
使用HABSE之前,要先安裝一個zookeeper zookeeper是幹嘛的呢 Zookeeper的作用1.可以為客戶端管理少量的數據kvkey:是以路徑的形式表示的,那就意味著,各key之間有父子關係,比如/ 是頂層key用戶建的key只能在/ 下作為子節點,比如建一個key: /aa 這個ke ...
使用HABSE之前,要先安裝一個zookeeper
我以前寫的有https://www.cnblogs.com/wpbing/p/11309761.html
先簡單介紹一下HBASE
HBASE是一個資料庫----可以提供數據的實時隨機讀寫
他是一個nosql資料庫,並不是結構化的,他只能粗略的進行一些查詢,像多表之間的連接查詢他是很難做到的(至少我這辣雞不會)。
我也是第一次接觸這種nosql,人家的表結構不太一樣,就是啥吧,
他有一個行健(類似於主鍵的東西)
然後剩下的就是你可以定義有幾個列族
每個列族裡面,
列族裡面都是一個一個的key,value值。一對kv,稱作一個cell。
每一個value又可以有多個值,並不是一個
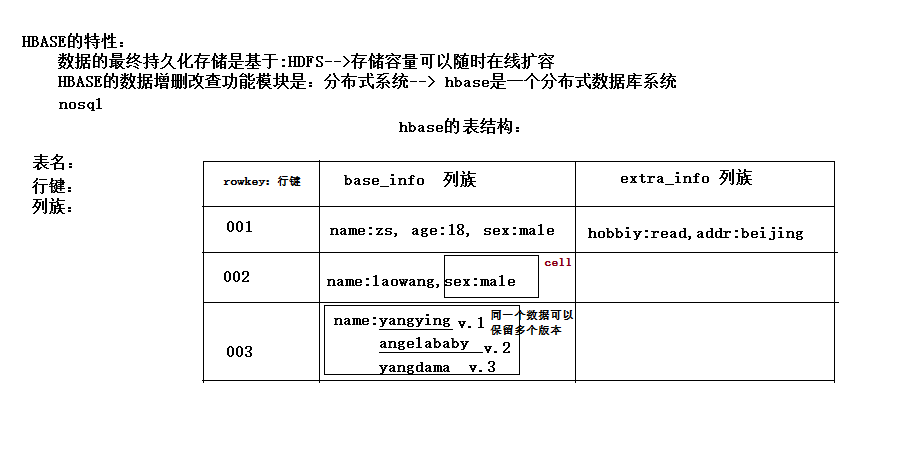
l Hbase的表模型與關係型資料庫的表模型不同:
l Hbase的表沒有固定的欄位定義;
l Hbase的表中每行存儲的都是一些key-value對
l Hbase的表中有列族的劃分,用戶可以指定將哪些kv插入哪個列族
l Hbase的表在物理存儲上,是按照列族來分割的,不同列族的數據一定存儲在不同的文件中
l Hbase的表中的每一行都固定有一個行鍵,而且每一行的行鍵在表中不能重覆
l Hbase中的數據,包含行鍵,包含key,包含value,都是byte[ ]類型,hbase不負責為用戶維護數據類型
l HBASE對事務的支持很差
Hbase的表數據存儲在HDFS文件系統中
HBASE是一個分散式系統
其中有一個管理角色: HMaster(一般2台,一臺active,一臺backup)
其他的數據節點角色: HRegionServer(很多台,看數據容量)
master用來配置數據儲存和任務的分配,
regionserver管理著每一張表的區域數據
Regionserver管理著每一個的文件的範圍,Zookeeper用來檢測regionserver是否掛掉,master用來控制任務的分發。就是當regionserver掛掉了,如何找人接替他的任務。
HBASE的大體工作機制是這樣嬸的
客戶端怎麼知道數據在哪台伺服器,他會先查找那個索引表,hbase:meta表
那這個表在哪呢,

在zookeeper裡面可以看到這個索引表的信息
這個東西是放到zookeeper裡面,先看zookeeper的meta、變所在的regionserver,然後去訪問它知道他的信息在哪
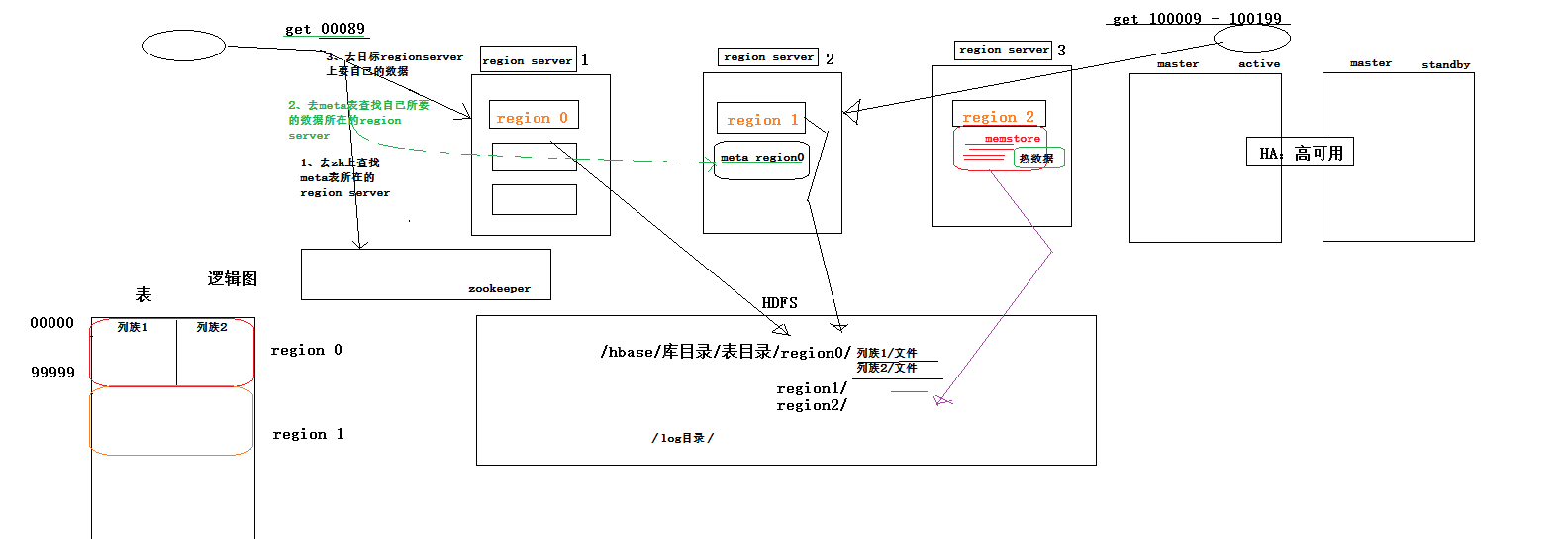
然後使用HBASE的話你要先有自己的Hadoop集群,保證hdfs是正常的,還有zookeeper是正常的,就這兩點。
安裝還是很簡單的
解壓hbase安裝包
修改hbase-env.sh
|
export JAVA_HOME=/root/apps/jdk1.7.0_67 export HBASE_MANAGES_ZK=false |
修改hbase-site.xml
|
<configuration> <!-- 指定hbase在HDFS上存儲的路徑 --> <property> <name>hbase.rootdir</name> <value>hdfs://hdp-01:9000/hbase</value> </property> <!-- 指定hbase是分散式的 --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 指定zk的地址,多個用“,”分割 --> <property> <name>hbase.zookeeper.quorum</name> <value>hdp-01:2181,hdp-02:2181,hdp-03:2181,hdp-04:2181</value> </property> </configuration>
|
修改 regionservers
|
hdp-01 hdp-02 hdp-03 hdp-04 |
bin/start-hbase.sh
啟動完後,還可以在集群中找任意一臺機器啟動一個備用的master
bin/hbase-daemon.sh start master
新啟的這個master會處於backup狀態
如果報錯了,在這看錯誤,註意時間錯誤、
HBASE的對外埠是16010
同時也可以啟動一個備用的master,在啟動之後,隨便在一臺機器上,
Bin/hbase-daemon.sh start master
同時也可以試著訪問這個頁面

這hbase的系統表記錄的是數據的索引表,記錄哪個範圍的數據儲存在哪個regionserver
3. 啟動hbase的命令行客戶端
bin/hbase shell
Hbase> list // 查看表
Hbase> status // 查看集群狀態
Hbase> version // 查看集群版本
1.1. HBASE表模型
hbase的表模型跟mysql之類的關係型資料庫的表模型差別巨大
hbase的表模型中有:行的概念;但沒有欄位的概念
行中存的都是key-value對,每行中的key-value對中的key可以是各種各樣,每行中的key-value對的數量也可以是各種各樣
1.1.1. hbase表模型的要點:
1、一個表,有表名
2、一個表可以分為多個列族(不同列族的數據會存儲在不同文件中)
3、表中的每一行有一個“行鍵rowkey”,而且行鍵在表中不能重覆
4、表中的每一對kv數據稱作一個cell
5、hbase可以對數據存儲多個歷史版本(歷史版本數量可配置)
6、整張表由於數據量過大,會被橫向切分成若幹個region(用rowkey範圍標識),不同region的數據也存儲在不同文件中
7、hbase會對插入的數據按順序存儲:
要點一:首先會按行鍵排序
要點二:同一行裡面的kv會按列族排序,再按k排序
1.1. hbase命令行客戶端操作
1.1.1.1. 建表:
create 't_user_info','base_info','extra_info'
表名 列族名 列族名
1.1.1.2. 插入數據:
|
hbase(main):011:0> put 't_user_info','001','base_info:username','zhangsan' 0 row(s) in 0.2420 seconds
hbase(main):012:0> put 't_user_info','001','base_info:age','18' 0 row(s) in 0.0140 seconds
hbase(main):013:0> put 't_user_info','001','base_info:sex','female' 0 row(s) in 0.0070 seconds
hbase(main):014:0> put 't_user_info','001','extra_info:career','it' 0 row(s) in 0.0090 seconds
hbase(main):015:0> put 't_user_info','002','extra_info:career','actoress' 0 row(s) in 0.0090 seconds
hbase(main):016:0> put 't_user_info','002','base_info:username','liuyifei' 0 row(s) in 0.0060 seconds |
1.1.1.3. 查詢數據方式一:scan 掃描
|
hbase(main):017:0> scan 't_user_info' ROW COLUMN+CELL 001 column=base_info:age, timestamp=1496567924507, value=18 001 column=base_info:sex, timestamp=1496567934669, value=female 001 column=base_info:username, timestamp=1496567889554, value=zhangsan 001 column=extra_info:career, timestamp=1496567963992, value=it 002 column=base_info:username, timestamp=1496568034187, value=liuyifei 002 column=extra_info:career, timestamp=1496568008631, value=actoress 2 row(s) in 0.0420 seconds |
1.1.1.4. 查詢數據方式二:get 單行數據
|
hbase(main):020:0> get 't_user_info','001' COLUMN CELL base_info:age timestamp=1496568160192, value=19 base_info:sex timestamp=1496567934669, value=female base_info:username timestamp=1496567889554, value=zhangsan extra_info:career timestamp=1496567963992, value=it 4 row(s) in 0.0770 seconds |
1.1.1.5. 刪除一個kv數據
|
hbase(main):021:0> delete 't_user_info','001','base_info:sex' 0 row(s) in 0.0390 seconds |
刪除整行數據:
|
hbase(main):024:0> deleteall 't_user_info','001' 0 row(s) in 0.0090 seconds
hbase(main):025:0> get 't_user_info','001' COLUMN CELL 0 row(s) in 0.0110 seconds |
1.1.1.6. 刪除整個表:
|
hbase(main):028:0> disable 't_user_info' 0 row(s) in 2.3640 seconds
hbase(main):029:0> drop 't_user_info' 0 row(s) in 1.2950 seconds
hbase(main):030:0> list TABLE 0 row(s) in 0.0130 seconds
=> []
|
1.1. Hbase重要特性--排序特性(行鍵)
插入到hbase中去的數據,hbase會自動排序存儲:
排序規則: 首先看行鍵,然後看列族名,然後看列(key)名; 按字典順序
Hbase的這個特性跟查詢效率有極大的關係
比如:一張用來存儲用戶信息的表,有名字,戶籍,年齡,職業....等信息
然後,在業務系統中經常需要:
查詢某個省的所有用戶
經常需要查詢某個省的指定姓的所有用戶
思路:如果能將相同省的用戶在hbase的存儲文件中連續存儲,並且能將相同省中相同姓的用戶連續存儲,那麼,上述兩個查詢需求的效率就會提高!!!
做法:將查詢條件拼到rowkey內
當我們創建一個表之後,按道理說應該是可以在hdfs裡面查看到數據的。但是。。。。
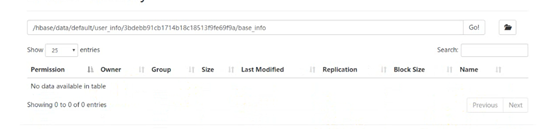
這裡面沒有數據,卻能查到,那麼數據到底存在哪呢,這些數據會存在記憶體中,這塊記憶體空間叫做memstore,因為這樣會快一點,他會把熱數據放到這裡面,就是剛剛訪問過的數據,他會先放到記憶體中,但如果這時候宕機了怎麼辦,數據會丟嗎,不會丟,他一方面會寫數據,一方面會寫日誌,放在hdfs的日誌目錄里
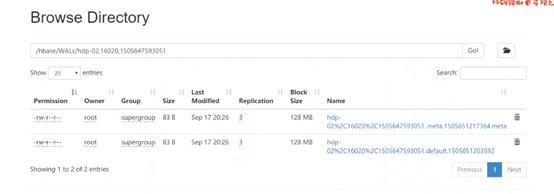
當記憶體中寫滿了,就會寫到hdfs里
可以試一下,當你停一下,你就會發現hdfs裡面就有數據了
布隆過濾器的功能:判斷一個數據以前是否出現過
布隆過濾器的原理:把一個數據通過演算法轉化成只有01的二進位數據,
然後用一個比較大的數組來存,每一個數據的01都存到這個數組裡面,註意他們是相互疊加的比如一個數據1位置有1,3位置有1,另一個數據1位置有1,4位置有1,那麼加入後就是1位置有1,3位置有1,4位置有1,如果再來一個數據的01,1位置有1,5位置有1,那麼可以判斷,這個數據是從來沒有出現過的,
所以布隆過濾器一個可以判斷出沒有出現過的數據,
而他判斷出出現過的數據卻有可能是沒出現過的。
他在HBASE的應用啊,比如說,region Server管理的一個表的列族,他的真實存放位置是hdfs,在hdfs的某個目錄下。而且他這個列族文件不止一個,比如,當這個列族的數據改變的時候,他會生成一個新的文件,因為他沒發修改hdfs里的文件,或者就算不改,列族裡有許許多多的key,value,他們也會放在這個目錄下的不同文件裡面
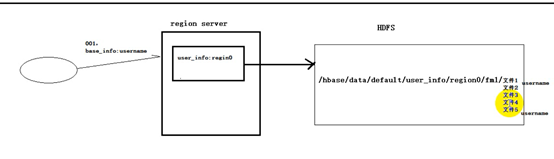
每個文件都有個布隆過濾器,它是由這個文件kv的二進位值決定,當你要查詢一個數據的話,他會先那這個數據的二進位值和某個文件的布隆過濾器比一下,如果匹配了,他就會找這個文件
關於java的一些api
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Admin; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.regionserver.BloomType; import org.junit.Before; import org.junit.Test; /** * * 1、構建連接 * 2、從連接中取到一個表DDL操作工具admin * 3、admin.createTable(表描述對象); * 4、admin.disableTable(表名); 5、admin.deleteTable(表名); 6、admin.modifyTable(表名,表描述對象); * * @author hunter.d * */ public class HbaseClientDDL { Connection conn = null; @Before public void getConn() throws Exception{ // 構建一個連接對象 Configuration conf = HBaseConfiguration.create(); // 會自動載入hbase-site.xml conf.set("hbase.zookeeper.quorum", "hdp-01:2181,hdp-02:2181,hdp-03:2181,hdp-04:2181"); conn = ConnectionFactory.createConnection(conf); } /** * DDL * @throws Exception */ @Test public void testCreateTable() throws Exception{ // 從連接中構造一個DDL操作器 Admin admin = conn.getAdmin(); // 創建一個表定義描述對象 HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf("user_info")); // 創建列族定義描述對象 HColumnDescriptor hColumnDescriptor_1 = new HColumnDescriptor("base_info"); hColumnDescriptor_1.setMaxVersions(3); // 設置該列族中存儲數據的最大版本數,預設是1 HColumnDescriptor hColumnDescriptor_2 = new HColumnDescriptor("extra_info"); // 將列族定義信息對象放入表定義對象中 hTableDescriptor.addFamily(hColumnDescriptor_1); hTableDescriptor.addFamily(hColumnDescriptor_2); // 用ddl操作器對象:admin 來建表 admin.createTable(hTableDescriptor); // 關閉連接 admin.close(); conn.close(); } /** * 刪除表 * @throws Exception */ @Test public void testDropTable() throws Exception{ Admin admin = conn.getAdmin(); // 停用表 admin.disableTable(TableName.valueOf("user_info")); // 刪除表 admin.deleteTable(TableName.valueOf("user_info")); admin.close(); conn.close(); } // 修改表定義--添加一個列族 @Test public void testAlterTable() throws Exception{ Admin admin = conn.getAdmin(); // 取出舊的表定義信息 HTableDescriptor tableDescriptor = admin.getTableDescriptor(TableName.valueOf("user_info")); // 新構造一個列族定義 HColumnDescriptor hColumnDescriptor = new HColumnDescriptor("other_info"); hColumnDescriptor.setBloomFilterType(BloomType.ROWCOL); // 設置該列族的布隆過濾器類型 // 將列族定義添加到表定義對象中 tableDescriptor.addFamily(hColumnDescriptor); // 將修改過的表定義交給admin去提交 admin.modifyTable(TableName.valueOf("user_info"), tableDescriptor); admin.close(); conn.close(); } /** * DML -- 數據的增刪改查 */ }
import java.util.ArrayList; import java.util.Iterator; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellScanner; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Delete; import org.apache.hadoop.hbase.client.Get; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.ResultScanner; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.client.Table; import org.apache.hadoop.hbase.util.Bytes; import org.junit.Before; import org.junit.Test; public class HbaseClientDML { Connection conn = null; @Before public void getConn() throws Exception{ // 構建一個連接對象 Configuration conf = HBaseConfiguration.create(); // 會自動載入hbase-site.xml conf.set("hbase.zookeeper.quorum", "hdp-01:2181,hdp-02:2181,hdp-03:2181"); conn = ConnectionFactory.createConnection(conf); } /** * 增 * 改:put來覆蓋 * @throws Exception */ @Test public void testPut() throws Exception{ // 獲取一個操作指定表的table對象,進行DML操作 Table table = conn.getTable(TableName.valueOf("user_info")); // 構造要插入的數據為一個Put類型(一個put對象只能對應一個rowkey)的對象 Put put = new Put(Bytes.toBytes("001")); put.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("張三")); put.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("age"), Bytes.toBytes("18")); put.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("addr"), Bytes.toBytes("北京")); Put put2 = new Put(Bytes.toBytes("002")); put2.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("李四")); put2.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("age"), Bytes.toBytes("28")); put2.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("addr"), Bytes.toBytes("上海")); ArrayList<Put> puts = new ArrayList<>(); puts.add(put); puts.add(put2); // 插進去 table.put(puts); table.close(); conn.close(); } /** * 迴圈插入大量數據 * @throws Exception */ @Test public void testManyPuts() throws Exception{ Table table = conn.getTable(TableName.valueOf("user_info")); ArrayList<Put> puts = new ArrayList<>(); for(int i=0;i<100000;i++){ Put put = new Put(Bytes.toBytes(""+i)); put.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("張三"+i)); put.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("age"), Bytes.toBytes((18+i)+"")); put.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("addr"), Bytes.toBytes("北京")); puts.add(put); } table.put(puts); } /** * 刪 * @throws Exception */ @Test public void testDelete() throws Exception{ Table table = conn.getTable(TableName.valueOf("user_info")); // 構造一個對象封裝要刪除的數據信息 Delete delete1 = new Delete(Bytes.toBytes("001")); Delete delete2 = new Delete(Bytes.toBytes("002")); delete2.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("addr")); ArrayList<Delete> dels = new ArrayList<>(); dels.add(delete1); dels.add(delete2); table.delete(dels); table.close(); conn.close(); } /** * 查 * @throws Exception */ @Test public void testGet() throws Exception{ Table table = conn.getTable(TableName.valueOf("user_info")); Get get = new Get("001".getBytes()); Result result = table.get(get); // 從結果中取用戶指定的某個key的value byte[] value = result.getValue("base_info".getBytes(), "age".getBytes()); System.out.println(new String(value)); System.out.println("-------------------------"); // 遍歷整行結果中的所有kv單元格 CellScanner cellScanner = result.cellScanner(); while(cellScanner.advance()){ Cell cell = cellScanner.current(); byte[] rowArray = cell.getRowArray(); //本kv所屬的行鍵的位元組數組 byte[] familyArray = cell.getFamilyArray(); //列族名的位元組數組 byte[] qualifierArray = cell.getQualifierArray(); //列名的位元組數據 byte[] valueArray = cell.getValueArray(); // value的位元組數組 System.out.println("行鍵: "+new String(rowArray,cell.getRowOffset(),cell.getRowLength())); System.out.println("列族名: "+new String(familyArray,cell.getFamilyOffset(),cell.getFamilyLength())); System.out.println("列名: "+new String(qualifierArray,cell.getQualifierOffset(),cell.getQualifierLength())); System.out.println("value: "+new String(valueArray,cell.getValueOffset(),cell.getValueLength())); } table.close(); conn.close(); } /** * 按行鍵範圍查詢數據 * @throws Exception */ @Test public void testScan() throws Exception{ Table table = conn.getTable(TableName.valueOf("user_info")); // 包含起始行鍵,不包含結束行鍵,但是如果真的想查詢出末尾的那個行鍵,那麼,可以在末尾行鍵上拼接一個不可見的位元組(\000) Scan scan = new Scan("10".getBytes(), "10000\001".getBytes()); ResultScanner scanner = table.getScanner(scan); Iterator<Result> iterator = scanner.iterator(); while(iterator.hasNext()){ Result result = iterator.next(); // 遍歷整行結果中的所有kv單元格 CellScanner cellScanner = result.cellScanner(); while(cellScanner.advance()){ Cell cell = cellScanner.current(); byte[] rowArray = cell.getRowArray(); //本kv所屬的行鍵的位元組數組 byte[] familyArray = cell.getFamilyArray(); //列族名的位元組數組 byte[] qualifierArray = cell.getQualifierArray(); //列名的位元組數據 byte[] valueArray = cell.getValueArray(); // value的位元組數組 System.out.println("行鍵: "+new String(rowArray,cell.getRowOffset(),cell.getRowLength())); System.out.println("列族名: "+new String(familyArray,cell.getFamilyOffset(),cell.getFamilyLength())); System.out.println("列名: "+new String(qualifierArray,cell.getQualifierOffset(),cell.getQualifierLength())); System.out.println("value: "+new String(valueArray,cell.getValueOffset(),cell.getValueLength())); } System.out.println("----------------------"); } } }


