
在這篇文章,我們一起瞭解 Redis 使用中非常重要的兩個機制:Reids 持久化和主從複製。 什麼是 Redis 持久化? Redis 作為一個鍵值對記憶體資料庫(NoSQL),數據都存儲在記憶體當中,在處理客戶端請求時,所有操作都在記憶體當中進行,如下所示 這樣做有什麼問題呢?其實,只要稍微有點電腦 ...
在這篇文章,我們一起瞭解 Redis 使用中非常重要的兩個機制:Reids 持久化和主從複製。
什麼是 Redis 持久化?
Redis 作為一個鍵值對記憶體資料庫(NoSQL),數據都存儲在記憶體當中,在處理客戶端請求時,所有操作都在記憶體當中進行,如下所示
這樣做有什麼問題呢?其實,只要稍微有點電腦基礎知識的人都知道,存儲在記憶體當中的數據,只要伺服器關機(各種原因引起的),記憶體中的數據就會消失了。
不僅伺服器關機會造成數據消失,Redis 伺服器守護進程退出,記憶體中的數據也一樣會消失。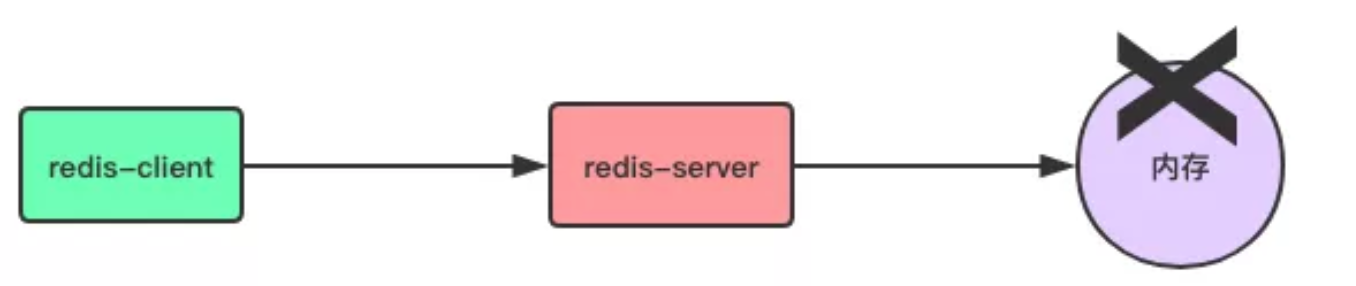
對於只把 Redis 當緩存來用的項目來說,數據消失或許問題不大,重新從數據源把數據載入進來就可以了。
但如果直接把用戶提交的業務數據存儲在 Redis 當中,把 Redis 作為資料庫來使用,在其放存儲重要業務數據,那麼 Redis 的記憶體數據丟失所造成的影響也許是毀滅性。
為了避免記憶體中數據丟失,Redis 提供了對持久化的支持,我們可以選擇不同的方式將數據從記憶體中保存到硬碟當中,使數據可以持久化保存。
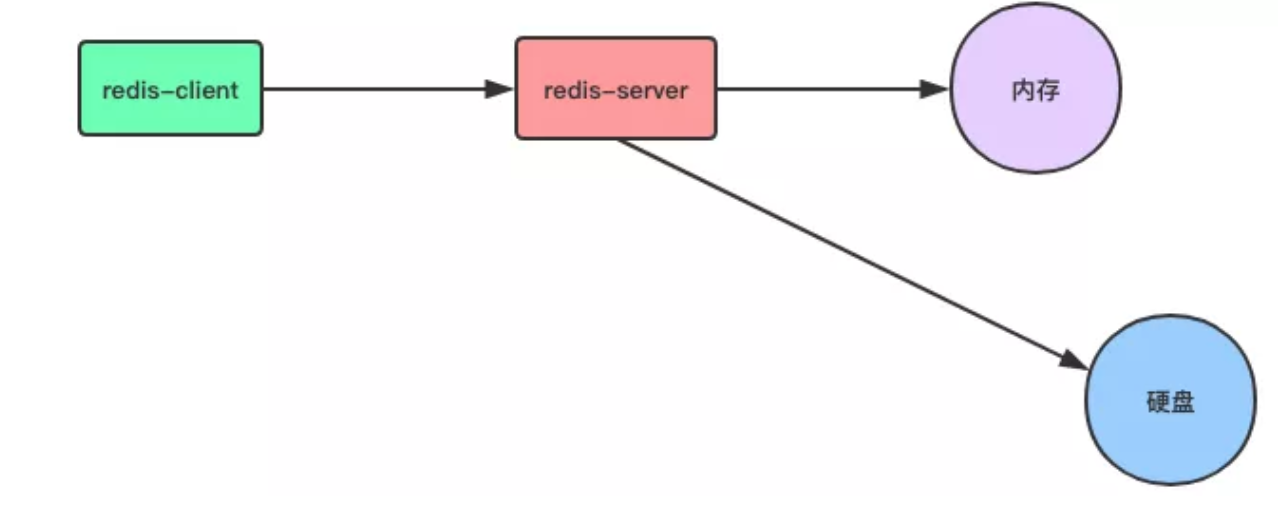
Redis 提供了 RDB 和 AOF 兩種不同的數據持久化方式,下麵我們就來詳細介紹一下這種不同的持久化方式吧。
RDB
RDB 是一種快照存儲持久化方式,具體就是將 Redis 某一時刻的記憶體數據保存到硬碟的文件當中,預設保存的文件名為 dump.rdb,而在 Redis 伺服器啟動時,會重新載入 dump.rdb 文件的數據到記憶體當中恢複數據。
①開啟 RDB 持久化方式
開啟 RDB 持久化方式很簡單,客戶端可以通過向 Redis 伺服器發送 Save 或 Bgsave 命令讓伺服器生成 RDB 文件,或者通過伺服器配置文件指定觸發 RDB 條件。
save 命令:是一個同步操作。
# 同步數據到磁碟上
> save

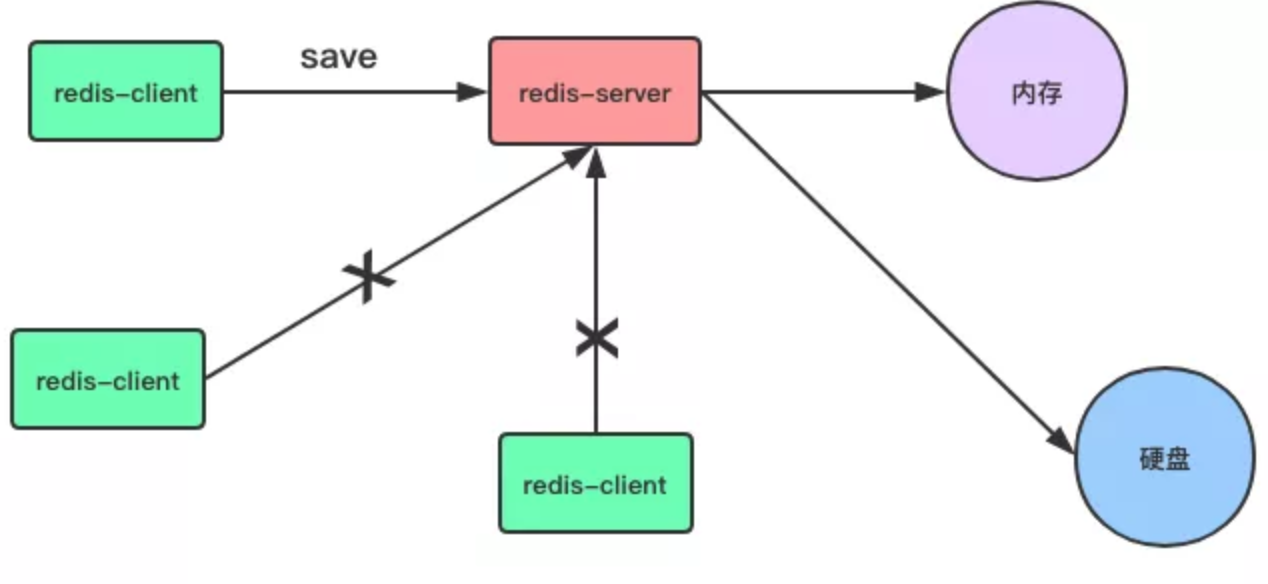
當客戶端向伺服器發送 Save 命令請求進行持久化時,伺服器會阻塞 Save 命令之後的其他客戶端的請求,直到數據同步完成。
如果數據量太大,同步數據會執行很久,而這期間 Redis 伺服器也無法接收其他請求,所以,最好不要在生產環境使用 Save 命令。
Bgsave:與 Save 命令不同,Bgsave 命令是一個非同步操作。
# 非同步保存數據集到磁碟上
> bgsave
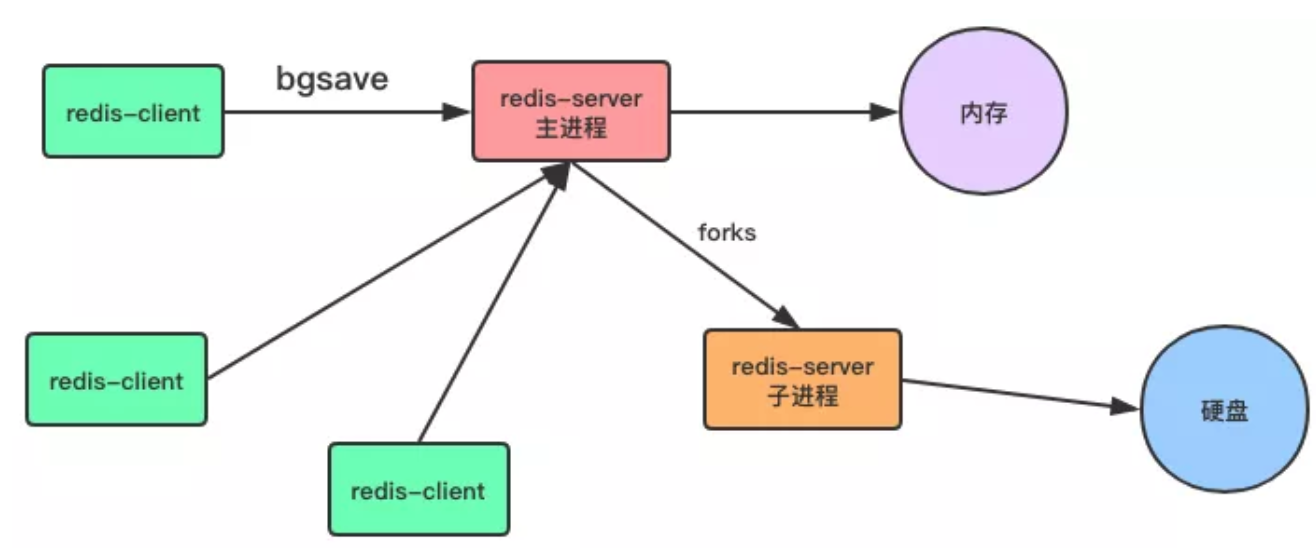
當客戶端發服務發出 Bgsave 命令時,Redis 伺服器主進程會 Forks 一個子進程來數據同步問題,在將數據保存到 RDB 文件之後,子進程會退出。
所以,與 Save 命令相比,Redis 伺服器在處理 Bgsave 採用子線程進行 IO 寫入。
而主進程仍然可以接收其他請求,但 Forks 子進程是同步的,所以 Forks 子進程時,一樣不能接收其他請求。
這意味著,如果 Forks 一個子進程花費的時間太久(一般是很快的),Bgsave 命令仍然有阻塞其他客戶的請求的情況發生。
伺服器配置自動觸發:除了通過客戶端發送命令外,還有一種方式,就是在 Redis 配置文件中的 Save 指定到達觸發 RDB 持久化的條件,比如【多少秒內至少達到多少寫操作】就開啟 RDB 數據同步。
例如我們可以在配置文件 redis.conf 指定如下的選項:
# 900s內至少達到一條寫命令 save 900 1 # 300s內至少達至10條寫命令 save 300 10 # 60s內至少達到10000條寫命令 save 60 10000
之後在啟動伺服器時載入配置文件。
# 啟動伺服器載入配置文件
redis-server redis.conf
這種通過伺服器配置文件觸發 RDB 的方式,與 Bgsave 命令類似,達到觸發條件時,會 Forks 一個子進程進行數據同步。
不過最好不要通過這方式來觸發 RDB 持久化,因為設置觸發的時間太短,則容易頻繁寫入 RDB 文件,影響伺服器性能,時間設置太長則會造成數據丟失。
②RDB 文件
前面介紹了三種讓伺服器生成 RDB 文件的方式,無論是由主進程生成還是子進程來生成,其過程如下:
-
生成臨時 RDB 文件,並寫入數據。
-
完成數據寫入,用臨時文代替代正式 RDB 文件。
-
刪除原來的 DB 文件。
RDB 預設生成的文件名為 dump.rdb,當然,我可以通過配置文件進行更加詳細配置。
比如在單機下啟動多個 Redis 伺服器進程時,可以通過埠號配置不同的 RDB 名稱,如下所示:
# 是否壓縮rdb文件 rdbcompression yes # rdb文件的名稱 dbfilename redis-6379.rdb # rdb文件保存目錄 dir ~/redis/
RDB的幾個優點:
-
與 AOF 方式相比,通過 RDB 文件恢複數據比較快。
-
RDB 文件非常緊湊,適合於數據備份。
-
通過 RDB 進行數據備份,由於使用子進程生成,所以對 Redis 伺服器性能影響較小。
RDB 的幾個缺點:
-
如果伺服器宕機的話,採用 RDB 的方式會造成某個時段內數據的丟失,比如我們設置 10 分鐘同步一次或 5 分鐘達到 1000 次寫入就同步一次,那麼如果還沒達到觸發條件伺服器就死機了,那麼這個時間段的數據會丟失。
-
使用 Save 命令會造成伺服器阻塞,直接數據同步完成才能接收後續請求。
-
使用 Bgsave 命令在 Forks 子進程時,如果數據量太大,Forks 的過程也會發生阻塞,另外,Forks 子進程會耗費記憶體。
AOF
聊完了 RDB,來聊聊 Redis 的另外一個持久化方式:AOF(Append-only file)。
與 RDB 存儲某個時刻的快照不同,AOF 持久化方式會記錄客戶端對伺服器的每一次寫操作命令,並將這些寫操作以 Redis 協議追加保存到以尾碼為 AOF 文件末尾。
在 Redis 伺服器重啟時,會載入並運行 AOF 文件的命令,以達到恢複數據的目的。
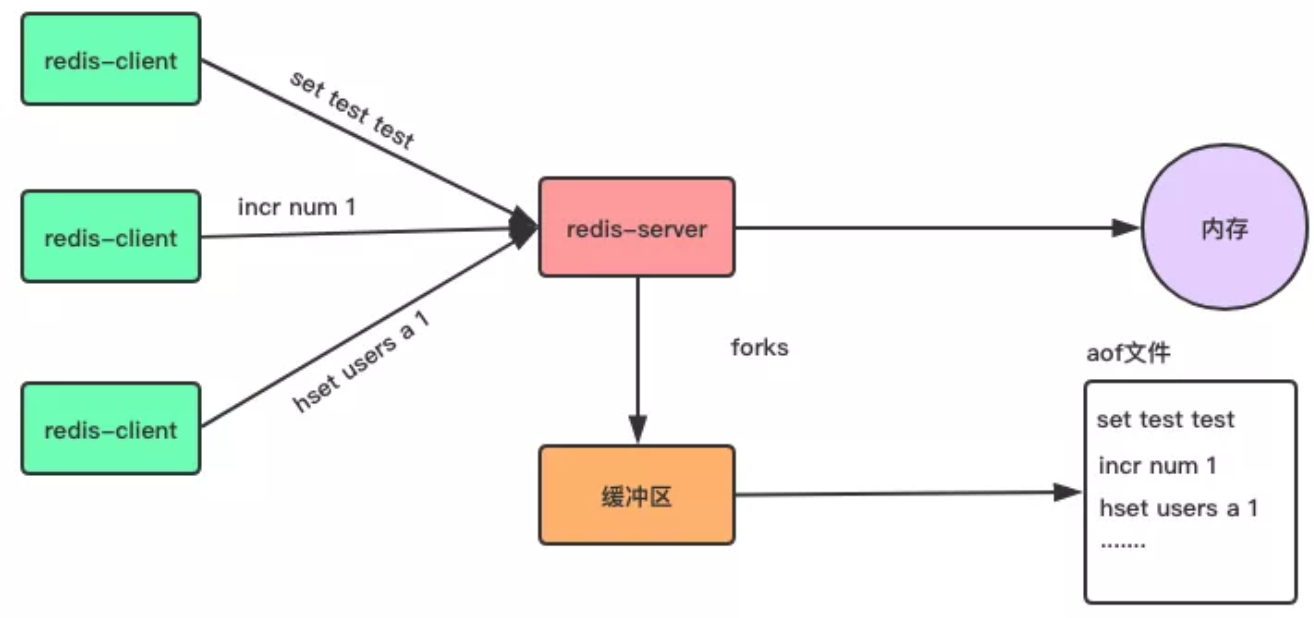
①開啟 AOF 持久化方式
Redis 預設不開啟 AOF 持久化方式,我們可以在配置文件中開啟併進行更加詳細的配置,如下麵的 redis.conf 文件:
# 開啟aof機制 appendonly yes # aof文件名 appendfilename "appendonly.aof" # 寫入策略,always表示每個寫操作都保存到aof文件中,也可以是everysec或no appendfsync always # 預設不重寫aof文件 no-appendfsync-on-rewrite no # 保存目錄 dir ~/redis/
②三種寫入策略
在上面的配置文件中,我們可以通過 appendfsync 選項指定寫入策略,有三個選項:
appendfsync always
# appendfsync everysec
# appendfsync no
always:客戶端的每一個寫操作都保存到 AOF 文件當中,這種策略很安全,但是每個寫操作都有 IO 操作,所以也很慢。
everysec:appendfsync 的預設寫入策略,每秒寫入一次 AOF 文件,因此,最多可能會丟失 1s 的數據。
no:Redis 伺服器不負責寫入 AOF,而是交由操作系統來處理什麼時候寫入 AOF 文件。更快,但也是最不安全的選擇,不推薦使用。
③AOF 文件重寫
AOF 將客戶端的每一個寫操作都追加到 AOF 文件末尾,比如對一個 Key 多次執行 Incr 命令,這時候,AOF 保存每一次命令到 AOF 文件中,AOF 文件會變得非常大。
incr num 1 incr num 2 incr num 3 incr num 4 incr num 5 incr num 6 ... incr num 100000
AOF 文件太大,載入 AOF 文件恢複數據時,就會非常慢,為瞭解決這個問題,Redis 支持 AOF 文件重寫。
通過重寫 AOF,可以生成一個恢復當前數據的最少命令集,比如上面的例子中那麼多條命令,可以重寫為:
set num 100000
AOF 文件是一個二進位文件,並不是像上面的例子一樣,直接保存每個命令,而使用 Redis 自己的格式,上面只是方便演示。
兩種重寫方式:通過在 redis.conf 配置文件中的選項 no-appendfsync-on-rewrite 可以設置是否開啟重寫。
這種方式會在每次 Fsync 時都重寫,影響伺服器性能,因此預設值為 no,不推薦使用。
# 預設不重寫aof文件
no-appendfsync-on-rewrite no
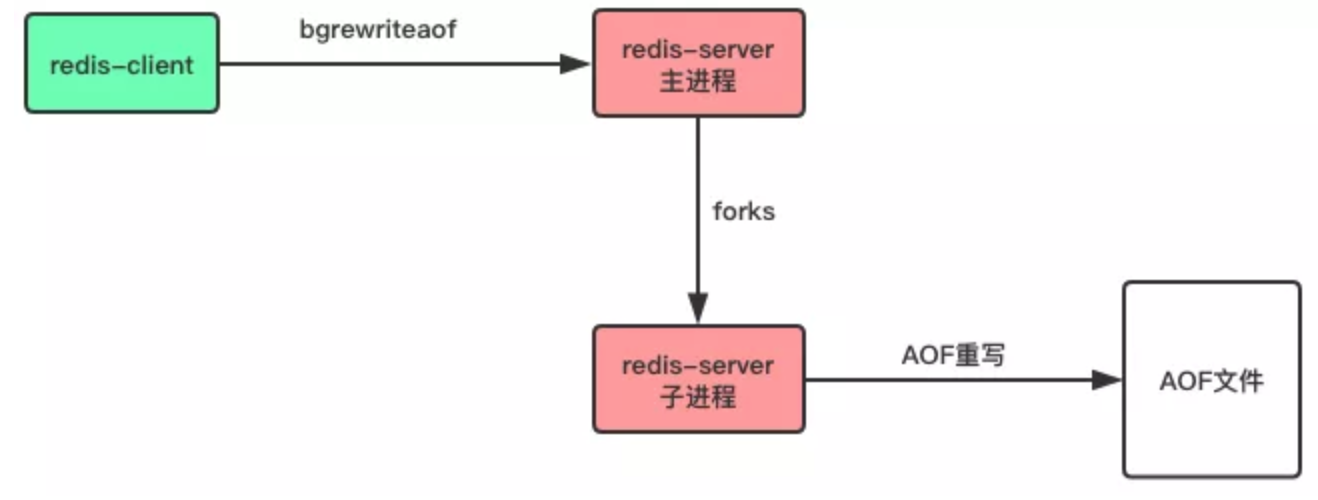
客戶端向伺服器發送 bgrewriteaof 命令,也可以讓伺服器進行 AOF 重寫。
# 讓伺服器非同步重寫追加aof文件命令
> bgrewriteaof
AOF 重寫方式也是非同步操作,即如果要寫入 AOF 文件,則 Redis 主進程會 Forks 一個子進程來處理,如下所示:
重寫 AOF 文件的好處:
-
壓縮 AOF 文件,減少磁碟占用量。
-
將 AOF 的命令壓縮為最小命令集,加快了數據恢復的速度。
③AOF 文件損壞
在寫入 AOF 日誌文件時,如果 Redis 伺服器宕機,則 AOF 日誌文件文件會出格式錯誤。
在重啟 Redis 伺服器時,Redis 伺服器會拒絕載入這個 AOF 文件,可以通過以下步驟修複 AOF 並恢複數據:
-
備份現在 AOF 文件,以防萬一。
- 使用 redis-check-aof 命令修複 AOF 文件,該命令格式如下:
# 修複aof日誌文件
$ redis-check-aof -fix file.aof
-
重啟 Redis 伺服器,載入已經修複的 AOF 文件,恢複數據。
AOF 的優點:
-
AOF 只是追加日誌文件,因此對伺服器性能影響較小,速度比 RDB 要快,消耗的記憶體較少。
AOF 的缺點:
-
AOF 方式生成的日誌文件太大,即使通過 AFO 重寫,文件體積仍然很大。
-
恢複數據的速度比 RDB 慢。
選擇 RDB 還是 AOF 呢?
通過上面的介紹,我們瞭解了 RDB 與 AOF 各自的優點與缺點,到底要如何選擇呢?
通過下麵的表示,我們可以從幾個方面對比一下 RDB 與 AOF,在應用時,要根據自己的實際需求,選擇 RDB 或者 AOF。
其實,如果想要數據足夠安全,可以兩種方式都開啟,但兩種持久化方式同時進行 IO 操作,會嚴重影響伺服器性能,因此有時候不得不做出選擇。

當 RDB 與 AOF 兩種方式都開啟時,Redis 會優先使用 AOF 日誌來恢複數據,因為 AOF 保存的文件比 RDB 文件更完整。
小結:上面講了一大堆 Redis 的持久化機制的知識,其實,如果你只是單純把 Redis 作為緩存伺服器,那麼可以完全不用考慮持久化。
但是,在如今的大多數伺服器架構中,Redis 不單單隻是扮演一個緩存伺服器的角色,還可以作為資料庫,保存我們的業務數據,此時,我們則需要好好瞭解有關 Redis 持久化策略的區別與選擇。
什麼是 Reids 主從複製?
上面,我們瞭解了 Redis 兩種不同的持久化方式,Redis 伺服器通過持久化,把 Redis 記憶體中持久化到硬碟當中,當 Redis 宕機時,我們重啟 Redis 伺服器時,可以由 RDB 文件或 AOF 文件恢復記憶體中的數據。
不過持久化後的數據仍然只在一臺機器上,因此當硬體發生故障時,比如主板或 CPU 壞了,這時候無法重啟伺服器,有什麼辦法可以保證伺服器發生故障時數據的安全性?或者可以快速恢複數據呢?
想做到這一點,我們需要再瞭解 Redis 另外一種機制:主從複製。
Redis 的主從複製機制是指可以讓從伺服器(Slave)能精確複製主伺服器(Master)的數據,如下圖所示:

上面的圖表示的是一臺 Master 伺服器與 Slave 伺服器的情況,其實一臺 Master 伺服器也可以對應多台 Slave 伺服器,如下圖所示: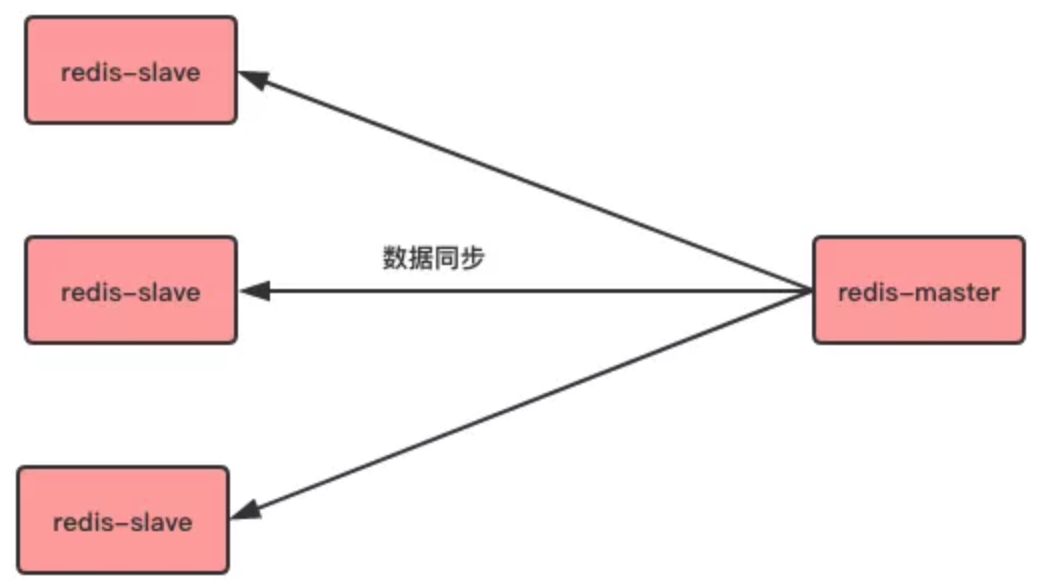
另外,Slave 伺服器也可以有自己的 Slave 伺服器,這樣的伺服器稱為 Sub-Slave。
而這些 Sub-Slave 通過主從複製最終數據也能與 Master 保持一致,如下圖所示:
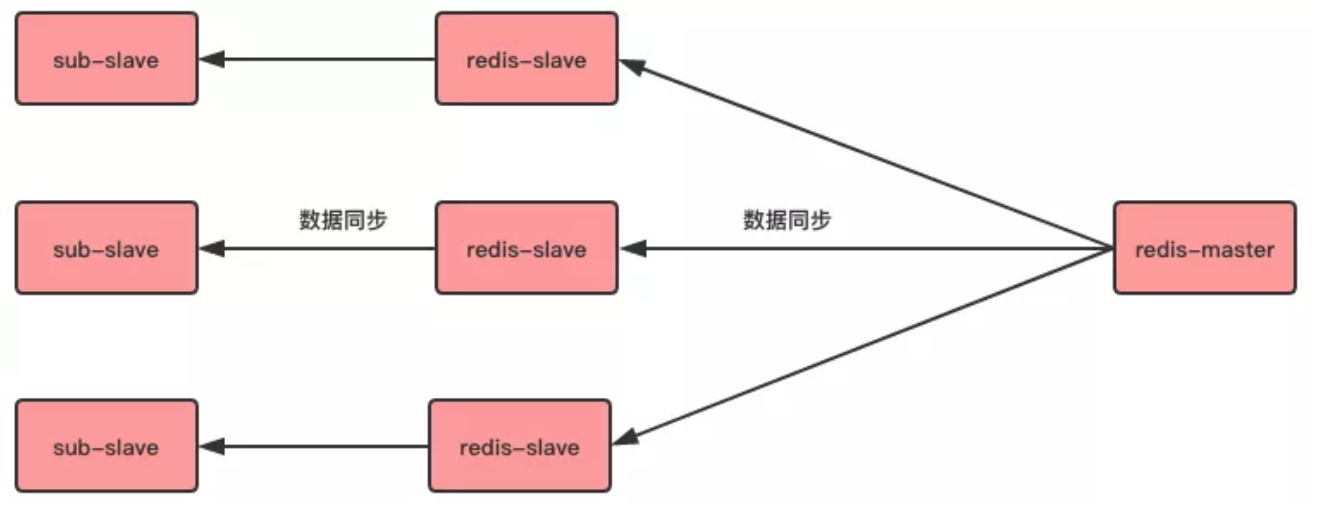
主從複製的方式和工作原理
Redis 的主從複製是非同步複製,非同步分為兩個方面:
-
一個是 Master 伺服器在將數據同步到 Slave 時是非同步的,因此 Master 伺服器在這裡仍然可以接收其他請求。
-
一個是 Slave 在接收同步數據也是非同步的。
①複製方式
Redis 主從複製分為以下三種方式:
-
當 Master 伺服器與 Slave 伺服器正常連接時,Master 伺服器會發送數據命令流給 Slave 伺服器,將自身數據的改變複製到 Slave 伺服器。
-
當因為各種原因 Master 伺服器與 Slave 伺服器斷開後,Slave 伺服器在重新連上 Master 伺服器時會嘗試重新獲取斷開後未同步的數據即部分同步,或者稱為部分複製。
-
如果無法部分同步(比如初次同步),則會請求進行全量同步,這時 Master 伺服器會將自己的 RDB 文件發送給 Slave 伺服器進行數據同步,並記錄同步期間的其他寫入,再發送給 Slave 伺服器,以達到完全同步的目的,這種方式稱為全量複製。
②工作原理
Master 伺服器會記錄一個 Replication Id 的偽隨機字元串,用於標識當前的數據集版本,還會記錄一個當數據集的偏移量 Offset。
不管 Master 是否有配置 Slave 伺服器,Replication Id 和 Offset 會一直記錄併成對存在,我們可以通過以下命令查看 Replication Id和 Offset:
> info repliaction
通過 redis-cli 在 Master 或 Slave 伺服器執行該命令會列印類似以下信息(不同伺服器數據不同,列印信息不同):
connected_slaves:1 slave0:ip=127.0.0.1,port=6380,state=online,offset=9472,lag=1 master_replid:2cbd65f847c0acd608c69f93010dcaa6dd551cee master_repl_offset:9472
當 Master 與 Slave 正常連接時,Slave 使用 PSYNC 命令向 Master 發送自己記錄的舊 Master 的 Replication id 和 Offset。
而 Master 會計算與 Slave 之間的數據偏移量,並將緩衝區中的偏移數量同步到 Slave,此時 Master 和 Slave 的數據一致。
而如果 Slave 引用的 Replication 太舊了,Master 與 Slave 之間的數據差異太大,則 Master 與 Slave 之間會使用全量複製的進行數據同步。
配置主從複製
Redis 的主從配置非常簡單,我們可以使用兩種方式來配置主從伺服器,在這時我們先假設 Redis 的 Master 伺服器地址為 192.168.0.101。
客戶端發送同步命令:
# 向客戶端 saveof 192.168.1.101 6379
Slave 伺服器配置主伺服器:在這裡 Slave 伺服器的 redis.conf 通過 saveof 選項,可以指定 Master 伺服器,如下:
slaveof 192.168.1.101 6379
通過上面兩種方式的配置,Master 伺服器與 Slave 伺服器便已經可以開始進行數據同步了。
Master 要求驗證:上面配置的是 Master 伺服器沒有設置密碼的情況,如果 Master 設置了密碼,則可以在連接到 Slave 伺服器的 redis-cli 執行下麵的命令:
# <password>指代實際的密碼 config set masterauth <password>
或者在 Slave 伺服器的 redis.conf 中配置下麵的選項:
# <password>指代實際的密碼
masterauth <password>
避免 Slave 被清空
Slave 會被清空?Slave 不用同步了 Master 的數據嗎?備份的數據怎麼會清空了呢?
當 Master 伺服器關閉了持久化時,如果發生故障後自動重啟時,由本地沒有保存持久化的數據,重啟的 Redis 記憶體數據為空,而 Slave 會自動同步 Master 的數據,這時候,Slave 伺服器的數據也會被清空。
如何避免 Slave 被清空呢?如果條件允許(一般都可以的),Master 伺服器還是要開啟持久化,這樣 Master 故障重啟時,可以快速恢複數據,而同步這台 Master 的 Slave 數據也不會被清空。
如果 Master 不能開啟持久化,則不應該設置讓 Master 發生故障後重啟(有些機器會配置自動重啟),而是將某個 Slave 伺服器升級為 Master 伺服器,對外繼續提供服務。
Slave 預設為只讀的
在 Redis 2.6 以後,Slave 只讀模式是預設開啟的,我們可以通過配置文件中的 slave-read-only 選項配置是否開啟只讀模式:
# 預設是yes
slave-read-only yes/no
或者在客戶端中通過 config set 命令設置是否開啟只讀模式:
config set slave-read-only no
上面將 Slave 伺服器設置為可以寫入,但是要註意,如果 Slave 也配置了自己的從伺服器(Sub-Slave),那麼 Sub-Slave 只會同步從 Master 伺服器同步到 Slave 的數據,而並會同步我們直接寫入 Slave 伺服器的數據。
主從複製中的 Key 過期問題
我們都知道 Redis 可以通過設置 Key 的過期時間來限制 Key 的生存時間,Redis 處理 Key 過期有惰性刪除和定期刪除兩種機制。
而在配置主從複製後,Slave 伺服器就沒有許可權處理過期的 Key,這樣的話,對於在 Master 上過期的 Key,在 Slave 伺服器就可能被讀取。
所以 Master 會累積過期的 Key,積累一定的量之後,發送 Del 命令到 Slave,刪除 Slave 上的 Key。
如果 Slave 伺服器升級為 Master 伺服器 ,則它將開始獨立地計算 Key 過期時間,而不需要通過 Master 伺服器的幫助。
主從複製的作用
①保存 Redis 數據副本
當我們只是通過 RDB 或 AOF 把 Redis 的記憶體數據持久化畢竟只是在本地,並不能保證絕對的安全,而通過將數據同步 Slave 伺服器上,可以保留多一個數據備份,更好地保證數據的安全。
②讀寫分離
在配置了主從複製之後,如果 Master 伺服器的讀寫壓力太大,可以進行讀寫分離,客戶端向 Master 伺服器寫入數據,在讀數據時,則訪問 Slave 伺服器,從而減輕 Master 伺服器的訪問壓力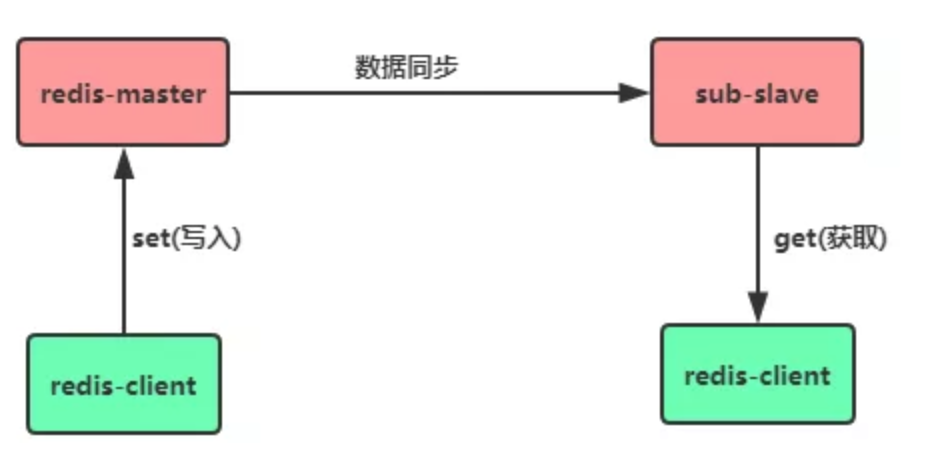
③高可用性與故障轉移
伺服器的高可用性是指伺服器能提供 7*24 小時不間斷的服務,Redis 可以通過 Sentinel 系統管理多個 Redis 伺服器。
當 Master 伺服器發生故障時,Sentineal 系統會根據一定的規則將某台 Slave 伺服器升級為 Master 伺服器,繼續提供服務,實現故障轉移,保證 Redis 服務不間斷。
小結:Redis 的主從複製可以讓我們把 Redis 中的數據同步到其他伺服器上,為數據安全提供更加安全的保障,也可以讓我們的伺服器在發生故障而無法重啟時,可以更加快速地切換伺服器,繼續對外提供服務。
作者:張君鴻
編輯:陶家龍、孫淑娟
出處:https://juejin.im/user/5c6665476fb9a049a81fd8e9

