
這次我們來說一下在Mysql中的編碼問題: 我們知道應用於電腦的最早的字元集是ASCII,它所組成的編碼是ASCII編碼;由於對於其他國家來說它所容納的字元個數比較少,後來就出現了ANSI字元集,它的編碼就是本地編碼,由於各個國家的本地編碼不相同,導致互相不相容,最後就出現了Unicode字元集, ...
這次我們來說一下在Mysql中的編碼問題:
我們知道應用於電腦的最早的字元集是ASCII,它所組成的編碼是ASCII編碼;由於對於其他國家來說它所容納的字元個數比較少,後來就出現了ANSI字元集,它的編碼就是本地編碼,由於各個國家的本地編碼不相同,導致互相不相容,最後就出現了Unicode字元集,它規定全世界通用一張碼表,用4個位元組來編號,但是我們常用的字元集中在前65535個編號里,用兩個位元組就夠了,那麼我們就可以簡化編碼,比如:
unicode用0000 0000 0000 0000 0000 0000 000 0041表示A
而我們可以用0000 0041來表示A
把高位浪費的0值,按照一定的規則捨棄掉,這樣形成的編碼方式是UTF方式,而最著名的就是UTF-8編碼方式。
簡單的形容Unicode與UTF-8 的關係:就像是原文件--->壓縮文件 的關係。UTF-8是一種變長的編碼方式,它編碼時所占的位元組如下圖所示:

而GBK則是中國漢字的一套編碼方式
那麼亂碼是如何形成的?
主要有兩點
- 解碼時與實際編碼不一致(可修複)
- 傳輸過程中,編碼不一致,導致位元組丟失(不可修複)
連接器的特性: 連接客戶端與伺服器
客戶端的字元先發給連接器,連接器選擇一種編碼將其轉換,臨時存儲,然後再次轉換成伺服器需要的編碼,並存儲在伺服器里。
要想不亂碼,需要指定客戶端的編碼,讓連接器不理解錯誤,這樣就不會存入錯誤數據,往回取的時候,我們還要告訴連接器,如果你從伺服器返回,應該返回什麼格式的編碼。
一共是三個參數,客戶端的發送的編碼,連接器使用的編碼,獲取的返回數據的編碼。
舉個例子:
當前的請況是,客戶端GBK,伺服器最終存UTF8
我明確的告訴伺服器:我的客戶端是GBK的:
Set character_set_client=gbk;

再告訴連接器,使用UTF8:
Set character_set_connection=utf8;

再告訴,如果返回值,請返回GBK的結果:
Set character_set_results=gbk;

如果我偏要對方給我返回的數據是UTF8:
Set character_set_results=utf8;
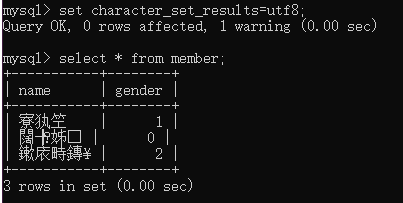
我們可以看到出現了亂碼,但是這些亂碼都是可以修複的
再來看另一種情況:
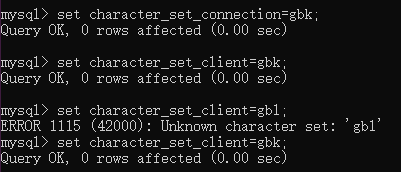
我先聲明客戶端,連接器,伺服器都是gbk格式:
我們插入一條數據,然後顯示它:
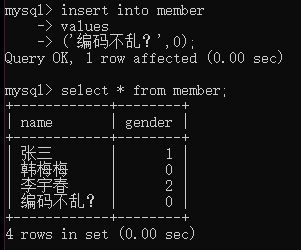
可以看出沒有亂碼;
我們再把連接器的編碼改成latin1:
Set character_set_client=latin1;

然後我們插入數據:

然後我們再顯示它:
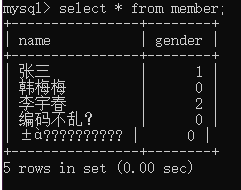
可以看到出現了亂碼,而且這種亂碼是不可修複的,latin1小,gbk大,就像大魚過小魚網,丟了塊肉。
因此要想不亂碼,必須使伺服器>=連接器>=客戶端
如果3者都是gbk,那麼就可以簡寫成set names gbk;
我們打開記事本,先輸入一個“聯通”,然後把它保存起來並關閉:
然後我們再次打開它

我們會發現它變成了亂碼。
其實這是因為記事本在打開的時候,它也不知道你用的是什麼編碼,它是靠分析編碼的特點來推測的,如果位元組比較少,就容易推測錯。
推薦鏈接:https://www.bilibili.com/video/av19538278/?p=41


