
Hadoop Shuffer Hadoop 的shuffer主要分為兩個階段:Map、Reduce。 Map Shuffer: 這個階段發生在map階段之後,數據寫入記憶體之前,在數據寫入記憶體的過程就已經開 ...
Hadoop Shuffer
Hadoop 的shuffer主要分為兩個階段:Map、Reduce。
Map-Shuffer:
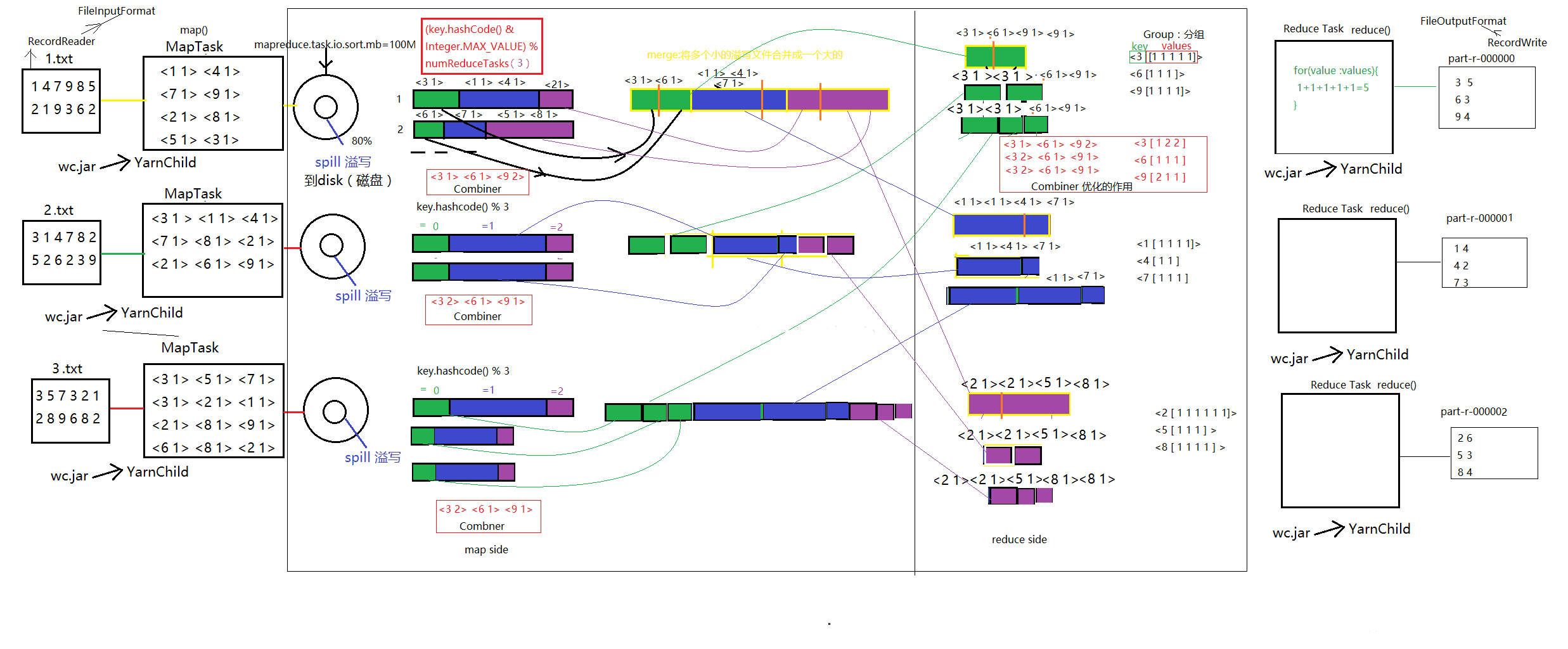
這個階段發生在map階段之後,數據寫入記憶體之前,在數據寫入記憶體的過程就已經開始shuffer,通過設置mapreduce.task.io.sort.mb的參數,可改變記憶體的大小,預設為100M。數據在寫入記憶體大於80%時,會發生溢寫spill)過程,將數據整體落地到磁碟,這個過程中預設調用快速排序演算法進行排序,否則調用用戶自定義的 combiner()方法,將數據按照排序的規則分佈在分區。然後進入mapshuffer最後一個階段merge,當磁碟中某一個分區的文件數量>=3個,自動觸發文件合併合併程式,這個過程將一個分區的所有數據進行排序合併成一個文件目錄(歸併演算法),以供reduce抓取。
(k,v,p) :一條數據,其中p是分區號。
Reduce-Shuffer:
通過拷貝線程copy merge中的數據到reduce端,調用歸併演算法,生成一個個Iterator,再通過分組程式,將同一個key的分組放在一起,聚合為一個Iterator。
Spark-Shuffer
Spark HashShuffle 是它以前的版本,現在1.6x 版本默應是 Sort-Based Shuffle。有分散式就一定會有 Shuffle,而且 HashShuffle 是 Spark以前的版本,亦即是 Sort-Based Shuffle 的前身,因為有 HashShuffle 的不足,才會有後續的 Sorted-Based Shuffle,以及現在的 Tungsten-Sort Shuffle。
Spark可以基於記憶體、也可以基於磁碟或者是第三方的儲存空間進行計算:
第一、Spark框架的架構設計和設計模式上是傾向於在記憶體中計算數據的。
第二、這也表達了人們對數據處理的一種美好的願望,就是希望計算數據的時候,數據就在記憶體中。
Shuffle 是分散式系統的天敵
Spark 運行分成兩部分,第一部分是 Driver Program,裡面的核心是 SparkContext,它驅動著一個程式的開始,負責指揮,另外一部分是 Worker 節點上的 Task,它是實際運行任務的,當程式運行時,不間斷地由 Driver 與所在的進程進行交互,交互什麼,有幾點,第一、是讓你去乾什麼,第二、是具體告訴 Task 數據在那裡,例如說有三個 Stage,第二個 Task 要拿數據,它就會向 Driver 要數據,所以在整個工作的過程中,Executor 中的 Task 會不斷地與 Driver 進行溝通,這是一個網路傳輸的過程。

關於這種架構有幾點有用的註意事項:
- 每個應用程式都有自己的執行程式進程,這些進程在整個應用程式的持續時間內保持不變併在多個線程中運行任務。這樣可以在調度方(每個驅動程式調度自己的任務)和執行方(在不同JVM中運行的不同應用程式中的任務)之間隔離應用程式。但是,這也意味著無法在不將Spark應用程式(SparkContext實例)寫入外部存儲系統的情況下共用數據。
- Spark與底層集群管理器無關。只要它可以獲取執行程式進程,並且這些進程相互通信,即使在也支持其他應用程式的集群管理器(例如Mesos / YARN)上運行它也相對容易。
- 驅動程式必須在其生命周期內監聽並接受來自其執行程式的傳入連接(例如,請參閱網路配置部分中的spark.driver.port)。因此,驅動程式必須是來自工作節點的網路可定址的。
- 因為驅動程式在集群上調度任務,所以它應該靠近工作節點運行,最好是在同一區域網上運行。如果您想遠程向群集發送請求,最好向驅動程式打開RPC並讓它從附近提交操作,而不是遠離工作節點運行驅動程式。
在這個過程中一方面是 Driver 跟 Executor 進行網路傳輸,另一方面是Task要從 Driver 抓取其他上游的 Task 的數據結果,所以有這個過程中就不斷的產生網路結果。其中,下一個 Stage 向上一個 Stage 要數據這個過程,我們就稱之為 Shuffle。
每一個節點計算一部份數據,如果不對各個節點上獨立的部份進行匯聚的話,我們是計算不到最終的結果。這就是因為我們需要利用分散式來發揮它本身並行計算的能力,而後續又需要計算各節點上最終的結果,所以需要把數據匯聚集中,這就會導致 Shuffle,這也是說為什麼 Shuffle 是分散式不可避免的命運。
原始的 HashShuffle 機制
基於 Mapper 和 Reducer 理解的基礎上,當 Reducer 去抓取數據時,它的 Key 到底是怎麼分配的,核心思考點是:作為上游數據是怎麼去分配給下游數據的。在這張圖中你可以看到有4個 Task 在2個 Executors 上面,它們是並行運行的,Hash 本身有一套 Hash演算法,可以把數據的 Key 進行重新分類,每個 Task 對數據進行分類然後把它們不同類別的數據先寫到本地磁碟,然後再經過網路傳輸 Shuffle,把數據傳到下一個 Stage 進行匯聚。
HashShuffle 缺點:
- Shuffle前在磁碟上會產生海量的小文件,此時會產生大量耗時低效的 IO 操作 (因為產生過多的小文件)
- 記憶體不夠用,由於記憶體中需要保存海量文件操作句柄和臨時信息,如果數據處理的規模比較龐大的話,記憶體不可承受,會出現 OOM 等問題。
優化後的 HashShuffle 機制
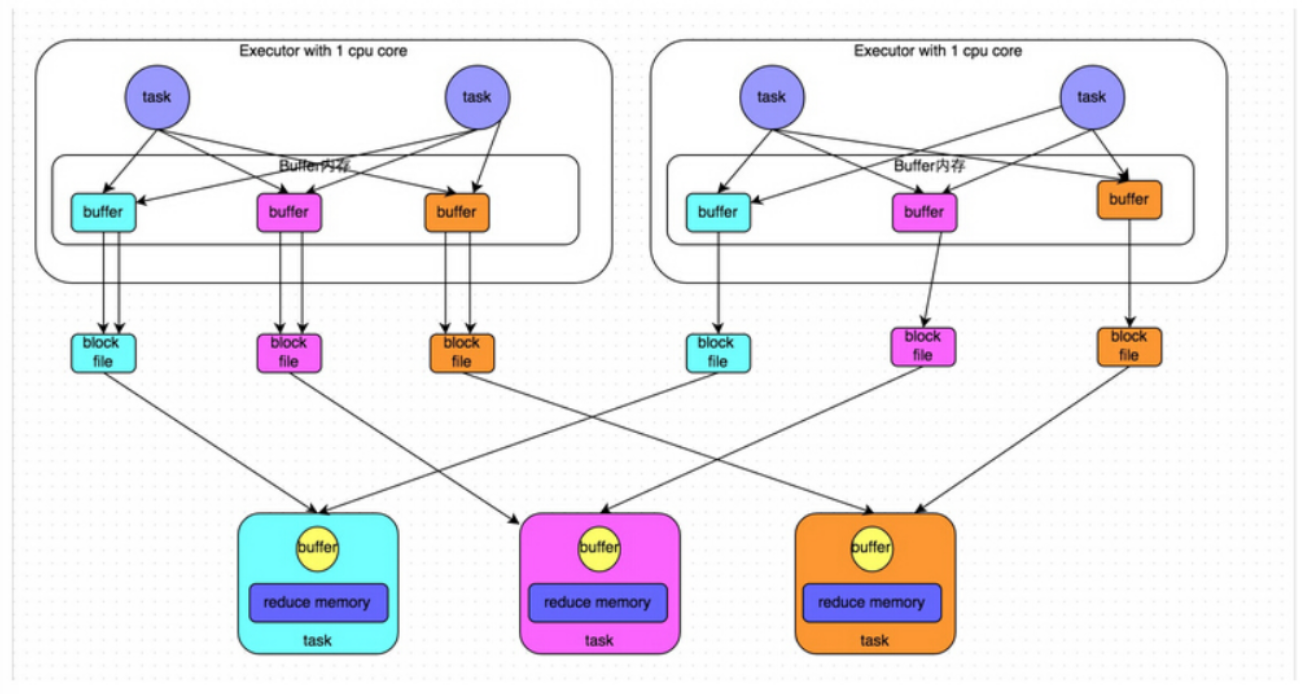
有4個Tasks,數據類別還是分成3種類型,因為Hash演算法會根據你的 Key 進行分類,在同一個進程中,無論是有多少過Task,都會把同樣的Key放在同一個Buffer里,然後把Buffer中的數據寫入以Core數量為單位的本地文件中,(一個Core只有一種類型的Key的數據),每1個Task所在的進程中,分別寫入共同進程中的3份本地文件,這裡有4個Mapper Tasks,總共輸出是 2個Cores x 3個分類文件 = 6個本地小文件。Consoldiated Hash-Shuffle的優化有一個很大的好處就是假設現在有200個Mapper Tasks在同一個進程中,也只會產生3個本地小文件; 如果用原始的 Hash-Based Shuffle 的話,200個Mapper Tasks 會各自產生3個本地小文件,在一個進程已經產生了600個本地小文件。
這個優化後的 HashShuffle 叫 ConsolidatedShuffle,在實際生產環境下可以調以下參數:
spark.shuffle.consolidateFiles=trueConsolidated HashShuffle 缺點:
- 如果 Reducer 端的並行任務或者是數據分片過多的話則 Core * Reducer Task 依舊過大,也會產生很多小文件。
Shuffle影響Spark性能及調優點
Shuffle 不可以避免是因為在分散式系統中的基本點就是把一個很大的的任務/作業分成一百份或者是一千份,這一百份和一千份文件在不同的機器上獨自完成各自不同的部份,我們是針對整個作業要結果,所以在後面會進行匯聚,這個匯聚的過程的前一階段到後一階段以至網路傳輸的過程就叫 Shuffle。
在 Spark 中為了完成 Shuffle 的過程會把真正的一個作業劃分為不同的 Stage,這個Stage 的劃分是跟據依賴關係去決定的,Shuffle 是整個 Spark 中最消耗性能的一個地方。試試想想如果沒有 Shuffle 的話,Spark可以完成一個純記憶體式的操作。
reduceByKey,它會把每個 Key 對應的 Value 聚合成一個 value 然後生成新的 RDD。
因為在不同節點上我們要進行數據傳輸,數據在通過網路發送之前,要先存儲在記憶體中,記憶體達到一定的程度,它會寫到本地磁碟,(在以前 Spark 的版本它沒有Buffer 的限制,會不斷地寫入 Buffer 然後等記憶體滿了就寫入本地,現在的版本對 Buffer 多少設定了限制,以防止出現 OOM,減少了 IO)。Mapper 端會寫入記憶體 Buffer,這個便關乎到 GC 的問題,然後 Mapper端的 Block 要寫入本地,大量的磁碟與IO的操作和磁碟與網路IO的操作,這就構成了分散式的性能殺手。
如果要對最終計算結果進行排序的話,一般會都會進行 sortByKey,如果以最終結果來思考的話,可以認為是產生了一個很大很大的 partition,可以用 reduceByKey 的時候指定它的並行度,例如把 reduceByKey 的並行度變成為1,新 RDD 的數據切片就變成1,排序一般都會在很多節點上,如果把很多節點變成一個節點然後進行排序,有時候會取得更好的效果,因為數據就在一個節點上,技術層面來講就只需要在一個進程里進行排序。
可以在調用 reduceByKey()接著調用 mapPartition( );
也可以用 repartitionAndSortWithPartitions( );
還有一個地方就是數據傾斜,Shuffle 時會導政數據分佈不均衡。數據傾斜的問題會引申很多其他問題,比如,網路帶寬、各重硬體故障、記憶體過度消耗、文件掉失。因為 Shuffle 的過程中會產生大量的磁碟 IO、網路 IO、以及壓縮、解壓縮、序列化和反序列化等等。
Shuffle可能面臨的問題,運行 Task 的時候才會產生 Shuffle (Shuffle 已經融化在 Spark 的運算元中)
- 幾千台或者是上萬台的機器進行匯聚計算,數據量會非常大,網路傳輸會很大
- 數據如何分類其實就是 partition,即如何 Partition、Hash 、Sort 、計算
- 負載均衡 (數據傾斜)
- 網路傳輸效率,需要壓縮或解壓縮之間做出權衡,序列化 和 反序列化也是要考慮的問題
具體的 Task 進行計算的時候盡一切最大可能使得數據具備 Process Locality 的特性,退而求其次是增加數據分片,減少每個 Task 處理的數據量**,基於Shuffle 和數據傾斜所導致的一系列問題,可以延伸出很多不同的調優點,比如說:
- Mapper端的 Buffer 應該設置為多大呢?
- Reducer端的 Buffer 應該設置為多大呢?如果 Reducer 太少的話,這會限制了抓取多少數據
- 在數據傳輸的過程中是否有壓縮以及該用什麼方式去壓縮,默應是用 snappy 的壓縮方式。
- 網路傳輸失敗重試的次數,每次重試之間間隔多少時間。
總結
因為想利用分散式的計算能力,所以要把數據分散到不同節點上運行,上游階段數據是並行運行的,下游階段要進行匯聚,所以出現Shuffle,如果下游分成三類,上游也需要每個Task把數據分成三類,雖然有可能有一類是沒有數據,這無所謂,只要在實際運行時按照這套規則就可以了,這就是最原始的 Shuffle 過程。
Hash-based Shuffle 預設Mapper 階段會為Reducer 階段的每一個Task單獨創建一個文件來保存該Task中要使用的數據,但是在一些情況下(例如說數據量非常龐大的情況) 會造成大量文件的隨機磁碟IO操作且會性成大量的Memory消耗(極易造成OOM)。
- 原始的 Hash-Shuffle 所產生的小文件: Mapper 端 Task 的個數 x Reduce 端 Task 的數量
- Consolidated Hash-Shuffle 所產生的小文件: CPU Cores 的個數 x Reduce 端 Task 的數量
Spark Shuffle 說到底都是離不開讀文件、寫文件、為了高效我們需要緩存,由於有很多不同的進程,就需要一個管理者。HashShuffle 適合的埸景是小數據的埸景,對小規模數據的處理效率會比排序後的 Shuffle 高。
區別在於HadoopShuffer是sort-based,spill記憶體大小是100M,Saprk是hash-based(hash-based故名思義也就是在Shuffle的過程中寫數據時不做排序操作,只是將數據根據Hash的結果,將各個Reduce分區的數據寫到各自的磁碟文件中),記憶體大小是32K,Hadoop的Shuffle過程是明顯的幾個階段:map(),spill,merge,shuffle,sort,reduce()等,是按照流程順次執行的,屬於push類型;但是,Spark不一樣,因為Spark的Shuffle過程是運算元驅動的,具有懶執行的特點,屬於pull類型。
參考
Spark性能調優- 第二章:徹底解密Spark的HashShuffle
Hadoop shuffer 和 Spark shuffer區別


