背景介紹 我們先來看一下為什麼要做集群,如果我們要部署一個單節點Redis,很明顯會遇到單點故障的問題。 首先能想到解決單點故障的方法,就是做主從,但是當有海量存儲需求時,單一的主從結構就會出問題,說問題之前要先瞭解一下主從之間是如何複製的。 我們把Redis分為三個部分,分別是客戶端、主節點以及從 ...
背景介紹
我們先來看一下為什麼要做集群,如果我們要部署一個單節點Redis,很明顯會遇到單點故障的問題。

首先能想到解決單點故障的方法,就是做主從,但是當有海量存儲需求時,單一的主從結構就會出問題,說問題之前要先瞭解一下主從之間是如何複製的。

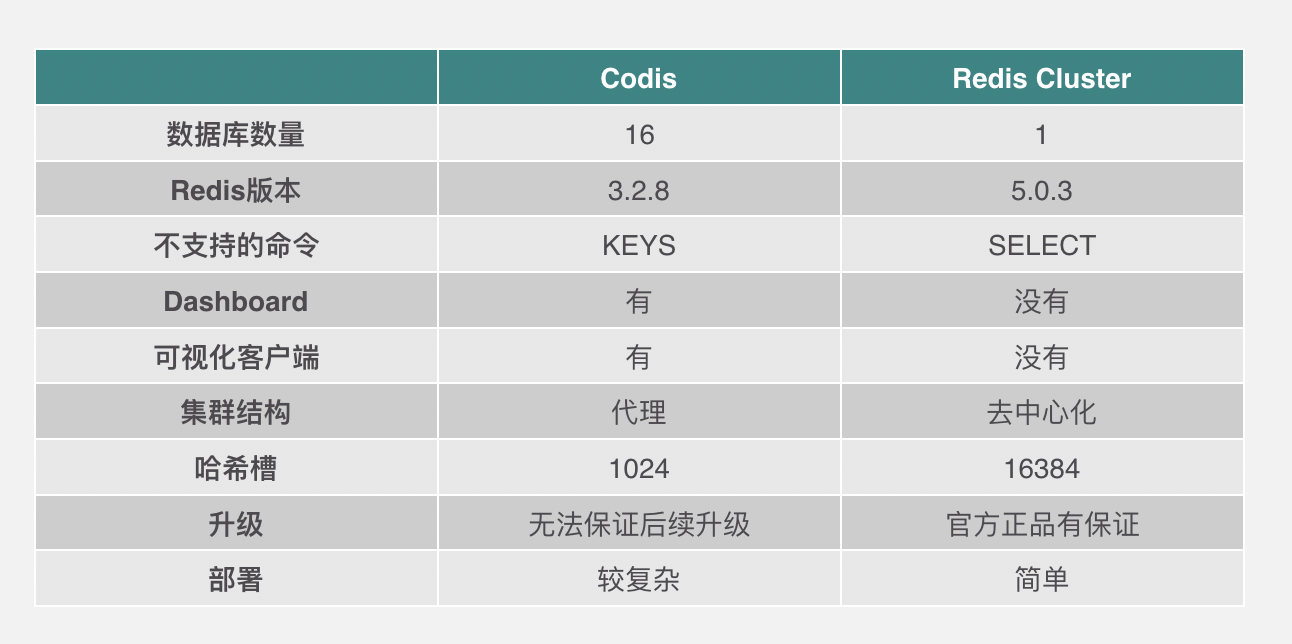
我們把Redis分為三個部分,分別是客戶端、主節點以及從節點,如果從節點要同步主節點的數據,它首先會發Sync指令給主節點,主節點收到指令之後會執行BGSAVE命令生成RDB文件,這個RDB文件指的是快照文件,它是Redis兩種備份方式的其中一種,另一種叫AOF,它的原理是將所有的寫入指令存入文件,mysql的binlog原理是一樣的。
如果主節點在生成RDB的過程當中,客戶端發來了寫入指令,這個時候主節點會把指令全部寫入緩衝區,等RDB生成完了,會把RDB文件發送給從節點,最後再把緩衝區的指令發送給從節點。這樣就完成了整個的複製。
我們剛纔說單純地做主從是有缺陷的,這個缺陷就是如果我們要存儲海量的數據,那麼BGSAVE指令生成的RDB文件會非常巨大,這個文件傳送給從節點也會非常慢,如果緩衝區命令很多的話,從節點同步數據時也會執行很久,所以,要解決單點問題和海量存儲問題,還是要考慮做集群。
Redis常見集群方案
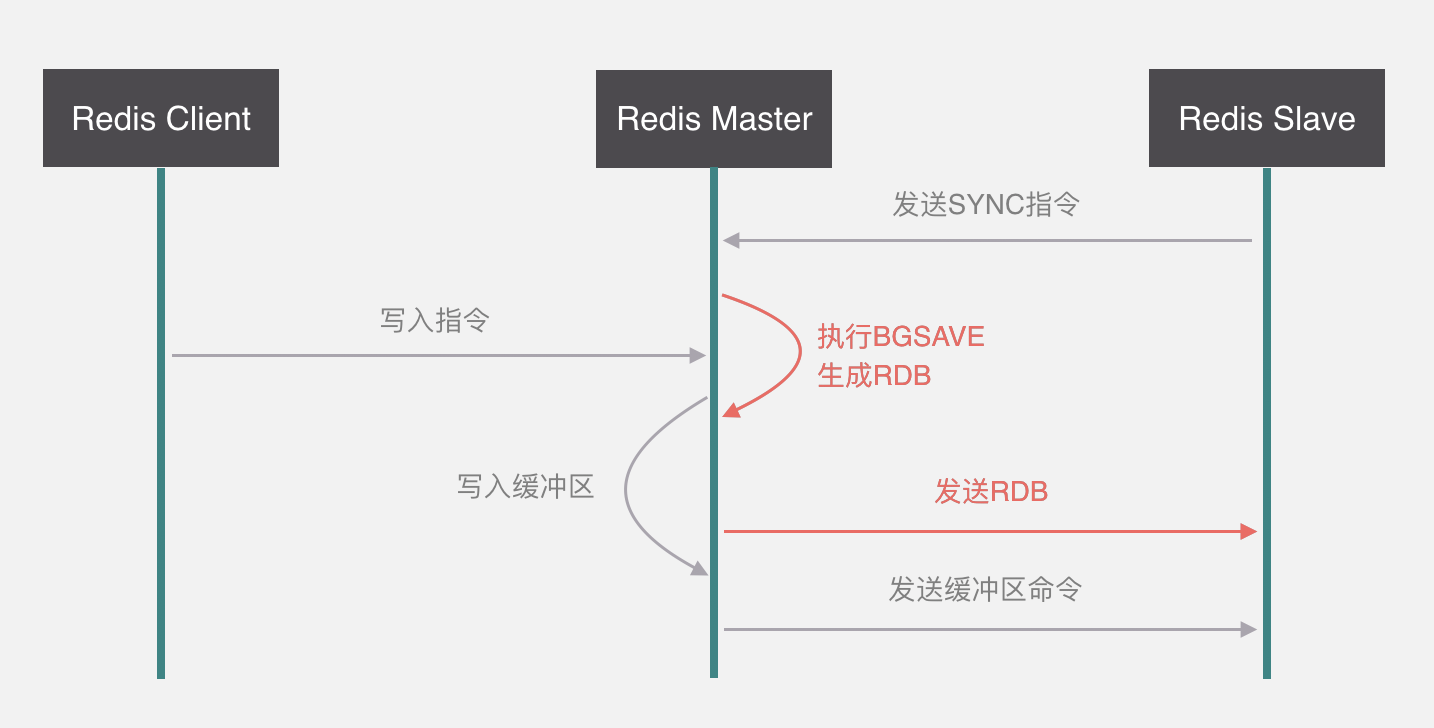
Redis集群方案目前主流的有三種,分別是Twemproxy、Codis和Redis Cluster。
Twemproxy,是推特開源的,它最大的缺點就是無法平滑的擴縮容,而Codis解決了Twemproxy擴縮容的問題,而且相容了Twemproxy,它是由豌豆莢開源的,和Twemproxy都是代理模式。其實Codis能發展起來的一個主要原因是它是在Redis官方集群方案漏洞百出的時候率先成熟穩定的。以現在的Redis官方集群方案,這兩個好像沒有太大差別了,不過我也沒有去做性能測試,不清楚哪個最好。
Redis Cluster是由官方出品的,用去中心化的方式實現,不屬於代理模式,今天主要講codis,redis cluster後面也會過一下。下麵,來看一下Codis的實現原理。
Codis原理
我們換一種方式去講,就按照Codis的架構演進一下,這樣理解會比較清晰一點,假如現在只有一個Redis Server,怎麼讓它變得高可用?

開篇的時候也有講,首先,能想到的就是做主從,這樣就算主宕機了,從節點也能馬上接替主節點的位置。
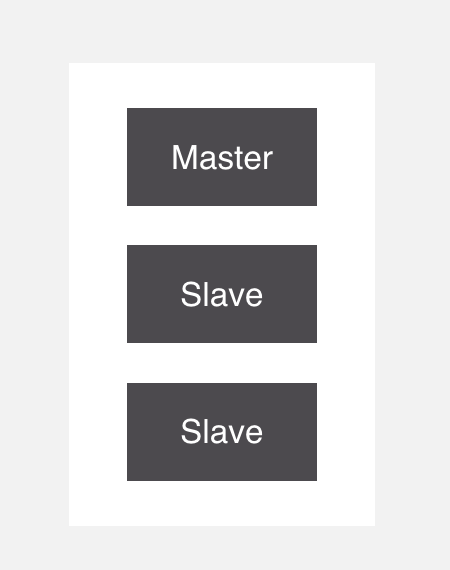
我們現在已經做成主從結構了,那到底是誰來負責主從之間的切換?
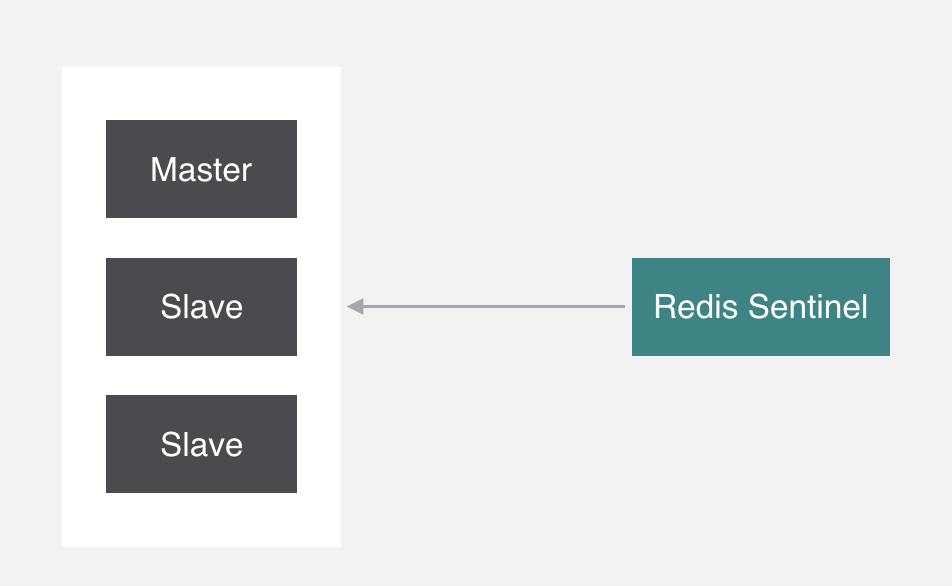
就是它,Sentinel,中文名叫哨兵,它呢,在Redis裡面主要負責監控主從節點,如果主節點掛了,就會把從拉起來。但是哨兵本身也存在單點問題,所以它也需要做集群。

那麼問題來了,哨兵是如何做主從切換呢?來看下哨兵的運行機制。

假如有三個哨兵和一主兩從的節點,下麵是一主多從,哨兵之間會互相監測運行狀態,並且會交換一下節點監測的狀態,同時哨兵也會監測主從節點的狀態。
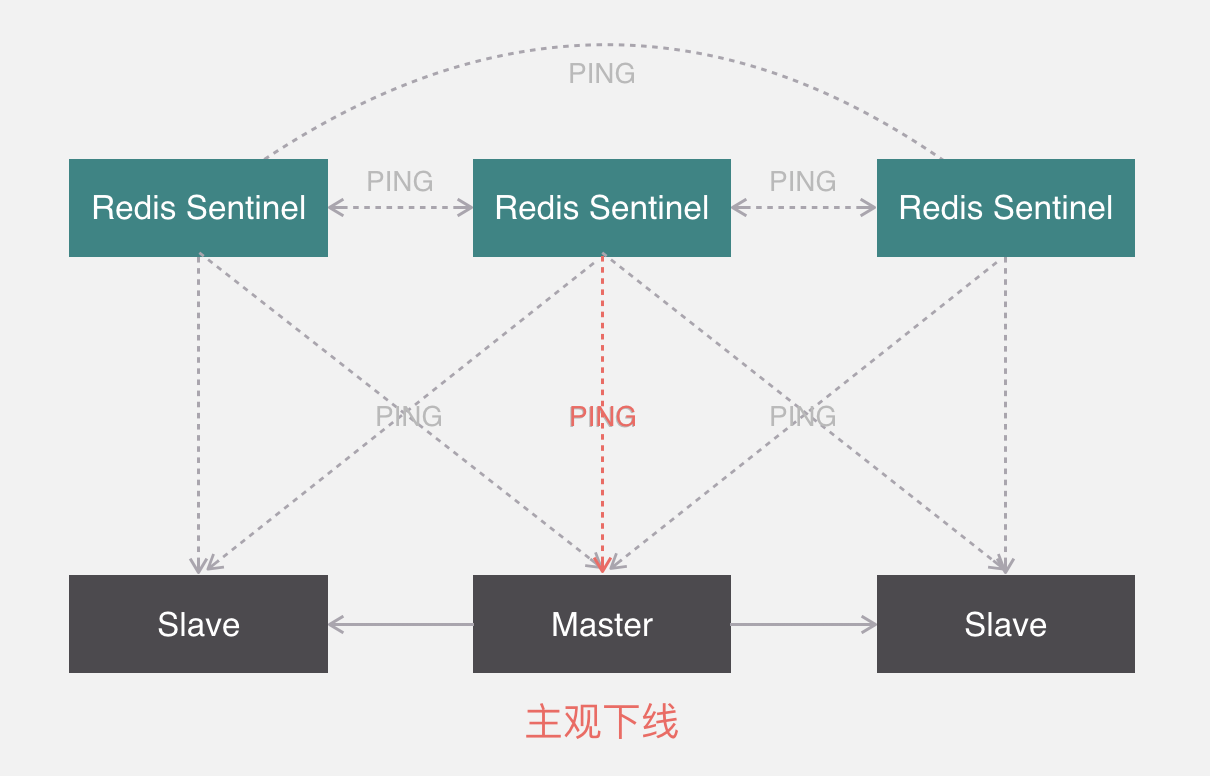
如果檢測到某一個節點沒有正常回覆,並且距離上次正常回覆的時間超過了某個閾值,那麼就認為該節點為主觀下線。
這個時候其他哨兵也會來監測該節點是不是真的主觀下線,如果有足夠多數量的哨兵都認為它確實主觀下線了,那麼它就會被標記為客觀下線,這個時候哨兵會找下線節點的從節點,然後與其他哨兵協商出一個從節點做主節點,並將剩餘的從節點指向新的主節點。
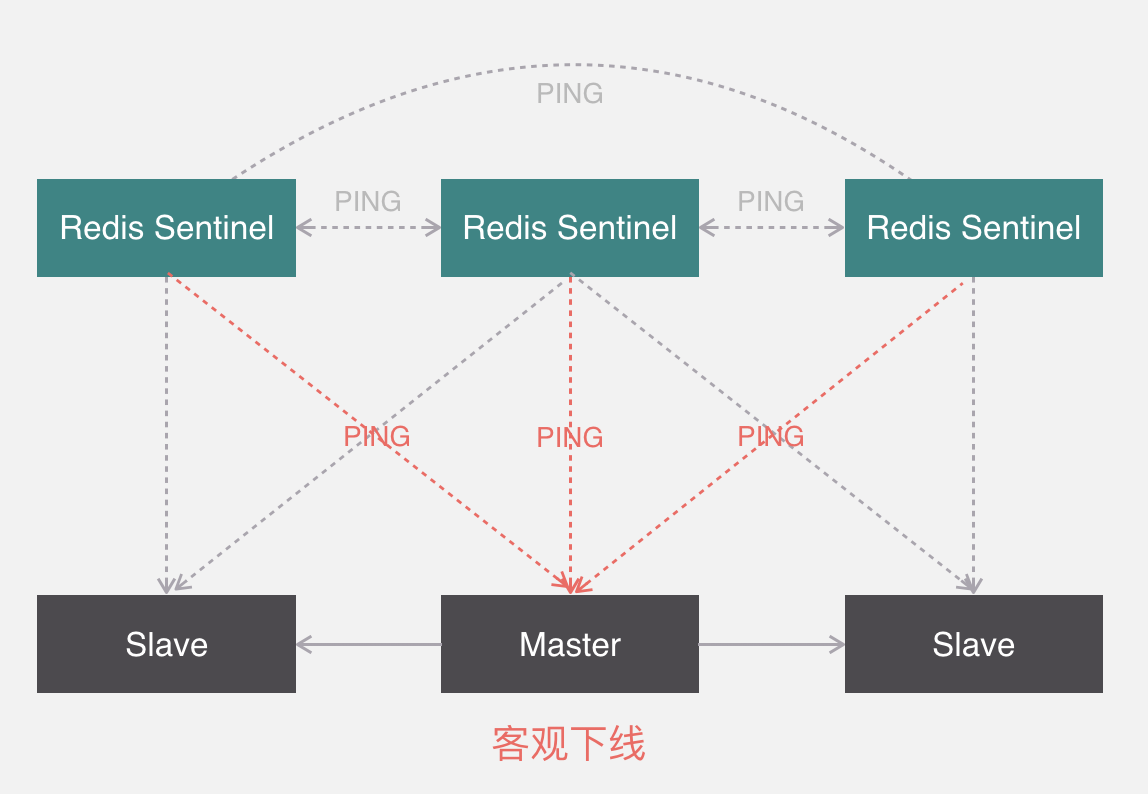
關於主從節點的切換有兩個環節,第一個是哨兵要選舉出領頭人來負責下線機器的故障轉移,第二是從Slave中選出主節點,領頭人的選舉規則是誰發現客觀下線誰就可以馬上要求其他哨兵認自己做老大,其他哨兵會無條件接受第一個發過來的人,並告知老大,如果超過一半人都同意了,那他老大的位置就坐實了。
關於從節點選舉,一共有四個因素影響選舉的結果,分別是斷開連接時長、優先順序排序、複製數量、進程id,如果連接斷開的比較久,超過了某個閾值,就直接失去了選舉權,如果擁有選舉權,那就看誰的優先順序高,這個在配置文件里可以設置,數值越小優先順序越高,如果優先順序相同,就看誰從master中複製的數據最多,選最多的那個,如果複製數量也相同,就選擇進程id最小的那個。

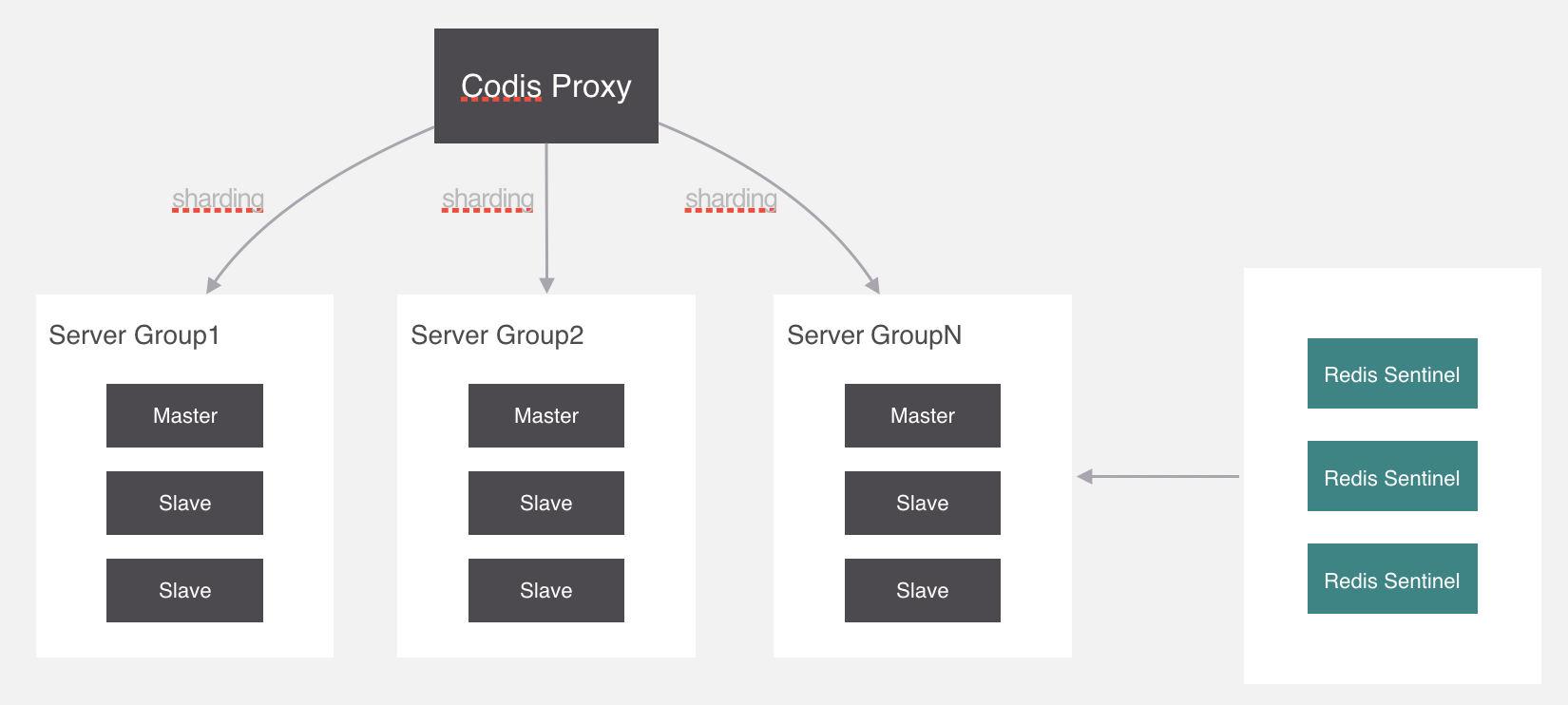
現在繼續回過來,剛纔講痛點的時候說了,如果有存儲海量數據的需求,同步會非常緩慢,所以我們應該把一個主從結構變成多個,把存儲的key分攤到各個主從結構中來分擔壓力。
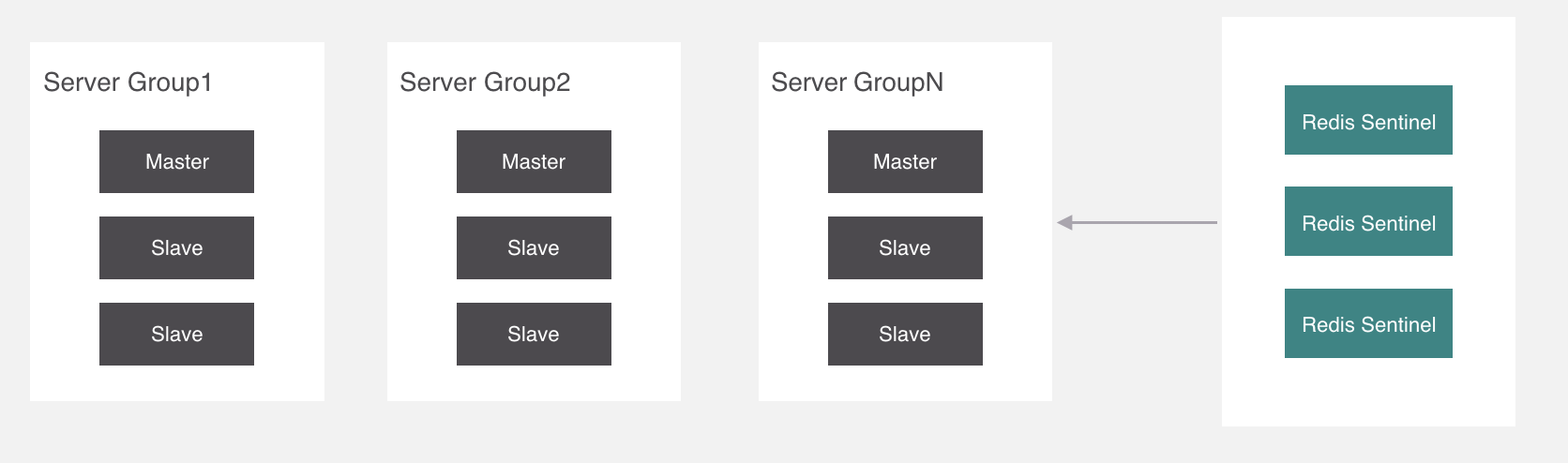
就像這樣,代理通過一種演算法把要操作的key經過計算後分配到各個組中,這個過程叫做分片,我們來看一下分片的實現原理。
分片演算法
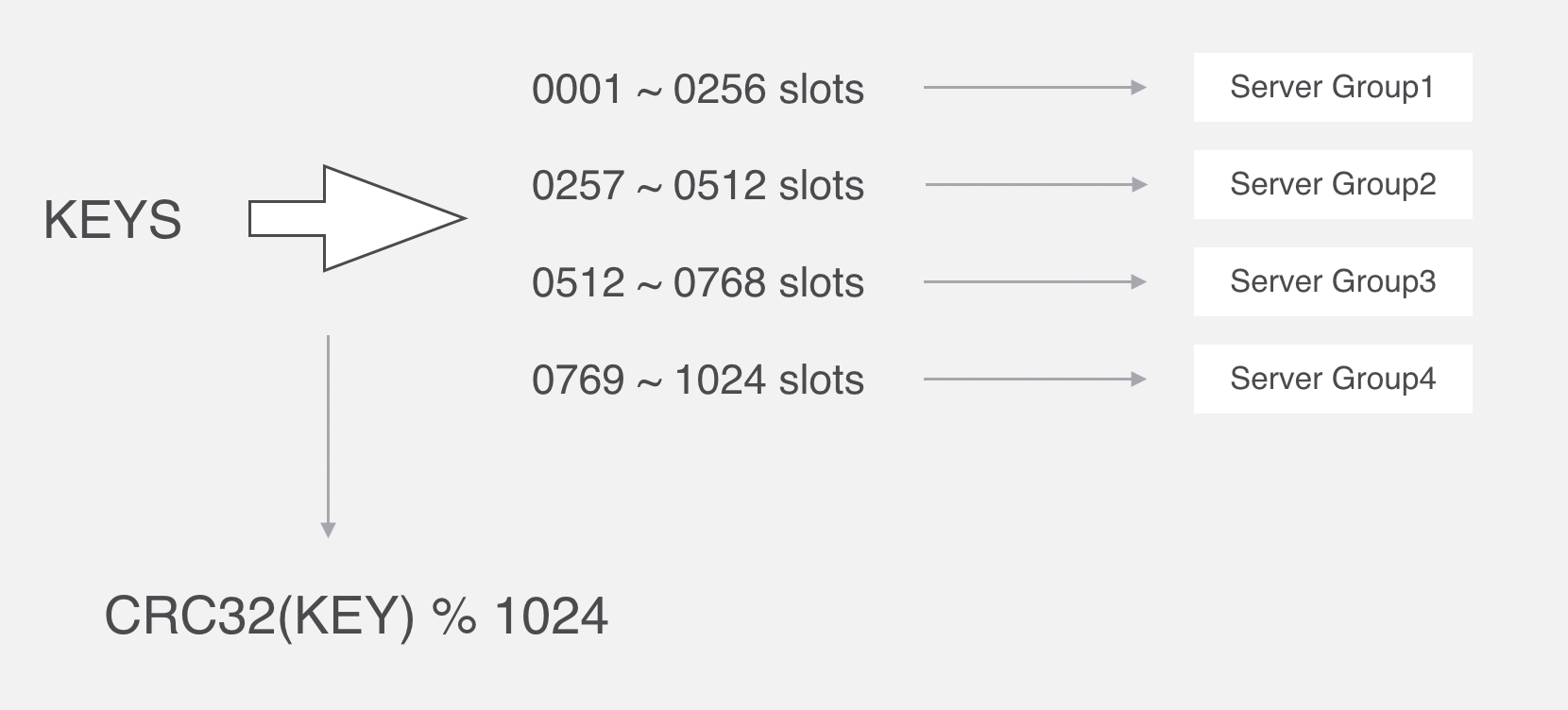
在Codis裡面,它把所有的key分為1024個槽,每一個槽位都對應了一個分組,具體槽位的分配,可以進行自定義,現在如果有一個key進來,首先要根據CRC32演算法,針對key算出32位的哈希值,然後除以1024取餘,然後就能算出這個KEY屬於哪個槽,然後根據槽與分組的映射關係,就能去對應的分組當中處理數據了。
CRC全稱是迴圈冗餘校驗,主要在數據存儲和通信領域保證數據正確性的校驗手段,我去看了這個演算法的原理,還沒理解透徹,這裡就先不講了,省得誤導大家。
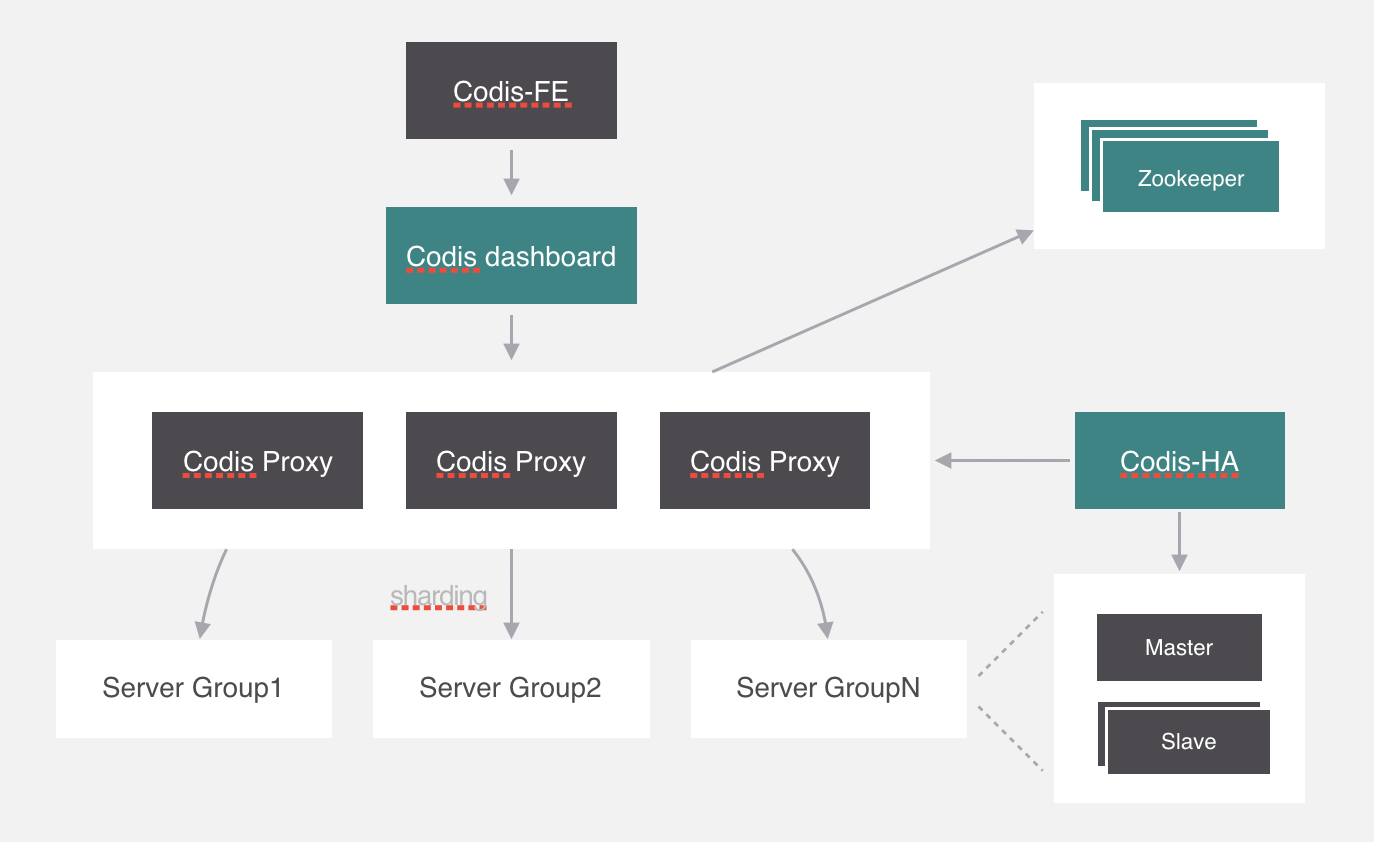
我們繼續回過來,剛纔所講的槽位和分組的映射關係就保存在codis proxy當中,但是codis proxy它本身也存在單點問題,所以需要對proxy做一個集群。

部署好集群之後,有一個問題,就是槽位的映射關係是保存在proxy裡面的,不同proxy之間怎麼同步映射關係?
在Codis中使用的是Zookeeper來保存映射關係,由proxy上來同步配置信息,其實它支持的不止zookeeper,還有etcd和本地文件。在zookeeper中保存的數據格式就是這個樣子。除了這個還會存儲一些其他的信息,比如分組信息、代理信息等,感興趣可以自己去瞭解一下。

現在還有一個問題,就是codis proxy如果出現異常怎麼處理,這個可能要利用一下k8s中pod的特性,在k8s裡面可以設置pod冗餘的數量,k8s會嚴格保證啟動的數量與設置一致,所以只需要一個進程監測Proxy的異常,並且把它幹掉就可以了,k8s會自動拉起來一個新的proxy。
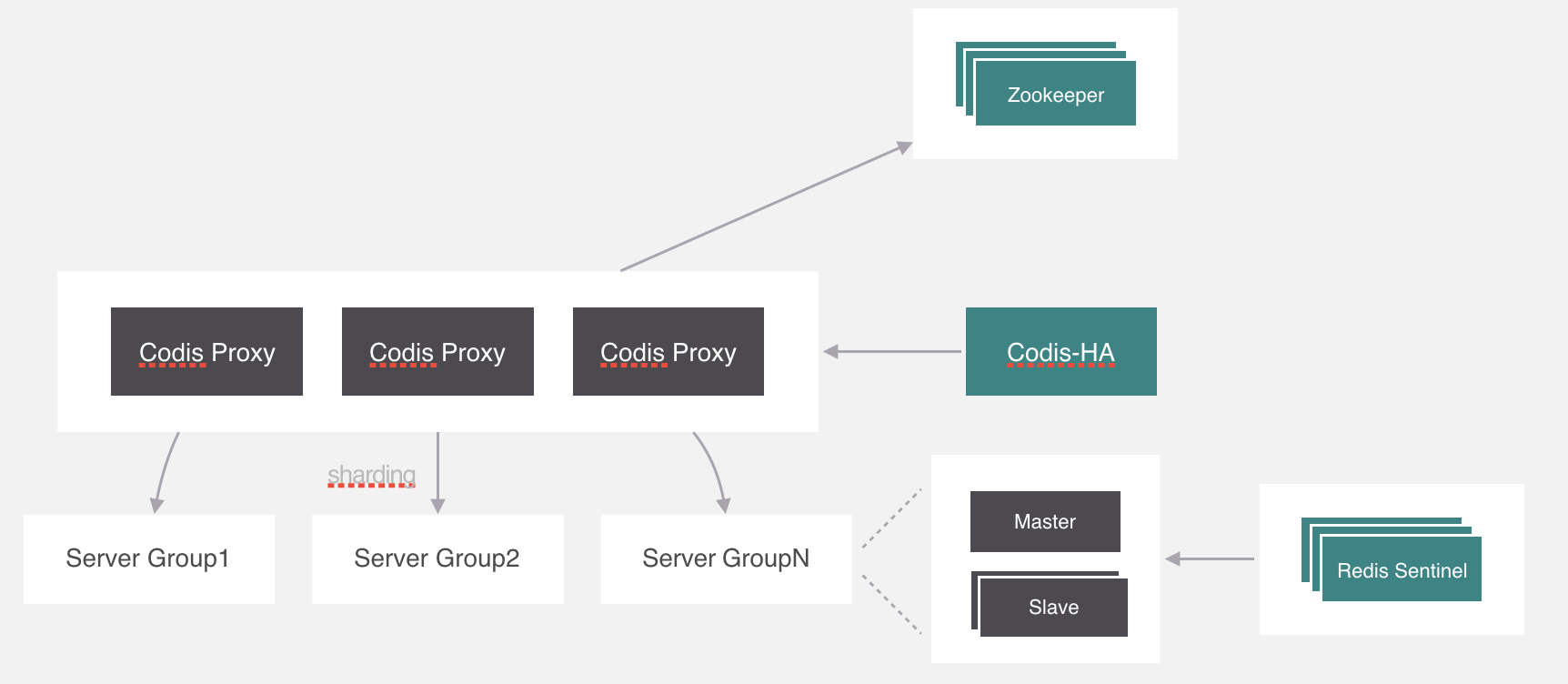
codis給這個進程起名叫codis-ha,codis-ha實時監測proxy的運行狀態,如果有異常就會幹掉,它包含了哨兵的功能,所以豌豆莢直接把哨兵去掉了。
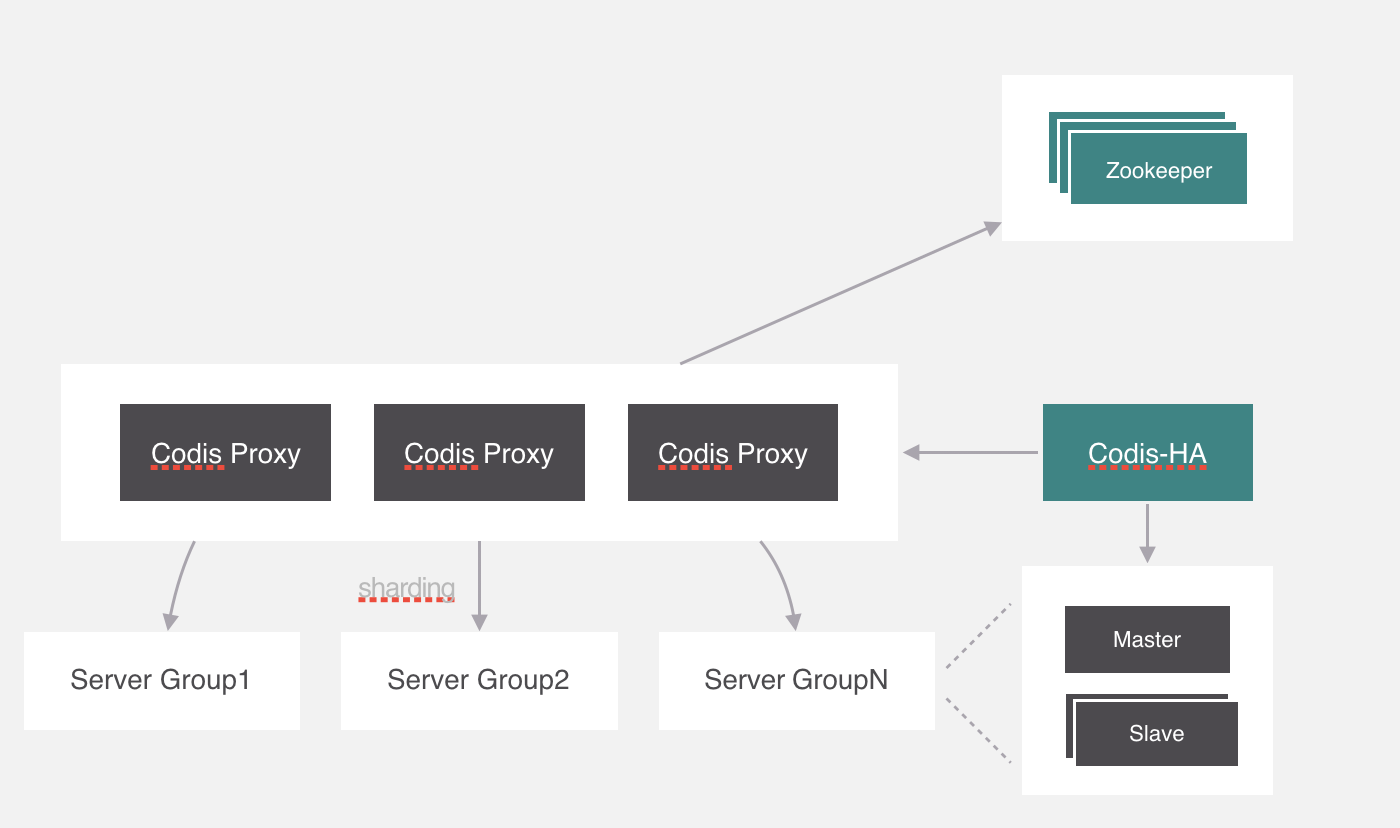
但是codis-ha在Codis整個架構中是沒有辦法直接操作代理和服務,因為所有的代理和服務的操作都要經過dashboard處理。所以部署的時候會利用k8s的親和性將codis-ha與dashboard部署在同一個節點上。

除了這些,codis自己開發了集群管理界面,集群管理可以通過界面化的方式更方便的管理集群,這個模塊叫codis-fe,我們可以看一下這個界面。
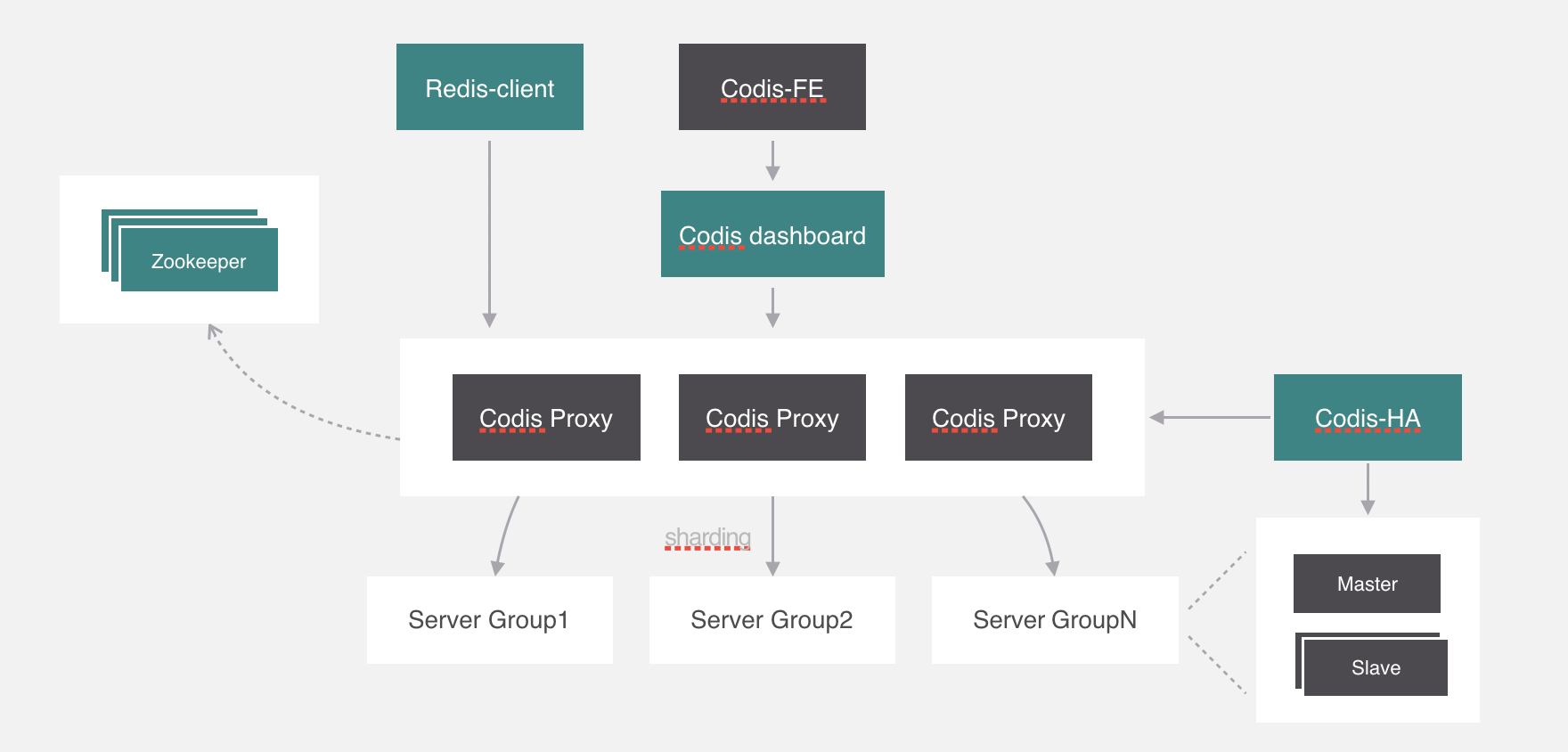
最後就是redis客戶端了,這個沒什麼好講的,客戶端是直接通過代理來訪問後端服務的。
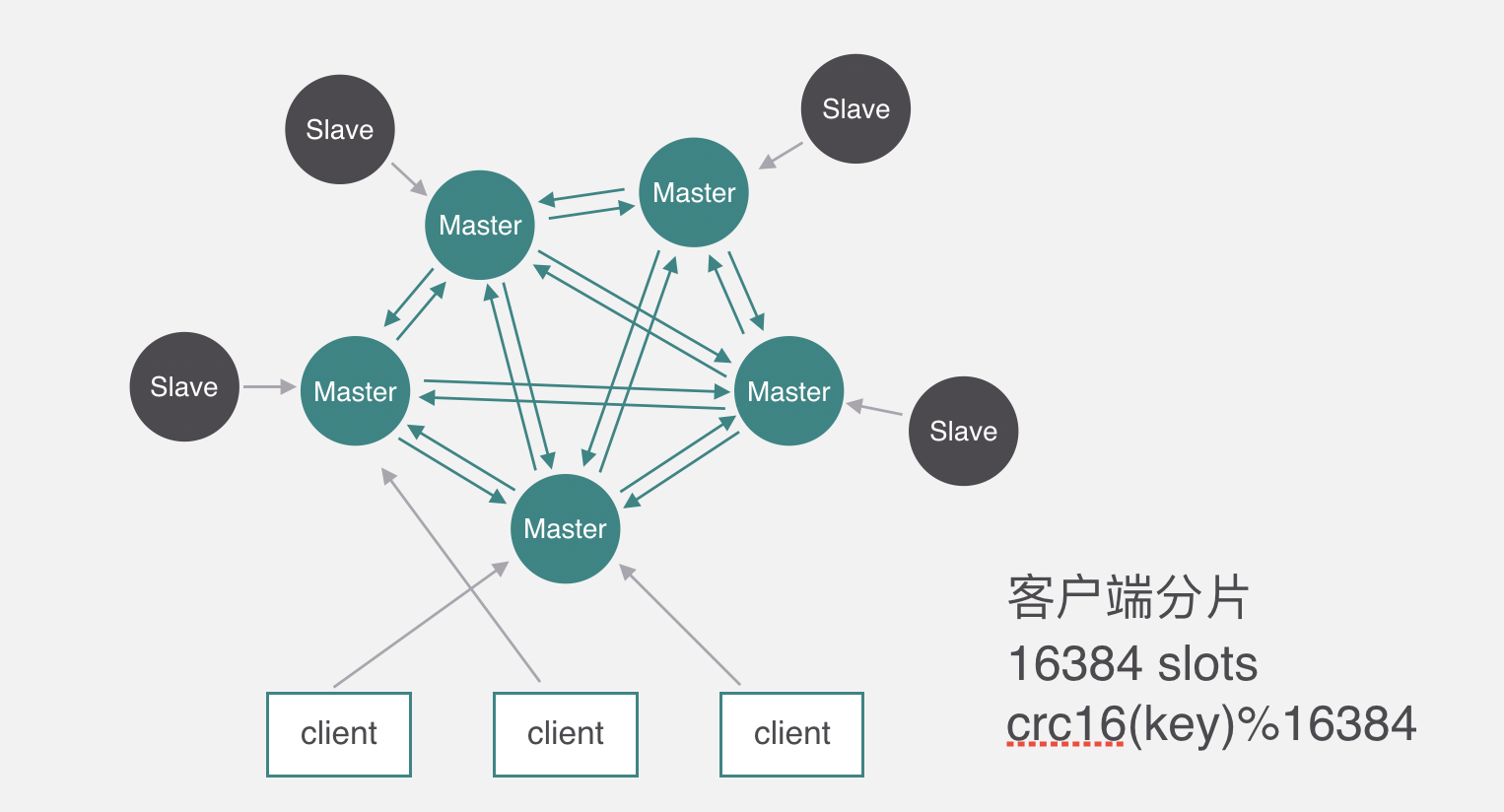
Redis Cluster原理
下麵來看一下redis cluster的原理,它和codis不太一樣,Codis它是通過代理分片的,但是Redis Cluster是去中心化的沒有代理,所以只能通過客戶端分片,它分片的槽數跟Codis不太一樣,Codis是1024個,而Redis cluster有16384個,槽跟節點的映射關係保存在每個節點上,每個節點每秒鐘會ping十次其他幾個最久沒通信的節點,其他節點也是一樣的原理互相PING ,PING的時候一個是判斷其他節點有沒有問題,另一個是順便交換一下當前集群的節點信息、包括槽與節點映射的關係等。客戶端操作key的時候先通過分片演算法算出所屬的槽,然後隨機找一個服務端請求。
但是可能這個槽並不歸隨機找的這個節點管,節點如果發現不歸自己管,就會返回一個MOVED ERROR通知,引導客戶端去正確的節點訪問,這個時候客戶端就會去正確的節點操作數據。
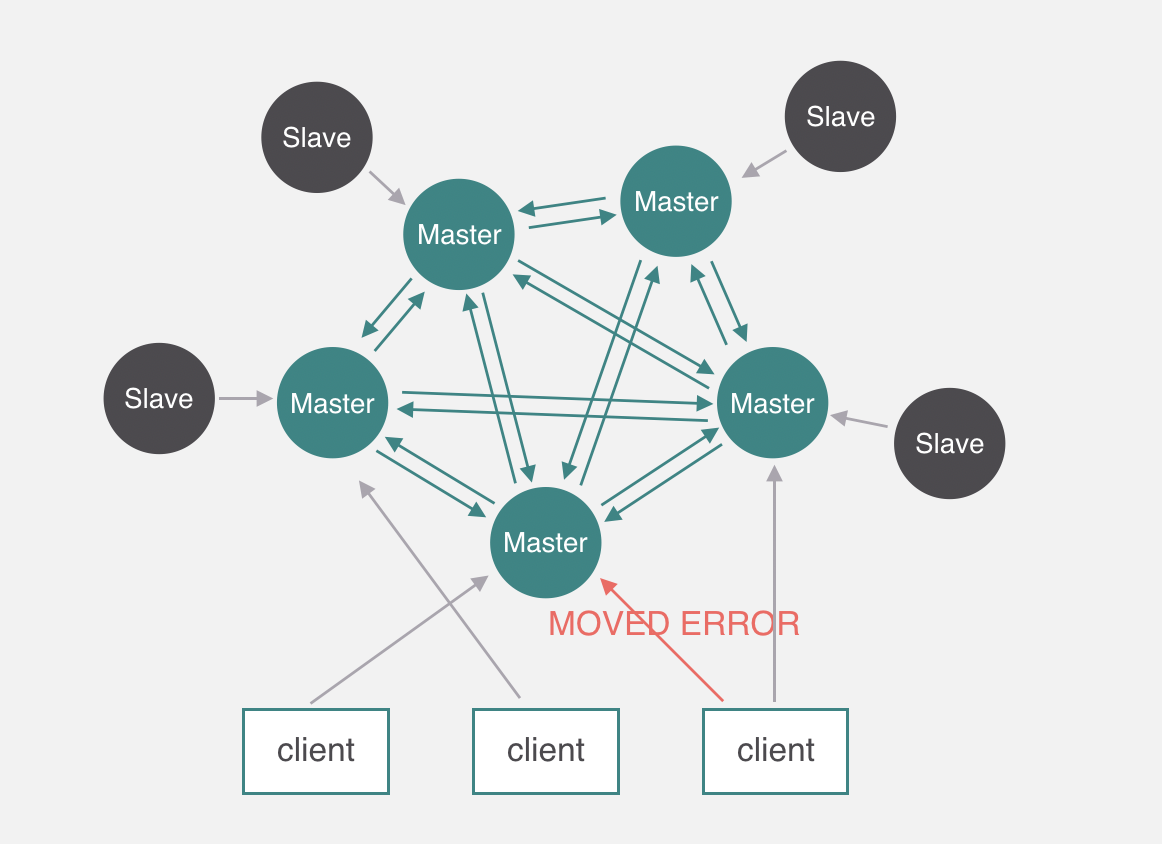
這是RedisCluster大概的原理,下麵看一下Codis跟RedisCluster簡要的區別。