
一.什麼是kafkakafka的目標是實現一個為處理實時數據提供一個統一、高吞吐、低延遲的平臺。是分散式發佈-訂閱消息系統,是一個分散式的,可劃分的,冗餘備份的持久性的日誌服務。Kafka使用場景:1 日誌收集:一個公司可以用Kafka可以收集各種服務的log,通過kafka以統一介面服務的方式開放 ...
一.什麼是kafka
kafka的目標是實現一個為處理實時數據提供一個統一、高吞吐、低延遲的平臺。是分散式發佈-訂閱消息系統,是一個分散式的,可劃分的,冗餘備份的持久性的日誌服務。
Kafka使用場景:
1 日誌收集:一個公司可以用Kafka可以收集各種服務的log,通過kafka以統一介面服務的方式開放給各種consumer,例如hadoop、Hbase、Solr等。
2 消息系統:解耦和生產者和消費者、緩存消息等。
3 用戶活動跟蹤:Kafka經常被用來記錄web用戶或者app用戶的各種活動,如瀏覽網頁、搜索、點擊等活動,這些活動信息被各個伺服器發佈到kafka的topic中,然後訂閱者通過訂閱這些topic來做實時的監控分析,或者裝載到hadoop、數據倉庫中做離線分析和挖掘。
4 運營指標:Kafka也經常用來記錄運營監控數據。包括收集各種分散式應用的數據,生產各種操作的集中反饋,比如報警和報告。
5 流式處理:比如spark streaming和storm
Kafka拓撲與流程:
二.Kafka組件
1.主題(topic)
Kafka將一組消息歸納為一個主題(topic),一個主題就是對消息的一個分類。生產者將消息發送到特定的主題,消費者訂閱主題或主題的某些分區進行消費。
2.消息
Kafka通信基本單位,由一個固定長度的消息頭和一個可變長度的消息體構成。
3.分區與副本
Kafka可以將主題劃分為多個分區(Partition),會根據分區規則選擇把消息存儲到哪個分區中,只要如果分區規則設置的合理,那麼所有的消息將會被均勻的分佈到不同的分區中,這樣就實現了負載均衡和水平擴展。另外,多個訂閱者可以從一個或者多個分區中同時消費數據,以支撐海量數據處理能力
Kafka的設計也是源自生活,好比是為公路運輸,不同的起始點和目的地需要修不同高速公路(主題),高速公路上可以提供多條車道(分區),流量大的公路多修幾條車道保證暢通,流量小的公路少修幾條車道避免浪費。收費站好比消費者,車多的時候多開幾個一起收費避免堵在路上,車少的時候開幾個讓汽車並道就好了
分區數可以大於節點數,但是副本數不能大於節點數量。創建主題是分區數量最好為代理數量的整數倍。
每分區有一個或多個副本(replica),從存儲角度上分析,每個副本在邏輯上抽象為一個日誌(log)對象,即分區的副本與日誌對象是一一對應的,Kafka會給每個分區找一個節點當帶頭大哥(Leader),以及若幹個節點當隨從(Follower)。消息寫入分區時,帶頭大哥除了自己複製一份外還會複製到多個隨從。如果隨從掛了,Kafka會再找一個隨從從帶頭大哥那裡同步歷史消息。
Kafka保證一個分區內消息是有序的,不能保證跨分區消息有序性,每條消息被追加到相應的分區,是順序寫磁碟,因此效率很高。
segment對應一個文件(實現上對應2個文件,一個數據文件,一個索引文件),一個partition對應一個文件夾,一個partition里理論上可以包含任意多個segment。
4.偏移量(offset)
kafka作為一個消息隊列,每次讀取消息時,需要指定從哪裡讀取,否則就會從預設位置讀取。
那麼為什麼不將位置偏移量儲存在kafka中呢?原因是,如果在位置偏移量記錄在kafka, 當kafka組件故障重啟時,就無法獲取位置偏移量。zookeeper作為常用組件管理工具,成為記錄kafka位置偏移量推薦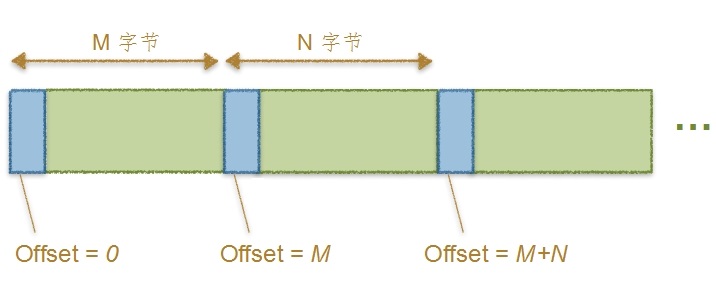
從上圖可以看出,每條消息存在磁碟的偏移量是其距離文件開頭的絕對偏移量。比如上面第一條消息的偏移量是0;第二條消息的偏移量是第一條消息的總長度;第三條消息是其前兩條消息總長度;以此類推。這種方式存儲消息的偏移量很好理解,處理起來也很方便。
需要註意,消息存儲到磁碟的偏移量是由 Broker 處理完成的,原因很簡單,因為只有 Broker 端才知道現在 Log 的最新偏移量; Producer 端是無法獲取的
5.代理(broker)
Kafka節點,一個Kafka節點就是一個broker,多個broker可以組成一個Kafka集群。
1 Broker沒有副本機制,一旦broker宕機,該broker的消息將都不可用。
2 Broker不保存訂閱者的狀態,由訂閱者自己保存。
3 無狀態導致消息的刪除成為難題(可能刪除的消息正在被訂閱),Kafka採用基於時間的SLA(服務保證),消息保存一定時間(通常7天)後會刪除。
4消費訂閱者可以rewind back(回捲)到任意位置重新進行消費,當訂閱者故障時,可以選擇最小的offset(id)進行重新讀取消費消息
6.生產者(producer)
生產者負責將消息發送給代理,也就是向kafka代理髮送消息的客戶端。
7.消費者(comsumer)和消費組
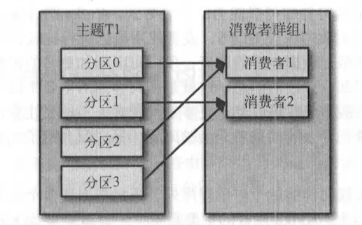
假設我們有一個應用程式需要從-個 Kafka主題讀取消息並驗證這些消息,然後再把它們 保存起來。應用程式需要創建一個消費者對象,訂閱主題並開始接收消息,然後驗證消息 井保存結果。過了 一陣子,生產者往主題寫入消息的速度超過了應用程式驗證數據的速度,這個時候該怎麼辦?如果只使用單個消費者處理消息,應用程式會遠跟不上消息生成的速度。顯然,此時很有必要對消費者進行橫向伸縮。就像多個生產者可以向相同的 主題 寫入消息一樣,我們也可以使用多個消費者從同一個主題讀取消息,對消息進行分流。
Kafka 消費者從屬於消費者群組。一個群組裡的消費者訂閱的是同一個主題,每個消費者 接收主題一部分分區的消息。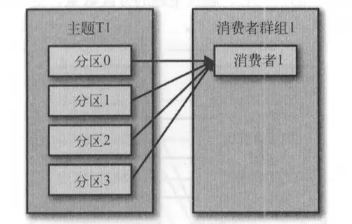
8.ISR
kafka同步機制
同步複製:只有所有的follower把數據拿過去後才commit,一致性好,可用性不高。
非同步複製:只要leader拿到數據立即commit,等follower慢慢去複製,可用性高,立即返回,一致性差一些。
不是完全同步:是一種ISR機制:
1. leader會維護一個與其基本保持同步的Replica列表,該列表稱為ISR(in-sync Replica),每個Partition都會有一個ISR,而且是由leader動態維護
2. 如果一個flower比一個leader落後太多,或者超過一定時間未發起數據複製請求,則leader將其重ISR中移除
3. 當ISR中所有Replica都向Leader發送ACK時,leader才commit
把滯後的follower移除ISR主要是避免寫消息延遲。設置ISR主要是為了broker宕掉之後,重新選舉partition的leader從ISR列表中選擇。


