
簡介 簡介 web1.0時代 web2.0時代 互聯網時代 互聯網+ --》智慧城市。 2012年提出。 雲計算+大數據時代 背景 背景 隨著互聯網的發展,網站應用的規模不斷擴大,常規的垂直應用架構已無法應對,分散式服務架構以及流動計算架構勢在必行,亟需一個治理系統確保架構有條不紊的演進。 1、第一 ...
簡介
web1.0時代
web2.0時代
互聯網時代 互聯網+ --》智慧城市。 2012年提出。
雲計算+大數據時代
背景
隨著互聯網的發展,網站應用的規模不斷擴大,常規的垂直應用架構已無法應對,分散式服務架構以及流動計算架構勢在必行,亟需一個治理系統確保架構有條不紊的演進。
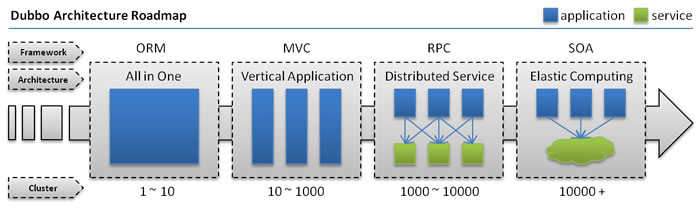
1、第一時期
單一應用架構
all in one(所有的模塊在一起,技術也不分層)

網站的初期,也認為互聯網發展的最早時期。會在單機部署上所有的應用程式和軟體。
所有的代碼都是寫在JSP裡面,所有的代碼都寫在一起。這種方式稱為all in one。
特點:
1、不具備代碼的可維護性。
2、容錯性差。
因為我們所有的代碼都寫在JSP頁里。當用戶或某些原因發生異常。(1、用戶直接看到異常錯誤信息。2、這個錯誤會導致伺服器宕機)
容錯性,是指軟體檢測應用程式所運行的軟體或硬體中發生的錯誤並從錯誤中恢復的能力,通常可以從系統的可靠性、可用性、可測性等幾個方面來衡量。
單體地獄。:只需一個應用,將所有功能都部署在一起,以減少部署節點和成本。
2 第一時期後階段
解決方案:
1、分層開發(提高維護性)【解決容錯性】
2、MVC架構(Web應用程式的設計模式)
3、伺服器的分離部署
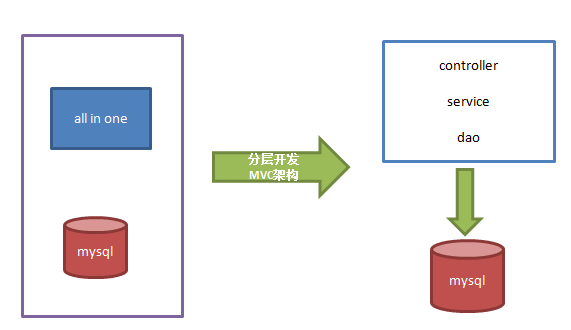
特點:
1、MVC分層開發(解決容錯性問題)
2、資料庫和項目部署分離
問題:
隨著用戶的訪問量持續增加,單台應用伺服器已經無法滿足需求。
解決方案:
集群。
3 可能會產生的幾個問題:
1.1. 高可用
“高可用性”(High Availability)通常來描述一個系統經過專門的設計,從而減少停工時間,而保持其服務的高度可用性。(一直都能用)
1.2. 高併發
高併發(High Concurrency)是互聯網分散式系統架構設計中必須考慮的因素之一,它通常是指,通過設計保證系統能夠同時並行處理很多請求。
高併發相關常用的一些指標有響應時間(Response Time),吞吐量(Throughput),每秒查詢率QPS(Query Per Second),併發用戶數等。
響應時間:系統對請求做出響應的時間。例如系統處理一個HTTP請求需要200ms,這個200ms就是系統的響應時間。
吞吐量:單位時間內處理的請求數量。
QPS:每秒響應請求數。在互聯網領域,這個指標和吞吐量區分的沒有這麼明顯。
併發用戶數:同時承載正常使用系統功能的用戶數量。例如一個即時通訊系統,同時線上量一定程度上代表了系統的併發用戶數。
1.2.1. 提升系統的併發能力
提高系統併發能力的方式,方法論上主要有兩種:垂直擴展(Scale Up)與水平擴展(Scale Out)。
1. 垂直擴展
垂直擴展:提升單機處理能力。垂直擴展的方式又有兩種:
(1)增強單機硬體性能,例如:增加CPU核數如32核,升級更好的網卡如萬兆,升級更好的硬碟如SSD,擴充硬碟容量如2T,擴充系統記憶體如128G;
(2)提升單機架構性能,例如:使用Cache來減少IO次數,使用非同步來增加單服務吞吐量,使用無鎖數據結構來減少響應時間;
在互聯網業務發展非常迅猛的早期,如果預算不是問題,強烈建議使用“增強單機硬體性能”的方式提升系統併發能力,因為這個階段,公司的戰略往往是發展業務搶時間,而“增強單機硬體性能”往往是最快的方法。
總結:不管是提升單機硬體性能,還是提升單機架構性能,都有一個致命的不足:單機性能總是有極限的。所以互聯網分散式架構設計高併發終極解決方案還是水平擴展。
2. 水平擴展
水平擴展:只要增加伺服器數量,就能線性擴充系統性能。水平擴展對系統架構設計是有要求的,難點在於:如何在架構各層進行可水平擴展的設計,
可擴展性。
1.3. 高性能
高性能(High Performance)就是指程式處理速度快,所占記憶體少,cpu低
4、集群操作
集群:同一個業務,部署在多個伺服器上。
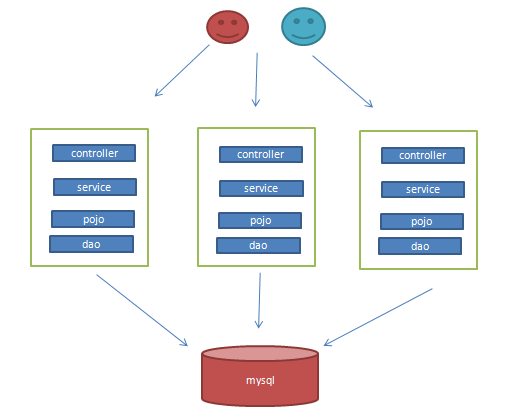
特點:
1、項目採用多台伺服器(集群)部署
優點:
支持高併發。
支持高可用。
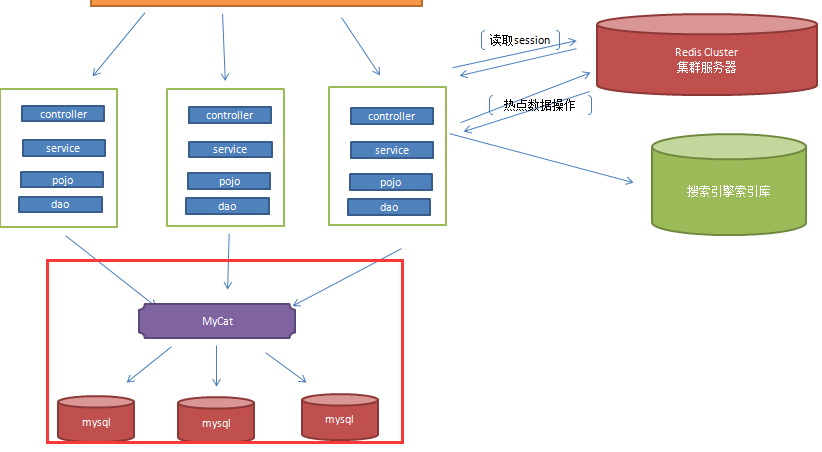
問題1: Session如何共用?
答: Redlis Cluster集群方案
問題2:這些集群的伺服器,用戶的請求該往哪裡進行轉發?
答: 用nginx伺服器來完成分發請求。實現負載均衡策略機制。
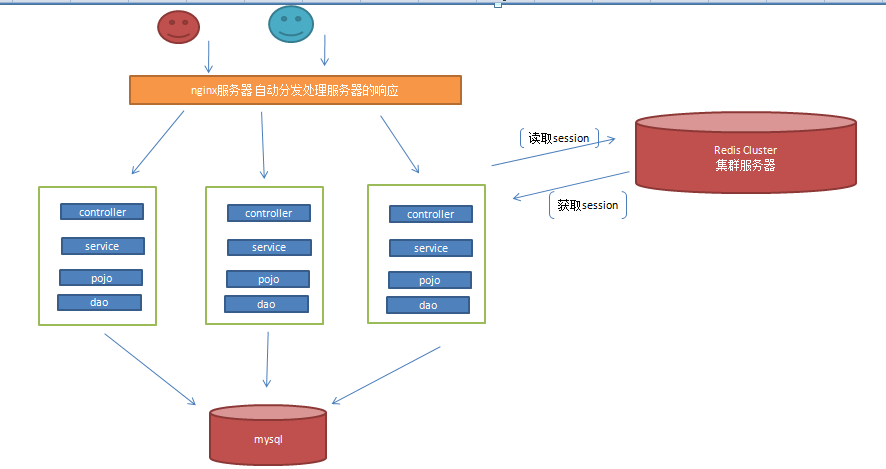
註意:很多IT公司用的都是這種架構需求
資料庫壓力變大
我們能過集群方案nginx+tomcat將應用層的性能進行有效的提升。但是資料庫的負載奪力慢慢增加。怎麼來搞高資料庫層面的訪問壓力(負載)?
解決方案:
讀寫分離
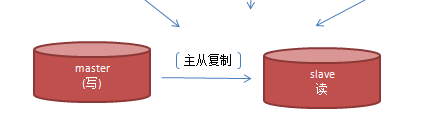
讀寫分離:主從資料庫之間進行數據同步。master負載增刪改操作。 slave負載讀操作。
mysql本身就提供了master-slave的方式完成主從複製功能。
使用搜索引擎緩解資料庫的訪問壓力+能力
資料庫做讀庫的情況下,資料庫本身對模糊查詢的功能支持不是特別優秀,像電商類的網站,搜索是非常核心的功能模塊。即使做了讀寫分離。這個問題也不能有效解決電商網站查詢(分詞技術)等。針對於該問題,有必要引入搜索引擎技術。
目前非常主流的搜索引擎技術:
solr elasticsearch whoosh

引入緩存機制減輕資料庫的訪問壓力
隨著訪問量的持續增加,資料庫的訪問壓力變的越來越大(雖然做了主從複製)。對於這些熱點數據(用戶訪問頻繁的信息),如果每都到資料庫中進行查詢。(很多通用查詢的功能)。
放在記憶體中又不特別合適。(手機登錄驗證碼操作、為了IP限制頻繁訪問伺服器...) 嘗試使用Redis.
資料庫的水平/垂直拆分。
垂直擴展 能力終歸還是有限的。
單個表: 1000萬--》1個億數據 (單個表的數據能力終歸還是有限的)
表:垂直拆分。
id ,name,age,bire..tel...remark....
熱數據/冷數據 --》垂直拆分方案。
表:水平拆分。
按照:時間、地區、(按照業務邏輯進行拆分)。
分庫分表:
採用第三方資料庫中間件:mycat sharding-jdbc drds(阿裡)
當前狀態特點:
通過設計保證高可用、高併發。
(不斷的對伺服器進行擴容...)
問題1:伺服器價錢?(伺服器維護成本、人工維護)?
問題2:可維護性差。
問題3:可擴展性差(組件重用性基本沒有)
問題4:協同開發不方便。(大家都去改相同的業務代碼。易發生代碼錯誤/衝突)
問題5:單體架構(隨著業務的不斷增加,代碼會變得越來越多)。導致服務部署時,文件變的越來越大。


