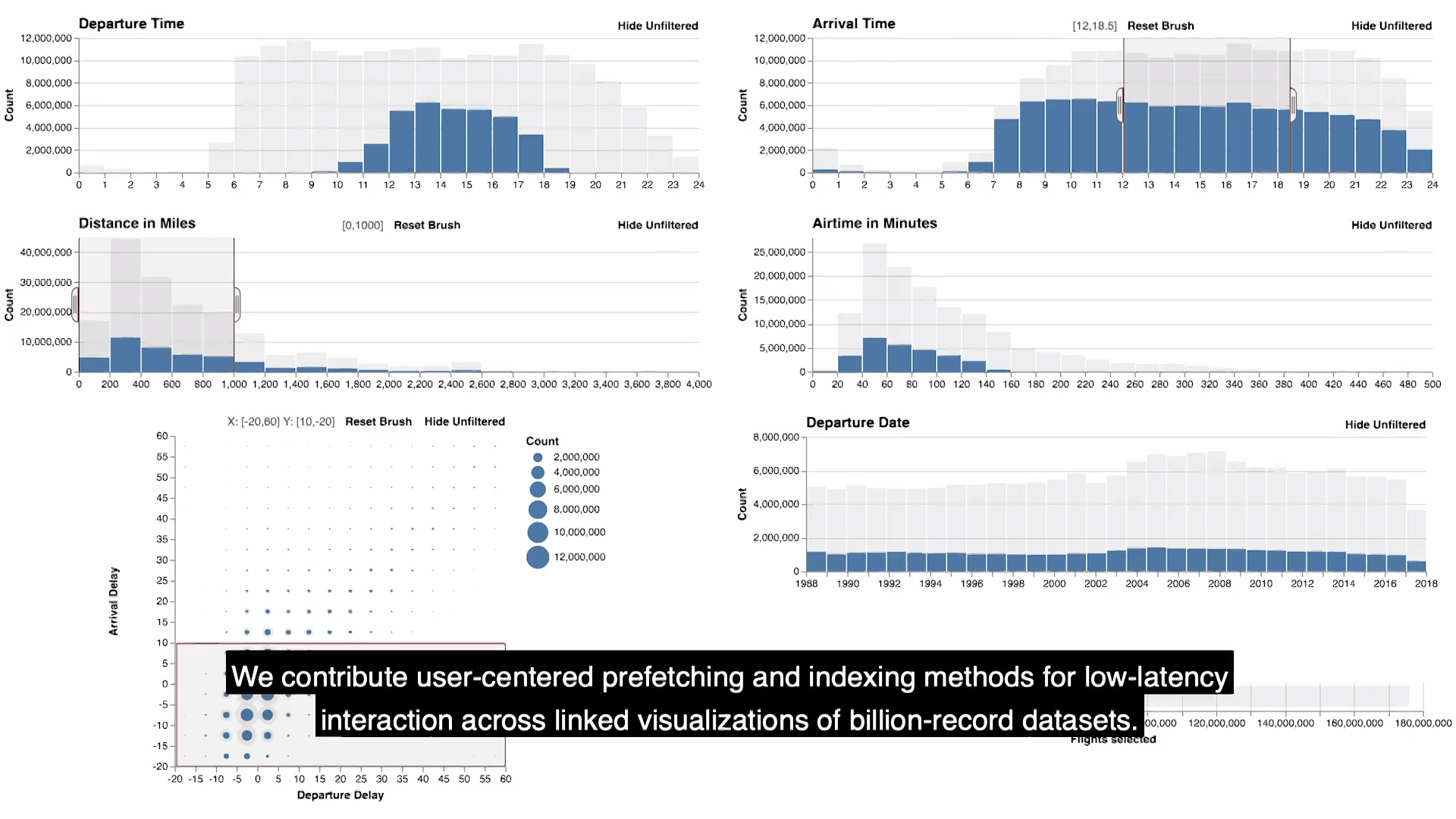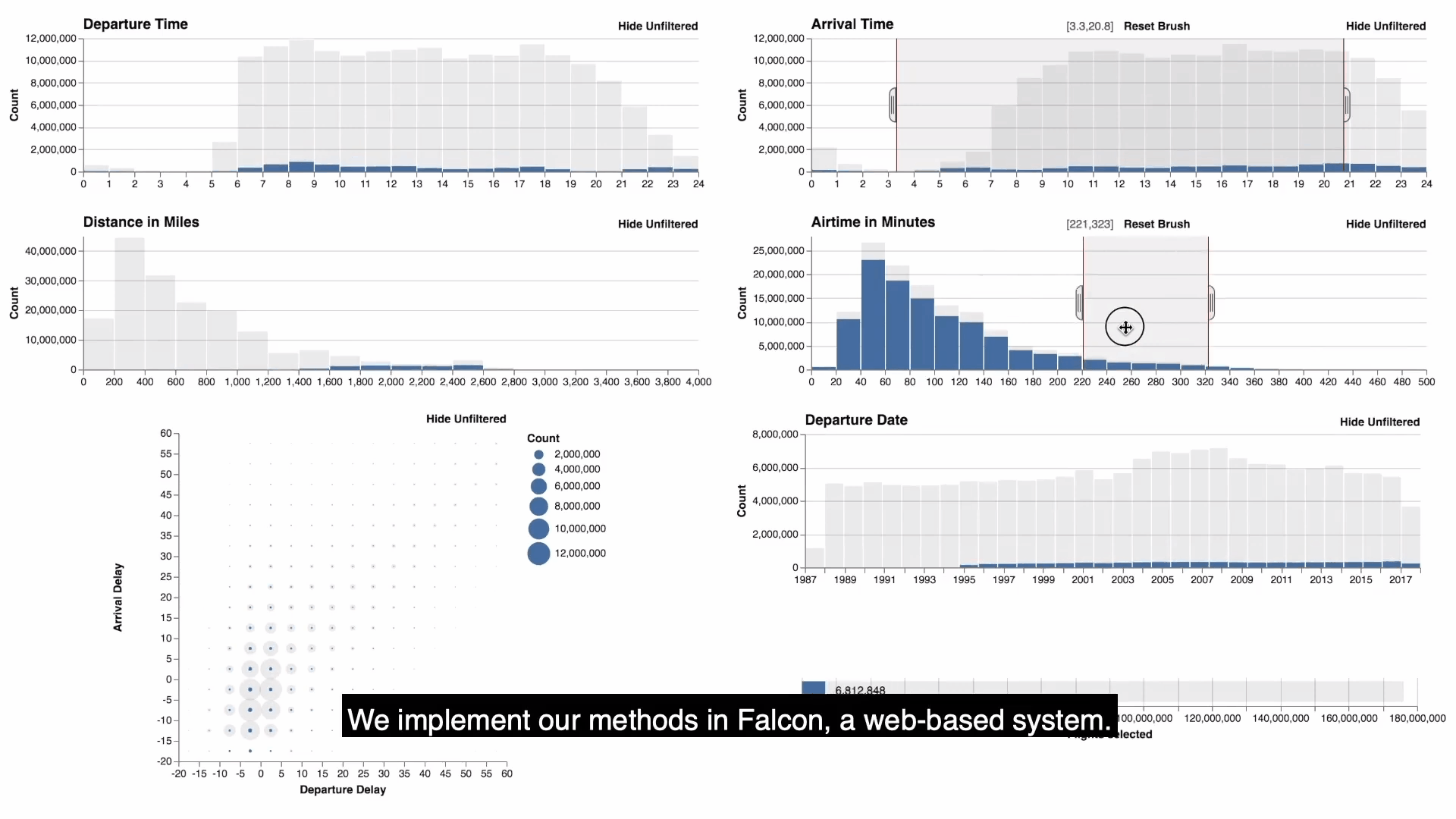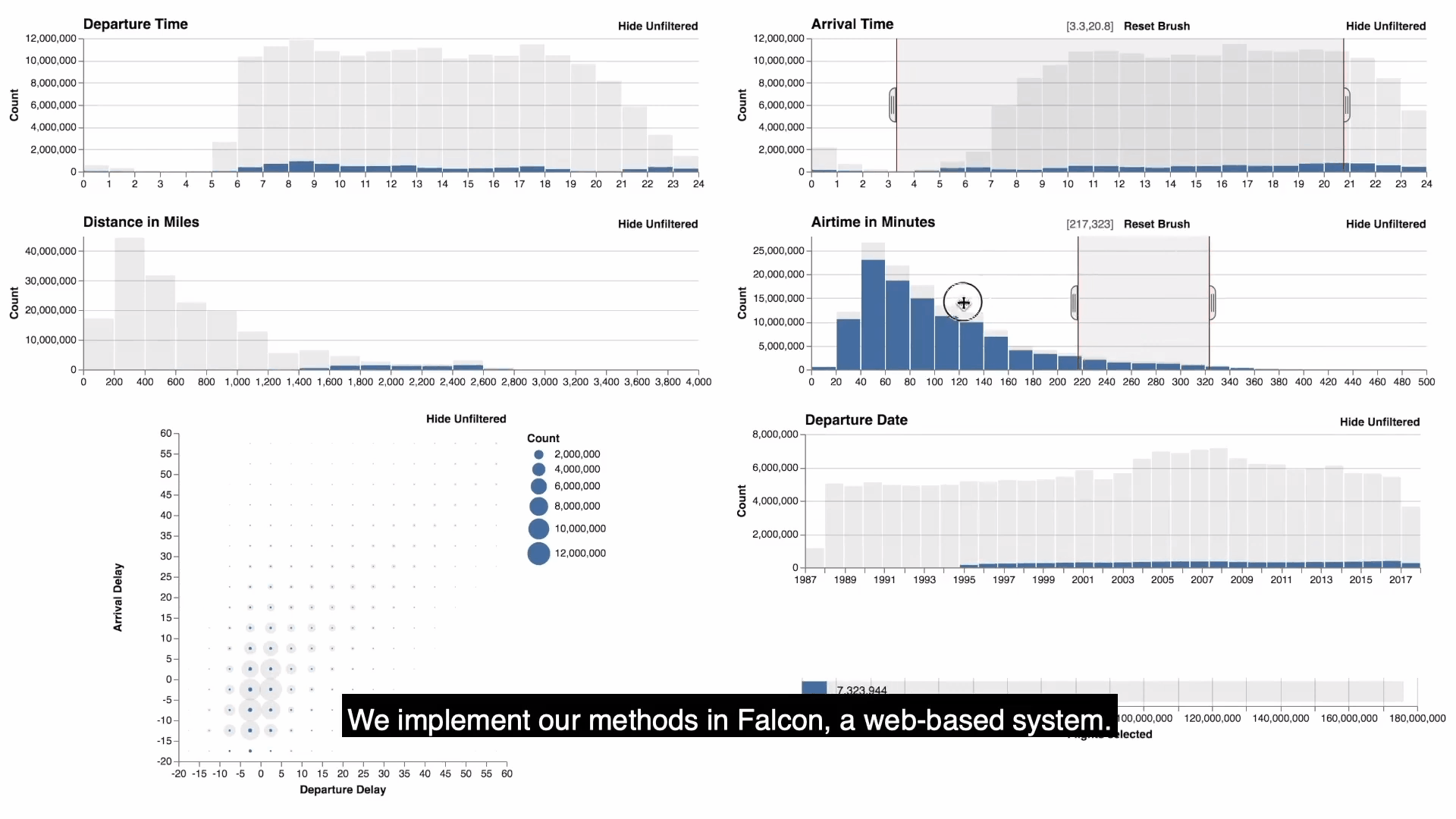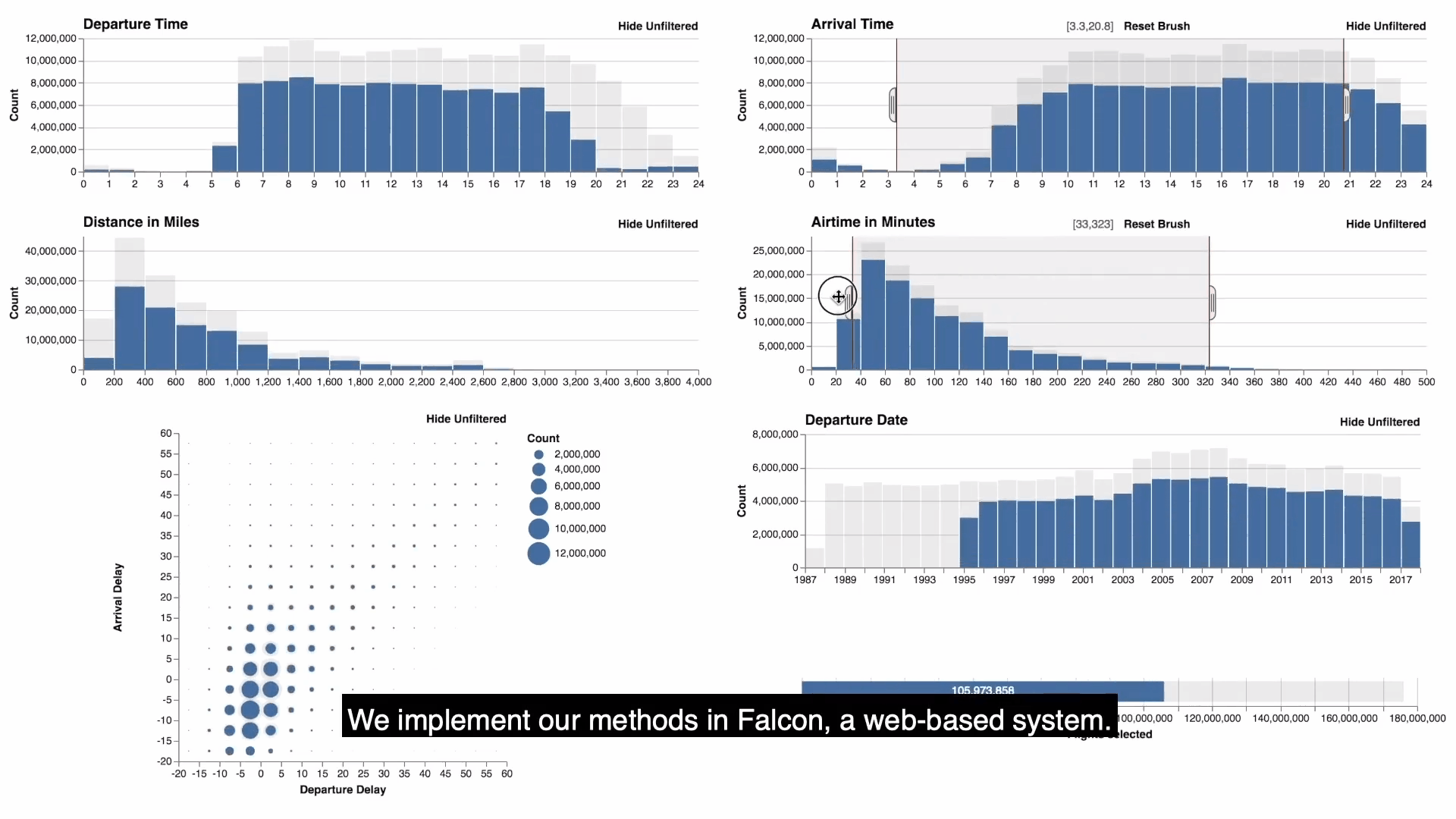
- falcon提供了一個可視化的視圖儀錶板,具有零,一個或兩個維度的直方圖。如圖顯示的是flights數據的可視化結果。每個視圖都支持刷選,放縮,平移的功能,通過brushing and linking同步更新所有視圖的查詢結果,此外還可以通過按鈕來選擇是否查看沒有被過濾的數據。
- 需要註意的是正在刷選的視圖是主視圖(active view), 其餘都是次視圖(passive view),上圖中滑鼠所正在刷選的(第二行第二個)就是active view。
演算法與模型
數據索引
大數據可視化系統中,我們常常使用數據索引來存儲數據,以此優化後端處理中的時間複雜度和空間複雜度。數據索引又叫data tile, datacube。如下圖所示,一個1維的直方圖,我們可以使用一個同樣長度的數組,每條數據按照維度信息放入相應的數據方格當中,形成數據索引。如果是2維的直方圖,同理,我們需要一個2維的數組(一個平面)作為數據索引,此時每個直方圖的相應格子就是平面中的某一行或者某一列的和。3維依次類推,是一個立方體,此時每個直方圖的相應格子就是立方體中的某個平面的和。
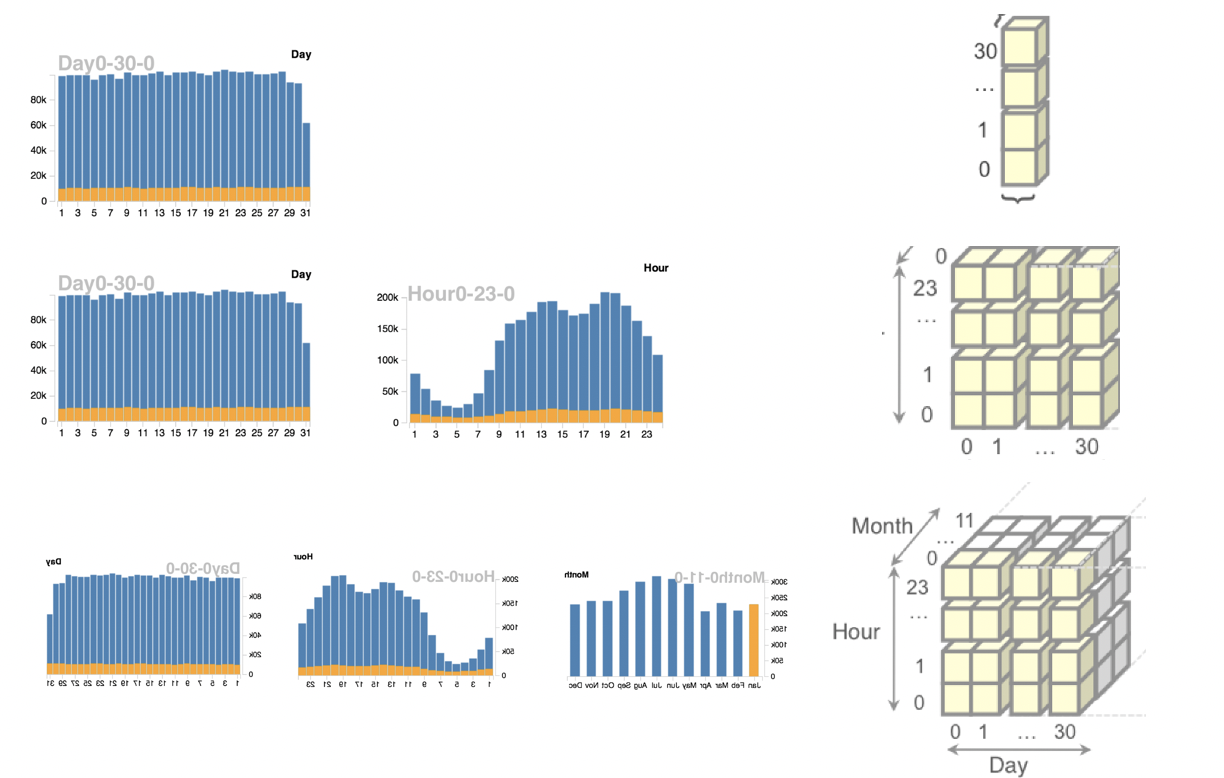
假設數據條數是T, 維度數為m, 每個維度的劃分精度為n,那麼構建時間複雜度: \(O(T)\),空間複雜度: \(O(n^m)\),查詢複雜度: \(O(n^{m-1})\)。可以發現空間複雜度和查詢複雜度都隨維度呈指數型增長,這樣在高維度(多視圖)的可視化系統中,存在巨大的維度災難。針對較高的查詢複雜度,我們可以使用sum area table將查詢複雜度降到\(O(2^m)\),但是處理數據索引的空間複雜度依然巨大,當可視化系統的前後端分離的情況下,更會帶來巨大的傳輸延遲和存儲負擔。
本文針對這個情況提出處理當前刷選視窗(active view)相關的數據子索引的方案,有效減小了空間複雜度,也一併減少了查詢複雜度。假設有5個維度,每個維度粒度是10,顯示五個單維度的直方圖。舊方案需要\(O(10^5)\)的空間複雜度和\(O(2^5)\)的查詢複雜度(有sum area table), 只會預處理一次。新方案冷啟動無需預處理,每次切換刷選視窗(active view)時需要O(4 * 100)的空間複雜度和僅僅O(4)的查詢複雜度。

Falcon 採用兩種數據索引的實現方案。一是如果數據量比較小(< \(10^6\)), 會直接在前端生產高維數據索引, 進行查詢。二是如果數據量很大,通過後端的高性能GPU資料庫(OmniSci)來生成數據索引。由於falcon只需要當前界面數據子索引的思想,有效減小了響應時間。
延時載入與線性插值
有時計算數據索引需要很長時間,falcon會優先計算粗精度下的數據索引,之後再載入細精度的索引。如果框選範圍處於條形圖的中間位置,falcon會使用線性插值的方式進行擬合。論文通過實驗證明,儘管使用線性插值,真實值和擬合值的Wasserstein distance處於非常小的範圍內(99%的情況下< 0.01)。
實驗
作者將Falcon與SquareCrossfilter進行了比較,記錄了300萬條記錄的5個視圖的刷選實驗結果。Falcon的性能是恆定的,接近瀏覽器的最大幀速率60fp。反觀SquareCrossfilter,當向刷選開始和結束過程中,系統會反應緩慢。

此外本文還針對不同數據集進行了測試。下表統計不同數據集大小的所有視圖的在切換刷選視窗(active view)的等待時間的平均值,中位數和第95百分位樹,分別在像素解析度(1維為500個bins,2維200×200bins)和bin解析度(1維25bin和2維25×25bins)下進行統計。測試結果其中包括了網路傳輸的時間,灰色顯示計算第一個視圖的傳輸完成的時間,Browser指只有前端的實現方法,Core指使用GPU資料庫作為後端的實現方法。

實驗表明:
- falcon對於只有前端和前後端分離的兩種方案,都有顯著的性能提升。
falcon的框選操作的時長不再取決於原數據量大小,框選精度不再取決於原本數據的最小精度。
falcon通過逐步載入和線性插值的方式來減小用戶在數據量較大時的不舒適感。
總結
針對大數據Linked Visualizations,本文提出了考慮刷新延遲優先於視圖切換延遲,以及降低交互的初始解析度以改善視圖切換時間的方案。基於原型系統falcon,當連接到後端GPU資料庫系統時,falcon支持流暢瀏覽和刷選數十億條記錄,而無需昂貴的預計算或其他記憶體等方面的限制。但falcon還有許多不足之處,如:
falcon只實現了關於求和的功能,並不涉及中位數,平均數等更複雜的計算。也不涉及非數值型數據的計算。
預設用戶每次只會刷選一個視圖,如果用戶使用的是觸屏設備,這個假設就會被推翻。
更註重刷選的操作,對於縮放等操作並沒有進行優化和討論。
對於數據索引的處理方面有更多的發揮空間,比如數據壓縮,中間件的處理等等。
總之,falcon從一個不同的視角解決了Linked Visualizations的刷選延遲問題,實現了對十億數據集的冷啟動探索。


