
"分散式架構" "CAP 與 BASE 理論" "一致性協議" "初識 Zookeeper" "Zookeeper 介紹" "Zookeeper 工作機制" "Zookeeper 特點" "Zookeeper 數據結構" "Zookeeper 應用場景" "統一命名服務" "統一配置管理" "統一集 ...
分散式架構
CAP 與 BASE 理論
cap 定理:
一個分散式系統不可能同時滿足一致性 (C:Consistency)、可用性(A:Availability)和分區容錯性(P:Partition tolerance)這三個基本要求,最多只能同時滿足其中的兩項。
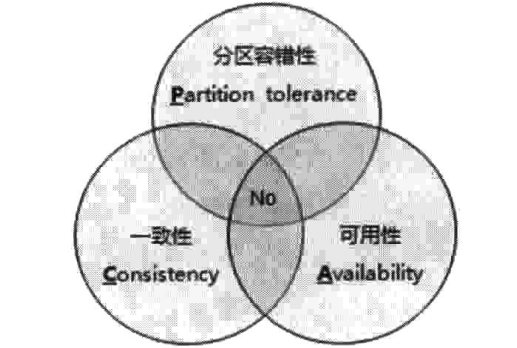
我們需要明確一點,對於一個分散式系統而言,分區容錯性是一個最基本的要求,既然是一個分散式系統,那麼分散式系統中的組件必然需要被部署到不同的節點,否則也就無所謂分散式系統了。因此我們一般把精力花在如何根據業務特點在 C 和 A 之間尋求平衡。
base 理論:
BASE 是 Basically Available (基本可用),Soft state (軟狀態)和 Eventually consistent (最終一致性) 三個短語的簡寫,BASE 是對 CAP 中一致性和可用性權衡的結果,其核心思想是即使無法做到強一致性,但每個應用都可以根據自身的業務特點,採用適當的方式來使系統達到最終一致性。
一致性協議
- 2 PC
- 3 PC
- Paxos 演算法
初識 Zookeeper
Zookeeper 介紹
Zookeeper 是一個開源的分散式的(多台機器一起工作),為分散式應用提供協調服務的 Apache 項目。
ZooKeeper 工作機制
Zookeeper從設計模式角度來理解:是一個基於觀察者模式設計的分散式服務管理框架,它負責存儲和管理大家都關心的數據,然後接受觀察者的註冊,一旦這些數據的狀態發生變化,Zookeeper 就將負責通知已經在 Zookeeper 上註冊的那些觀察者做出相應的反應。
例子:
服務端啟動時去註冊信息(創建的都是臨時節點);客戶端獲取當前線上伺服器列表,並註冊監聽;當伺服器節點下線,伺服器節點下線事件通知客戶端,客戶端重新去獲取伺服器列表,並註冊監聽。
Zookeeper = 文件系統 + 通知機制
Zookeeper 特點
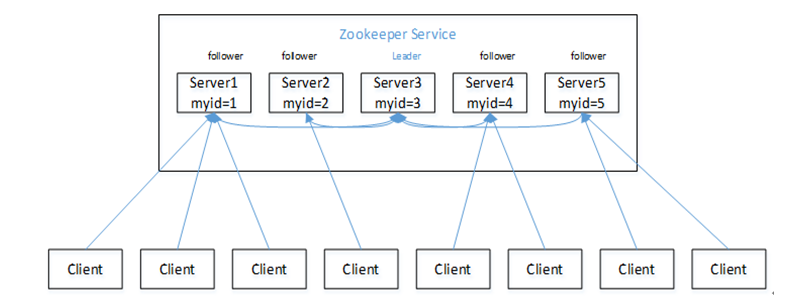
- 一個 領導者(leader),多個跟隨者(follower)組成的集群
- 集群中只要有半數以上節點存活,Zookeeper集群就能正常服務。因此伺服器最好設奇數台。
- 全局數據一致性:每台伺服器保存一份相同的數據副本,Client 無論連接到哪個 Server,數據都是一致性的。
- 更新請求順序進行,來自同一個 Client 的更新請求按其發送順序依次執行。
- 數據更新原子性,一次數據更新要麼成功,要麼失敗。典型的事務原子性。
- 實時性,在一定時間範圍內,Client 能讀取到最新的數據。
Zookeeper 數據結構
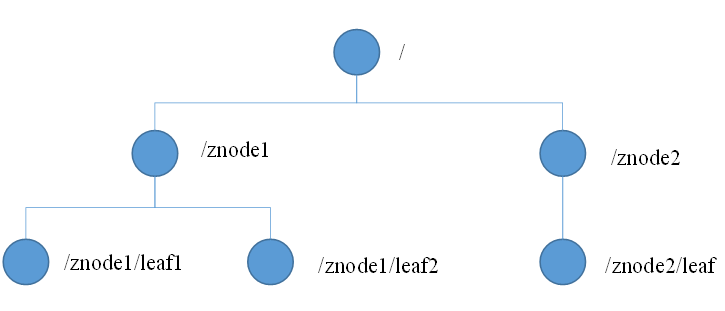
Zk 數據模型的結構整體上可以看作一棵樹,每個節點稱作一個 ZNode。每個 ZNode 預設能夠存儲 1MB 的數據,每個 ZNode 都是通過其路徑唯一標識的
Zookeeper 應用場景
zk 提供的服務包括:統一命名服務、統一配置管理、統一集群管理、伺服器節點動態上下線、軟負載均衡等。
統一命名服務
在分散式環境下,經常需要對應用/服務進行統一命名,便於識別
例如:IP 地址難記,但是功能變數名稱好記。如下圖,將 www.baidu.com 這個功能變數名稱與旗下的三個 伺服器 IP 地址對應起來,當訪問 www.baidu.com 的時候自動從三個 IP 地址中選一個進行訪問。

統一配置管理
- 分散式環境下,配置文件同步非常常見。
- 一般要求一個集群中,所有節點的配置信息是一致的,比如 Kafka 集群。
- 對配置文件修改後,希望能夠快速同步到各個節點上。
- 配置管理可交給 ZooKeeper 實現。
- 可以將配置信息寫入 Zookeeper 上的一個 ZNode。
- 各個客戶端伺服器監聽這個 ZNode。
- 一旦 ZNode 中的數據被修改,ZooKeeper 將通知各個客戶端伺服器。

統一集群管理
- 分散式環境中,實時掌握每個節點的狀態是必要的。
- 可根據節點實時狀態做出一些調整。
- Zookeeper 可以實現實時監控節點狀態變化
- 可以將節點信息寫入 Zookeeper 上的一個 ZNode。
- 監聽這個 ZNode 可獲取它的實時狀態變化。
服務上下線
客戶端能夠實時洞察到伺服器上下線的變化。服務端啟動時去註冊信息(創建的都是臨時節點);客戶端獲取當前線上伺服器列表,並註冊監聽;當伺服器節點下線,伺服器節點下線事件通知客戶端,客戶端重新去獲取伺服器列表,並註冊監聽。
軟負載均衡
在 Zookeeper 中記錄每台伺服器的訪問數,讓訪問數最少的伺服器去處理最新的客戶端請求。
Zookeeper 內部原理
選舉機制
- 半數機制:集群中半數以上的機器存活,集群可用。所以 Zookeeper 適合安裝奇數台伺服器
- ZooKeeper 在沒有 Master 和 Slave,但是 ZooKeeper 工作時是分為 Leader 和 Follower 的。Leader 只有一個,是通過內部選舉機制臨時產生的。
例子:

假設有五台伺服器組成的 ZooKeeper 集群,他們的 id 從 1-5,同時它們都是剛剛啟動的。假設這些伺服器依序啟動:
- 伺服器 1 啟動,現在只有它自己一臺伺服器,它發出去的報文沒有任何響應,因此它的選舉狀態一直是 LOOKING 狀態。
- 伺服器 2 啟動,它與最開始啟動的伺服器 1 進行通信。這時候 1 自己有自己一票,還投了 id 大的伺服器,即 2 一票,2 有自己的一票和 1 的一票,共兩票。因此 id 值大的 伺服器 2 勝出,但是沒有達到超過半數以上的伺服器都同意選舉它(由於這個例子有 5 台伺服器,因此需要3台同意,即擁有 3 票)。所以伺服器 1、2 還是繼續保持 LOOKING 狀態。
- 伺服器 3 啟動,過程和 2 相同,因此 3 有 三票,2 有 2 票,1 有 1 票,伺服器 3 三票超過一半,成功成為 Leader 。
- 伺服器 4 ,由於 3 已經是 Leader 因此它只能作為 Follower。
- 伺服器 5 也類似,只能作為 Follower。
節點類型
- 持久(Persistent):客戶端和伺服器端斷開連接後,創建的節點不刪除
- 持久化目錄節點:客戶端與 Zookeeper 斷開連接後,該節點依舊存在
- 持久化順序編號目錄節點:客戶端與 Zookeeper 斷開連接後,該節點依舊存在,只是 Zookeeper 給該節點名稱進行順序編號。
- 短暫(Ephemeral):客戶端和伺服器端斷開連接後,創建的節點自己刪除(伺服器上下線)
- 臨時目錄節點:客戶端與 ZooKeeper 斷開連接後,該節點被刪除。
- 客戶端與 ZooKeeper 斷開連接後,該節點被刪除,只是 ZooKeeper 給該節點名稱進行順序編號。

說明:創建 ZNode 時設置順序標識,ZNode 名稱後會附加一個值,順序號是一個單調遞增的計數器,由父節點維護。在分散式系統中,順序號可用被用於為所有的事件進行全局排序,這樣客戶端可用通過順序號來推斷事件的順序。
監聽器原理
- 監聽器原理
- 首先有個 main 線程
- 在 main 線程中啟動 Zookeeper 客戶端,這時會創建兩個線程,一個負責網路連接通信(connect),一個負責監聽(listenner)。
- 通過 connect 線程將註冊的監聽事件發送給 zookeeper。
- 在 zookeeper 的註冊監聽器列表中將註冊的監聽事件添加到列表中。
- Zookeeper 監聽到由數據或者路徑發生變化,就會將這個消息發送給 listenner 線程。
- listenner 線程內部調用了 process()方法。
- 常用的監聽
- 監聽節點數據的變化:get path[watch]
- 監聽子節點增減的變化:ls path[watch]

寫數據流程
- 假設Client 向 Zookeeper 上的 Server 1 寫數據,發送一個寫請求。
- 如果 Server 1 不是 Leader,那麼 Server 1 會把接受到的請求進一步發送給 Leader,因為每個 ZooKeeper 的伺服器集群裡面有一個 是 Leader,這個 Leader 會將所有寫請求廣播給各個 Server。各個 Server 寫成功後就會通知 Leader
- 當 Leader 收到大多數 Server 數據寫成功了,那麼就說明數據寫成功了,如果有三台伺服器,只要有兩台寫成功了,那麼就認為數據寫成功了,寫成功後,Leader 告訴 Server 1 數據寫成功了。
- Server 1 會進一步通知 Client 數據寫成功了,這時就會認為整個寫操作成功。
自我小結
Zookeeper 是一個採用 ZAB 作為數據一致性協議的分散式數據一致性協調框架。ZooKeeper 可以作為分散式配置管理,集群服務,數據發佈/訂閱,服務註冊/發現,分散式鎖等的實現。其內部採用 ZNode 節點維護一系列數據,當數據改變的時候可以通過 watche 機制告訴客戶端。當 ZooKeeper 作為分散式消息系統的管理,如 Kafka 的管理時,可以將所有 Kafka 伺服器,即所有的 Broker 的信息寫入 ZooKeeper 節點中,當加伺服器時只要在節點下加入一個臨時子節點,伺服器宕機或下線時臨時子節點將會自動刪除。很容易實現伺服器的集群管理。不光如此,ZooKeeper也可以用來維護 Topic 主題和 Producer 和Consumer 等的信息。當 ZooKeeper 作為分散式服務框架的註冊中心時,可以將服務註冊到 ZooKeeper 節點上,每個服務對應一個節點,子節點就是所有提供了該服務的機器的地址。每當有一個服務提供者啟動的時候都會網對應的服務節點下創建自己的臨時節點,存放自己的地址信息。消費者需要某個服務的時候只需要到對應的服務節點中隨便取一個子節點然後使用該服務就行了。監控中心可以很容易的通過現有的節點監控信息。
ZooKeeper 集群中會自動選舉一個 Leader 伺服器負責事務的操作,其餘的 Follower伺服器可以處理非事務操作、參與 Leader 伺服器的投票等。而 Observer 伺服器只能處理非事務的操作,但是不能參與任何投票。
總之,ZooKeeper 常用來維護各種分散式應用的一個狀態,使得分散式應用本身無狀態,只需要向 ZooKeeper 註冊自己的狀態,當需要某種狀態的時候直接去 ZooKeeper 上取就行了。當自己關註的消息發生變化時,ZooKeeper 會通過 Watche 進行通知,自己再進行對應的處理即可。


