
背景 1. SQLSERVER資料庫中單表數據幾十億,分區方案也已經無法查詢出結果。故:採用導出功能,導出數據到Text文本(文本 40G)中。 2. 因上原因,所以本次的實驗樣本為:【數據量:61w條,文本大小:74M】 選擇DataX原因 1. 試圖維持統一的異構數據源同步方案。(其實行不通) ...
背景
- SQLSERVER資料庫中單表數據幾十億,分區方案也已經無法查詢出結果。故:採用導出功能,導出數據到Text文本(文本>40G)中。
因上原因,所以本次的實驗樣本為:【數據量:61w條,文本大小:74M】
選擇DataX原因
- 試圖維持統一的異構數據源同步方案。(其實行不通)
試圖進入Hive時,已經是壓縮ORC格式,降低存儲大小,提高列式查詢效率,以便後續查詢HIVE數據導入KUDU時提高效率(其實行不通)
1. 建HIVE表
進入HIVE,必須和TextFile中的欄位類型保持一致
create table event_hive_3(
`#auto_id` string
,`#product_id` int
,`#event_name` string
,`#part_date` int
,`#server_id` int
,`#account_id` bigint
,`#user_id` bigint
,part_time STRING
,GetItemID bigint
,ConsumeMoneyNum bigint
,Price bigint
,GetItemCnt bigint
,TaskState bigint
,TaskType bigint
,BattleLev bigint
,Level bigint
,ItemID bigint
,ItemCnt bigint
,MoneyNum bigint
,MoneyType bigint
,VIP bigint
,LogID bigint
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS ORC;2. 建Kudu表
這個過程,自行發揮~
#Idea中,執行單元測試【EventAnalysisRepositoryTest.createTable()】即可
public void createTable() throws Exception {
repository.getClient();
repository.createTable(Event_Sjmy.class,true);
}3. 建立Impala表
進入Impala-shell 或者hue;
use sd_dev_sdk_mobile;
CREATE EXTERNAL TABLE `event_sjmy_datax` STORED AS KUDU
TBLPROPERTIES(
'kudu.table_name' = 'event_sjmy_datax',
'kudu.master_addresses' = 'sdmain:7051')4. 編輯Datax任務
不直接load進hive的目的是為了進行一步文件壓縮,降低記憶體占用,轉為列式存儲。
# 編輯一個任務
vi /home/jobs/textToHdfs.json;
{
"setting": {},
"job": {
"setting": {
"speed": {
"channel": 2
}
},
"content": [
{
"reader": {
"name": "txtfilereader",
"parameter": {
"path": ["/home/data"],
"encoding": "GB2312",
"column": [
{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "int"
},
{
"index": 2,
"type": "string"
},
{
"index": 3,
"type": "int"
},
{
"index": 4,
"type": "int"
},
{
"index": 5,
"type": "long"
},
{
"index": 6,
"type": "long"
},
{
"index": 7,
"type": "string"
},
{
"index": 8,
"type": "long"
},
{
"index": 9,
"type": "long"
},
{
"index": 10,
"type": "long"
},{
"index": 11,
"type": "long"
},{
"index": 12,
"type": "long"
},
{
"index": 13,
"type": "long"
},
{
"index": 14,
"type": "long"
},
{
"index": 15,
"type": "long"
},
{
"index": 17,
"type": "long"
},
{
"index": 18,
"type": "long"
},
{
"index": 19,
"type": "long"
},
{
"index": 20,
"type": "long"
},
{
"index": 21,
"type": "long"
}
],
"fieldDelimiter": "/t"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [{"name":"#auto_id","type":" STRING"},{"name":"#product_id","type":" int"},{"name":"#event_name","type":" STRING"},{"name":"#part_date","type":"int"},{"name":"#server_id","type":"int"},{"name":"#account_id","type":"bigint"},{"name":"#user_id","type":" bigint"},{"name":"part_time","type":" STRING"},{"name":"GetItemID","type":" bigint"},{"name":"ConsumeMoneyNum","type":"bigint"},{"name":"Price ","type":"bigint"},{"name":"GetItemCnt ","type":"bigint"},{"name":"TaskState ","type":"bigint"},{"name":"TaskType ","type":"bigint"},{"name":"BattleLev ","type":"bigint"},{"name":"Level","type":"bigint"},{"name":"ItemID ","type":"bigint"},{"name":"ItemCnt ","type":"bigint"},{"name":"MoneyNum ","type":"bigint"},{"name":"MoneyType ","type":"bigint"},{"name":"VIP ","type":"bigint"},{"name":"LogID ","type":"bigint"}],
"compress": "NONE",
"defaultFS": "hdfs://sdmain:8020",
"fieldDelimiter": "\t",
"fileName": "event_hive_3",
"fileType": "orc",
"path": "/user/hive/warehouse/dataxtest.db/event_hive_3",
"writeMode": "append"
}
}
}
]
}
}4.1 執行datax任務
註意哦,數據源文件,先放在/home/data下哦。數據源文件必須是個數據二維表。
#textfile中數據例子如下:
{432297B4-CA5F-4116-901E-E19DF3170880} 701 獲得籌碼 201906 2 4974481 1344825 00:01:06 0 0 0 0 0 0 0 0 0 0 100 2 3 31640
{CAAF09C6-037D-43B9-901F-4CB5918FB774} 701 獲得籌碼 201906 2 5605253 1392330 00:02:25 0 0 0 0 0 0 0 0 0 0 390 2 10 33865
cd $DATAX_HOME/bin
python datax.py /home/job/textToHdfs.json效果圖:
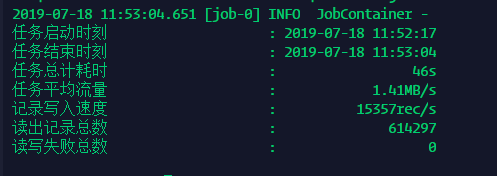
使用Kudu從HIVE讀取寫入到Kudu表中
進入shell
#進入shell:
impala-shell;
#選中庫--如果表名有指定庫名,可省略
use sd_dev_sdk_mobile;
輸入SQL:
INSERT INTO sd_dev_sdk_mobile.event_sjmy_datax
SELECT `#auto_id`,`#event_name`,`#part_date`,`#product_id`,`#server_id`,`#account_id`,`#user_id`,part_time,GetItemID,ConsumeMoneyNum,Price,GetItemCnt,TaskState,TaskType,BattleLev,Level,ItemID,ItemCnt,MoneyNum,MoneyType,VIP,LogID
FROM event_hive_3 ;效果圖:


看看這可憐的結果
這速度難以接受,我選擇放棄。
打臉環節-原因分析:
- DataX讀取TextFile到HIVE中的速度慢: DataX對TextFile的讀取是單線程的,(2.0版本後可能會提供多線程ReaderTextFile的能力),這直接浪費了集群能力和12核的CPU。且,文件還沒法手動切割任務分節點執行。
- Hive到KUDU的數據慢:insert into xxx select * 這個【*】一定要註意,如果讀取所有列,那列式查詢的優勢就沒多少了,所以,轉ORC多此一舉。
- Impala讀取HIVE數據時,記憶體消耗大!
唯一的好處: 降低硬碟資源的消耗(74M文件寫到HDFS,壓縮後只有15M),但是!!!這有何用?我要的是導入速度!如果只是為了壓縮,應該Load進Hive,然後啟用Hive的Insert到ORC新表,充分利用集群資源!
代碼如下
//1. 數據載入到textfile表中
load data inpath '/home/data/event-19-201906.txt' into table event_hive_3normal;
//2. 數據查詢出來寫入到ORC表中。
insert into event_hive_3orc
select * from event_hive_3normal實驗失敗~
優化思路:1.充分使用集群的CPU資源
2.避免大批量數據查詢寫入
優化方案:掏出我的老家伙,單Flume讀取本地數據文件sink到Kafka, 集群中多Flume消費KAFKA集群,sink到Kudu !下午見!


