
當一切正常時,沒有必要特別留意什麼是事務日誌,它是如何工作的。你只要確保每個資料庫都有正確的備份。當出現問題時,事務日誌的理解對於採取修正操作是重要的,尤其在需要緊急恢複數據庫到指定點時。這系列文章會告訴你每個DBA應該知道的具體細節。對於日誌文件的最大日誌吞吐量,我們從存儲架構思路的簡單回顧開始,...
當一切正常時,沒有必要特別留意什麼是事務日誌,它是如何工作的。你只要確保每個資料庫都有正確的備份。當出現問題時,事務日誌的理解對於採取修正操作是重要的,尤其在需要緊急恢複數據庫到指定點時。這系列文章會告訴你每個DBA應該知道的具體細節。
對於日誌文件的最大日誌吞吐量,我們從存儲架構思路的簡單回顧開始,然後進一步看下日誌碎片如何影響需要日誌讀取操作的性能,例如日誌備份,或者故障恢復過程。
最後,我們會談下在日誌大小和增長管理的最佳實踐,還有對過渡日誌增長和碎片的正確處理。
物理架構
正確的物理硬體和架構會幫你保證日誌吞吐量的最大可能,還有一些“黃金法則”。在這之前,已經有人談過了,尤其是Kimberly Tripp在她的《8步走向更好的事務日誌吞吐》里,因此在這裡不會更深入的探討這個話題。
要註意的是,對於日誌文件,在設計內在物理結構時,我們的首要目標是最優日誌寫吞吐量。對於每個添加、刪除或修改數據的事務,SQL Server寫入日誌,這也包括資料庫維護操作,例如索引重建或重組,統計信息更新等等。
你只需要一個日誌文件
從多個日誌文件,在日誌吞吐量方面,不會獲得性能。SQL Server不會並行寫入多個日誌文件。只有一個情況SQL Server會寫入所有日誌文件,那是當在每個日誌文件里更新文件頭時,SQL Server寫入它來更新不同的LSN,例如最後檢查點,最早打開的事務,最後一次日誌備份等等。當只更新文件頭時,很多人會誤認為SQL Server會寫入所有日誌文件。
如果一個資料庫有4個日誌文件,SQL Server會寫入日誌到日誌文件1,直到滿了,然後日誌文件2,日誌文件3和日誌文件4,然後嘗試繞回重新寫入日誌文件1。我們可以通過創建有多個日誌文件(或通過對現存資料庫增加更多文件)的資料庫來驗證下。代碼8.1創建一個Person資料庫,有1個主數據文件和2個日誌文件,每個在不同的硬碟上。
數據和備份文件位置
這篇文章里的例子都假設數據和日誌文件位於D:\SQLData,所有備份位於:D:\SQLBackups,各自不同的位置。當運行這些例子時,直接修改這些位置到你系統合適的位置(並且註意,在實際的系統中,我們不會在同個硬碟上存儲數據和日誌文件)。
註意對於這些數據和日誌文件的大小和文件增長率設置,我們是基於AdventureWorks2008的:
1 USE master 2 GO 3 IF DB_ID('Persons') IS NOT NULL 4 DROP DATABASE Persons; 5 GO 6 7 CREATE DATABASE [Persons] ON PRIMARY 8 ( NAME = N'Persons' 9 , FILENAME = N'D:\SQLData\Persons.mdf' 10 , SIZE = 199680KB 11 , FILEGROWTH = 16384KB 12 ) 13 LOG ON 14 ( NAME = N'Persons_log' 15 , FILENAME = N'D:\SQLData\Persons_log.ldf' 16 , SIZE = 2048KB 17 , FILEGROWTH = 16384KB 18 ), 19 ( NAME = N'Persons_log2' 20 , FILENAME = N'C:\SQLData\Persons_log2.ldf' 21 , SIZE = 2048KB 22 , FILEGROWTH = 16384KB 23 ) 24 GO 25 26 ALTER DATABASE Persons SET RECOVERY FULL; 27 28 USE master 29 GO 30 BACKUP DATABASE Persons 31 TO DISK ='D:\SQLBackups\Persons_full.bak' 32 WITH INIT; 33 GO
代碼8.1:創建有2個日誌文件的Persons資料庫。
接下來,代碼8.2創建一個範例Persons表。
1 USE Persons 2 GO 3 IF EXISTS ( SELECT * 4 FROM sys.objects 5 WHERE object_id = OBJECT_ID(N'dbo.Persons') 6 AND type = N'U' ) 7 DROP TABLE dbo.Persons; 8 GO 9 10 CREATE TABLE dbo.Persons 11 ( 12 PersonID INT NOT NULL 13 IDENTITY , 14 FName VARCHAR(20) NOT NULL , 15 LName VARCHAR(30) NOT NULL , 16 Email VARCHAR(7000) NOT NULL 17 ); 18 GO
代碼8.2:創建Persions表。
現在,我們會增加15000行到表,並運行DBCC LOGINFO。註意在我們的測試里,我們從AdventureWorks2005資料庫里的Person.Contact表裡的數據來插入。你也可以使用AdventureWorks2008或AdventureWorks2012資料庫。
1 INSERT INTO dbo.Persons 2 ( FName , 3 LName , 4 Email 5 ) 6 SELECT TOP 15000 7 LEFT(aw1.FirstName, 20) , 8 LEFT(aw1.LastName, 30) , 9 aw1.EmailAddress 10 FROM AdventureWorks2005.Person.Contact aw1 11 CROSS JOIN AdventureWorks2005.Person.Contact aw2; 12 GO 13 14 USE Persons 15 GO 16 DBCC LOGINFO;
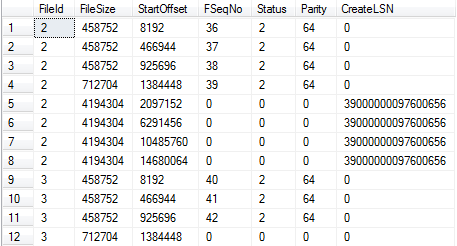
代碼8.3:插入數據並檢查VLF
SQL Server在主日誌文件里(日誌文件2)連續插入VLF,接下來插入第2個日誌文件(日誌文件3)。而且自動增長了主日誌文件(SQL Server如何自動增長事務日誌的,可以查看這個系列的第2篇文章)。
如果我們繼續增加記錄。SQL Server會繼續增長需要的2個文件,按順序填充VLF,一次一個VLF。圖8.1展示在重新運行代碼8.3,增加95000行後的情形(合計增加了110000行)。現在對於主日誌文件,我們有12個VLF,對於第2個日誌文件我們有8個VLF。
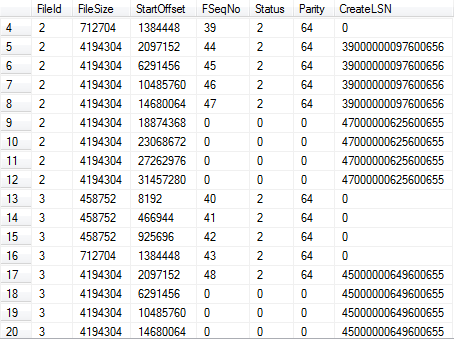
圖8.12個日誌文件的連續使用。
在這個情況里,讀取日誌的任何操作都會始於主日誌里的4個VLF塊開始(FSeqNo 36-39),接下來在第2個日誌文件里的4個塊(FSeqNo 40-43),再接下來是主日誌里的4個塊,以此迴圈。這是為什麼多個日誌文件會降低I/O效率,我們會在下個環節進一步討論。
增加額外日誌文件的唯一原因是一個例外場景,例如,磁碟上的日誌文件滿了(看下第6篇),我們又臨時需要日誌空間,增加額外日誌文件是我們讓SQL Server退出只讀模式的最快方法。但是,一旦額外文件不需要後我們應該將它移除,我們稍後會討論,在 如果出錯了我們該怎麼辦 部分。
對於日誌文件使用專用硬碟/磁碟陣列
把數據文件與日誌文件分別放在不同的硬碟,有很多理由來解釋它為什麼是個很好的做法。首先,在硬碟故障時,這個架構提供更好的恢復機會。例如,如果存儲數據文件的陣列遭受災難性故障,但日誌文件不會和它一起沉船。我們還是有機會進行尾日誌備份,把資料庫恢復到非常接近災難發生的時間點(看下第5篇)。
其次,分離數據文件I/O和日誌文件I/O可以用來優化I/O效率。SQL Server資料庫同時進行隨機和順序I/O操作。順序I/O是SQL Server可以讀寫塊,而不需要請求磁碟上磁頭的重新定位。SQL Server使用順序I/O進行預讀操作,還有所有的事務日誌操作,使用傳統硬碟來說,它是最快的I/O類型。
隨機I/O是讀寫塊時,需要請求磁碟頭改變在磁碟上的位置。這會導致尋求延遲I/O,相對順序I/O,同時降低輸出(MB/s)和性能(IOPS)。一般來說讀操作,尤其在OLTP系統里,是隨機I/O,順序讀取相關的頁小塊是隨機I/O請求的一小部分。
從主順序I/O里分離主要的隨機I/O,我們避免了2者之間的衝突,提高全局的I/O效率。更進一步,對於日誌文件的優化配置並不必和數據文件一樣。通過分離數據和日誌文件,我們可以針對I/O活動類型為每個I/O子系統進行合適配置。例如,選擇優化的RAID配置作為磁碟陣列(下一部分會詳談)。
最後,要提的是在專門磁碟/陣列上的單個日誌文件允許磁頭保持剛好穩定,因為SQL Server是順序寫入日誌的。但是,在單個磁碟/陣列上的多個日誌文件,磁頭會在每個日誌間跳躍;我們沒有順序寫入,沒有磁碟搜索的話,因此我們降低了順序I/O的效率。
理想的情況,每個資料庫都應該在專門的磁碟陣列上有一個日誌文件,但是很多系統這個並不現實,只是個理想。
由於同樣的原因,與順序I/O效率相關,在我們創建日誌文件前,我們要對物理硬碟磁碟碎片整理下,這非常重要。
可能的話,對於日誌硬碟,使用RAID 10
RAID,獨立磁碟冗餘陣列(Redundant Array of Independent Disks)的縮寫,是用來實現下列目標的技術:
- 提高I/O性能級別,用每秒輸入/輸出操作衡量(Input/Output Operations Per Second(IOPS)),單位大致是(MB/秒/IO以KB為單位的大小)*1024
- 提高I/O吞吐量,用MB/秒來衡量,單位大致是(IOPS * IO以KB為單位的大小)/1024
- 提高在單個硬碟里的可用存儲量——你現在還不能購買5TB的單個硬碟,但你可以通過在RAID 5陣列里的6個1TB的硬碟,在操作系統里擁有5TB的硬碟。
- 獲得數據冗餘,通過在多個硬碟分佈存儲部分信息,或者在陣列里使用物理硬碟鏡像。
RAID級別的選擇很大程度上取決於磁碟必須支持的工作量,如剛纔討論的,對於數據和日誌文件的具體不同I/O工作量,意味著在每個情況下會有不同的RAID配置。
在I/O吞吐量和性能方面,我們應該努力優化日誌文件陣列的順序寫。很多專家認為RAID 1 + 0就這一點而言是最佳選擇,儘管這個是以GB存儲空間最貴花費。
深入RAID
每個RAID級別優劣的完整參考不是這個系列文章的討論範圍。瞭解更多信息,我們請你參考《SQL Server故障排除(Troubleshooting SQL Server)》的第2章。
RAID 1+0是個內嵌的RAID,被稱為“鏡像條帶 ”。它通過每個硬碟的第一鏡像提供冗餘,即RAID 1,然後使用RAID 0條帶化這些鏡像硬碟來提高性能。由於只有磁碟的一半空間可以使用,所以會大大增加成本。然後,這個配置提高冗餘的最佳配置,因為即使多個硬碟損壞,系統還是正常運行的,也不會降低系統性能。
常見的更實惠的備用方法是RAID 5,"部分條帶",在多個硬碟間條帶數據,如RAID 0,只存儲部分數據,提供單個磁碟損壞保護。對於同樣的存儲,與RAID 1 + 0比,RAID 5需要更少的磁碟,且提供優異的讀性能。但是,維護部分化數據引發了寫性能上的損失。對於當下的存儲陣列,這隻是個小問題,這是對於事務日誌文件,很多DBA不推薦它的原因,因為它主要進行的是順序寫,要求最小可能的寫延遲。
假設,如我們剛纔建議的,你能隔離每個資料庫日誌文件在特定的磁碟陣列,至少對於那些有最大I/O工作量的資料庫,對於這些陣列是可以使用更昂貴的RAID 1 + 0,對於更小I/O工作量的資料庫可以使用RAID 5或RAID 1。
瞭解下不同RAID級別提供的I/O性能的情況,邪獵的3個可用配置是針對進行混合隨機讀寫操作性能平衡的400G的資料庫,對於SQL Server,連同理論上的I/O輸出率,基於64K的隨機I/O工作量。
- RAID 1使用1個15K RPM的600G硬碟=>11.5MB/秒,185 IOPS
- RAID 5使用5個15K RPM的146G硬碟=>22MB/秒,345 IOPS
- RAID 1 0使用14個15K RPM的73G硬碟=>101M/秒,1609 IOPS
請註意,這些值都是理論上的,在給出配置里盡基於硬碟的潛在I/O工作量。不考慮其他可能因素,對全局的工作量的影響,包括RAID控制器緩存大小和配置,RAID條帶大小,硬碟分區對齊,NTF格式分配單元大小。確保你選擇硬碟配置的唯一方法要處理好工作量位置,即對你的資料庫的I/O子系統進行合適的基準驗證,尤其是使用率。
對SQL Server進行存儲配置基準驗證
對給出的配置有很多現存的工具進行I/O輸出的衡量,最常用的工具是SQLIO和IOmeter。另外,還有SQLIOSim,用來測試磁碟配置的可靠性和完整性。
日誌碎片和讀取日誌操作
如第2篇所談的,在內部SQL Server把日誌文件分割為多個子文件,即所謂的虛擬日誌文件(VLF)。對於一個日誌文件,在創建時,SQL Server決定分配給它的VLF的個數的大小,每次日誌增加時,然後增加決定好的VLF個數,基於自動增長率的大小,如下所示(儘管對於很小的增長率,有時候增加的VLF會小於4個):
- 小於64MB——每次自動增加會創建4個新的VLF
- 64MB至1GB——8個VLF
- 大於1GB——16個VLF
例如,如果我們創建一個64MB的日誌文件,設置增長率是16MB,那麼日誌文件初始會有8個VLF,每個8MB大小,每次日誌增長時,SQL Server會增加4個VLF,每個4MB大小。如果資料庫吸引了比預期更多的用戶,但是文件設置還是保持不變,當日誌增長到10GB大小,增長了640倍時,會有超過2500個VLF。
另一方面,如果日誌16GB大小,那麼每次增長會增加16個VLF,每個1GB大小。使用大的VLF,我們會占用日誌的大部分,SQL Server不能截斷,如果一些因素進一步延遲截斷,意味這日誌還要增長,增長得更快。
秘訣是保持正確的平衡。推薦的最大增長大小是8GB(Paul Randal在他的《日誌文件內部和維護》視頻里建議的)。相反的,增長率必須足夠大來避免不合理太多的VLF個數。
有2個主要原因來避免頻繁小的日誌增長。一個如在第7篇里談到的,日誌文件不能獲得即時文件初始化的優勢,因此在資源來說,和數據文件增長比,日誌增長會相對昂貴。另一個是碎片日誌會妨礙讀取日誌操作的性能。
很多操作會需要讀取事務日誌,包括:
- 完整,差異和日誌備份——儘管只有後來會讀取大量的日誌部分。
- 故障恢復過程——為了保持數據和日誌的一致性,撤銷任何沒有提交的事務,重做任何已經提交,寫入日誌但沒有寫入數據文件的事務(參考第1篇)
- 事務複製——當從發佈者到訂閱者移動修改時,事務複製日誌閱讀器讀取日誌
- 資料庫鏡像——在鏡像資料庫上,當從主到鏡像傳送最近的改變時,日誌會被讀取
- 創建資料庫快照——在運行故障恢復過程時需要讀取日誌
- DBCC CHECKDB——當它運行時會創建資料庫快照
- 修改數據抓取——使用事務複製日誌閱讀起來跟蹤數據修改
最後,在一個日誌文件里多少個VLF才合適的問題取決與日誌的大小。通常,微軟認為超過200個VLF可能會有問題,但在一個非常大的日誌文件(例如500GB)只有200個VLF也會是個問題,VLF太大,限制了空間重用。
為了瞭解在日誌讀取時,碎片日誌大小的影響,我們會運行一些測試,來看看在廣泛閱讀日誌的兩個過程的影響,即日誌備份和故障恢復過程。
免責申明
接下來的測試無法反應現實中在伺服器級別硬體上運行的多用戶資料庫,上面有特定的RAID配置等等。我們在安裝在虛擬機上,獨立的SQL Server 2008實例上運行。你的數據會不同,在速度慢的硬碟上測試效果會更明顯。我們只想簡單的演示下日誌碎片問題的影響,還有如何調查這些潛在影響的方法。
最後註意,Linchi Shea已經演示了一個只有16個VLF和2000個VLF之間,數據修改性能上的影響。
日誌備份影響
為了瞭解在日誌備份上,碎片日誌影響的大小,我們會創建PersonsLots資料庫,故意創建一個小的2M日誌文件,強制它在非常小的增長率來創建特別的碎片日誌。我們會插入一些數據,運行大的更新來生成很多日誌記錄,然後運行日誌備份來看看會花多少時間。然後我們在預製好正確大小的日誌文件進行同樣的測試。
首先,我們創建PersonsLots資料庫,日誌文件只有2M大小,自動增長率是2MB。
1 /* 2 mdf: initial size 195 MB, 16 MB growth 3 ldf: initial size 2 MB, 2 MB growth 4 */ 5 6 USE master 7 GO 8 IF DB_ID('PersonsLots') IS NOT NULL 9 DROP DATABASE PersonsLots; 10 GO 11 12 -- Clear backup history 13 EXEC msdb.dbo.sp_delete_database_backuphistory @database_name = N'PersonsLots' 14 GO 15 16 CREATE DATABASE [PersonsLots] ON PRIMARY 17 ( NAME = N'PersonsLots' 18 , FILENAME = N'C:\SQLData\PersonsLots.mdf' 19 , SIZE = 199680KB 20 , FILEGROWTH = 16384KB 21 ) 22 LOG ON 23 ( NAME = N'PersonsLots_log' 24 , FILENAME = N'D:\SQLData\PersonsLots_log.ldf' 25 , SIZE = 2048KB 26 , FILEGROWTH = 2048KB 27 ) 28 GO 29 30 ALTER DATABASE PersonsLots SET RECOVERY FULL; 31 32 USE master 33 GO 34 BACKUP DATABASE PersonsLots 35 TO DISK ='D:\SQLBackups\PersonsLots_full.bak' 36 WITH INIT; 37 GO 38 39 DBCC SQLPERF(LOGSPACE) ; 40 --2 MB, 15% used 41 USE Persons 42 GO 43 DBCC LOGINFO; 44 -- 4 VLFs
代碼8.4:創建PersonsLots資料庫
現在我們在很小的增長率里進行日誌增長,如代碼8.5所示,為了創建特別的碎片日誌文件。
1 DECLARE @LogGrowth INT = 0; 2 DECLARE @sSQL NVARCHAR(4000) 3 WHILE @LogGrowth < 4096 4 5 BEGIN 6 7 SET @sSQL = 'ALTER DATABASE PersonsLots MODIFY FILE (NAME = PersonsLots_log, SIZE = ' + CAST(4096+2048*@LogGrowth AS VARCHAR(10)) + 'KB );' 8 EXEC(@sSQL); 9 SET @LogGrowth = @LogGrowth + 1; 10 END 11 USE PersonsLots 12 GO 13 DBCC LOGINFO 14 --16388 VLFs 15 16 DBCC SQLPERF (LOGSPACE); 17 -- 8194 MB, 6.3% full
代碼8.5:對資料庫PersonsLots創建非常大的碎片日誌。
這裡我們增長日誌在4096增長率,總大小是8GB(4096+2048*4096KB)。日誌增加了4096倍,每次增加4個VLF,移動有了4+(4096*4)=16388個VLF。
現在重新運行代碼8.2來重建Persons表,但這次在PersonLots資料庫,然後調整代碼8.3來在表裡插入100萬條記錄。現在我們將更新Person表來創建很多日誌記錄。取決於你機器配置,當你運行代碼8.6時,你可以泡上一杯咖啡。
1 USE PersonsLots 2 GO 3 /* this took 6 mins*/ 4 DECLARE @cnt INT; 5 6 SET @cnt = 1; 7 8 WHILE @cnt < 6 9 BEGIN; 10 SET @cnt = @cnt + 1; 11 UPDATE dbo.Persons 12 SET Email = LEFT(Email + Email, 7000) 13 END; 14 15 DBCC SQLPERF(LOGSPACE) ; 16 --8194 MB, 67% used 17 DBCC LOGINFO; 18 -- 16388 VLFs
代碼8.6:在Persons表上的一個大更新。
最後,我們可以進行一次日誌備份看看會花多少時間。我們在備份代碼後包含了註釋掉的備份統計信息。
1 USE master 2 GO 3 BACKUP LOG PersonsLots 4 TO DISK ='D:\SQLBackups\PersonsLots_log.trn' 5 WITH INIT; 6 7 /*Processed 666930 pages for database 'PersonsLots', file 'PersonsLots_log' on file 1. 8 BACKUP LOG successfully processed 666930 pages in 123.263 seconds (42.270 MB/sec).*/
代碼8.7:PersonsLots的日誌備份(碎片日誌)
作為比較,我們重覆同樣的測試,但這次我們會仔細調整資料庫日誌大小,讓它有合理的數目的大小合適的VLF。在代碼8.8,我們重建Persons資料庫,初始日誌大小為2GB(16個VLF,每個128M大小)。然後我們人為增長日誌,只有3步就到8GB大小,包含64個VLF(每個128M的大小)。
1 USE master 2 GO 3 IF DB_ID('Persons') IS NOT NULL 4 DROP DATABASE Persons; 5 GO 6 7 CREATE DATABASE [Persons] ON PRIMARY 8 ( NAME = N'Persons' 9 , FILENAME = N'C:\SQLData\Persons.mdf' 10 , SIZE = 2097152KB 11 , FILEGROWTH = 1048576KB 12 ) 13 LOG ON 14 ( NAME = N'Persons_log' 15 , FILENAME = N'D:\SQLData\Persons_log.ldf' 16 , SIZE = 2097152KB 17 , FILEGROWTH = 2097152KB 18 ) 19 GO 20 USE Persons 21 GO 22 DBCC LOGINFO; 23 -- 16 VLFs 24 25 USE master 26 GO 27 ALTER DATABASE Persons MODIFY FILE ( NAME = N'Persons_log', SIZE = 4194304KB ) 28 GO 29 -- 32 VLFs 30 31 ALTER DATABASE Persons MODIFY FILE ( NAME = N'Persons_log', SIZE = 6291456KB ) 32 GO 33 -- 48 VLFs 34 35 ALTER DATABASE Persons MODIFY FILE ( NAME = N'Persons_log', SIZE = 8388608KB ) 36 GO 37 -- 64 VLFs 38 39 ALTER DATABASE Persons SET RECOVERY FULL; 40 41 USE master 42 GO 43 BACKUP DATABASE Persons 44 TO DISK ='D:\SQLBackups\Persons_full.bak' 45 WITH INIT; 46 GO
代碼8.8:創建Persons資料庫並人為增長日誌。
現在重新運行代碼8.2,8.3(有100萬條記錄)和8.6和我們剛纔測試的一樣。你會發現,沒有發生日誌增長。
代碼8.6運行得很快(在我們的測試里,只要一半的時間)。最後,重新運行日誌備份。
1 USE master 2 GO 3 BACKUP LOG Persons 4 TO DISK ='D:\SQLBackups\Persons_log.trn' 5 WITH INIT; 6 7 /*Processed 666505 pages for database 'Persons', file 'Persons_log' on file 1. BACKUP LOG successfully processed 666505 pages in 105.706 seconds (49.259 MB/sec). 8 */
代碼8.9:Persons資料庫的日誌備份(無碎片日誌)
在日誌備份的影響相對小,對這個大小的日誌是可覆寫的,與只有64個的,14292個VLF的日誌,備份時間有近15-20%的增長,當然,這個是相對於小資料庫(固然有很嚴重的日誌碎片)。
故障恢復影響
在這些測試里,我們調查在故障恢覆上碎片的影響,因為這個過程需要SQL Server讀取活動日誌,重做或撤銷需要的日誌記錄來返回資料庫到一致的狀態。
大量重做
在第一個例子里,我們重用PersonsLots資料庫,刪除並重建,設置恢復模式為完整,進行完整備份然後插入100萬條記錄,如剛纔所示代碼。
現在,在我們更新這些行前,我們將禁止自動化檢查點。
絕不禁止自動化檢查點!
這裡我們這樣做純粹是測試為目的。在任何正常運行的SQL Server資料庫里我們絕不推薦禁止自動化檢查點。
當我們提交隨後的更新時,我們立即關閉資料庫,這樣的話,所有的更新已經寫入日誌但沒有寫入數據文件。因此,在故障恢復期間,SQL Server會需要讀取所有相關的日誌來重做所有的操作。
1 USE PersonsLots 2 Go 3 /*Disable Automatic checkpoints*/ 4 DBCC TRACEON( 3505 ) 5 6 /*Turn the flag off once the test is complete!*/ 7 --DBCC TRACEOFF (3505) 8 9 /* this took 5 mins*/ 10 BEGIN TRANSACTION 11 DECLARE @cnt INT; 12 13 SET @cnt = 1; 14 15 WHILE @cnt < 6 16 BEGIN; 17 SET @cnt = @cnt + 1; 18 UPDATE dbo.Persons 19 SET Email = LEFT(Email + Email, 7000) 20 END; 21 22 DBCC SQLPERF(LOGSPACE) ; 23 --11170 MB, 100% used 24 USE PersonsLots 25 GO 26 DBCC LOGINFO; 27 -- 22340 VLFs
代碼8.10:PersonsLots——禁止自動化檢查點,在顯性事務里運行更新。
現在我們提交事務,關閉資料庫。
1 /*Commit and immediately Shut down*/ 2 COMMIT TRANSACTION; 3 SHUTDOWN WITH NOWAIT
代碼8.11:提交事務,關閉SQL Server
在重啟SQL Server服務後,在恢復期間,嘗試訪問PersonsLots,你會看到如下信息。
1 USE PersonsLots 2 Go 3 /*Msg 922, Level 14, State 2, Line 1 4 Database 'PersonsLots' is being recovered. Waiting until recovery is finished.*/
代碼8.12:PersonsLots正在進行恢復操作。
在SQL Server開始恢複數據庫前,它需要打開日誌,讀取每個VLF。因為多個VLF的影響會延伸到SQL Server重啟資料庫和開始恢復過程之間的時間。
因此,一旦資料庫是可訪問的,我們可以查看這2個事件之間的錯誤日誌,即總的恢復時間。
1 EXEC sys.xp_readerrorlog 0, 1, 'PersonsLots' 2 3 /* 4 2012-10-03 11:28:14.240 Starting up database 'PersonsLots'. 5 2012-10-03 11:28:26.710 Recovery of database 'PersonsLots' (6) is 0% 6 complete (approximately 155 seconds remain). 7 2012-10-03 11:28:33.000 140 transactions rolled forward in database 8 'PersonsLots' (6). 9 2012-10-03 11:28:33.010 Recovery completed for database PersonsLots 10 (database ID 6) in 6 second(s) 11 (analysis 2238 ms, redo 4144 ms, undo 12 ms.) 12 */
代碼8.13:對PersonsLots信息進行錯誤日誌查看。
在SQL Server啟動資料庫和開始恢復進程之間有近12.5秒。這是為什麼會看到資料庫列為“in recovery(在恢復中)”,在錯誤日誌里沒有看到任何初始恢覆信息。恢復進程在7秒內完成。註意,在這三個恢復階段,SQL Server花費更多的時間在重做。
現在讓我們對Persons資料庫(預製日誌文件大小)重做同樣的測試。
1 USE Persons 2 Go 3 /*Disable Automatic checkpoints*/ 4 DBCC TRACEON( 3505 ) 5 --DBCC TRACEOFF (3505) 6 7 USE Persons 8 Go 9 BEGIN TRANSACTION 10 DECLARE @cnt INT; 11 12 SET @cnt = 1; 13 14 WHILE @cnt < 6 15 BEGIN; 16 SET @cnt = @cnt +


