
問題: 在資料庫編程開發中,有時會遇到數據量比較大的情況,如果直接大批量進行添加數據、修改數據、刪除數據,就會是比較大的事務,事務日誌也比較大,耗時久的話會對正常操作造成一定的阻塞。雖不至於達到刪庫跑路的程度,但也嚴重影響了用戶體驗,老是卡巴死機的感覺。這時我們可以對這個大批量操作進行分小批事務操作 ...
問題:
在資料庫編程開發中,有時會遇到數據量比較大的情況,如果直接大批量進行添加數據、修改數據、刪除數據,就會是比較大的事務,事務日誌也比較大,耗時久的話會對正常操作造成一定的阻塞。雖不至於達到刪庫跑路的程度,但也嚴重影響了用戶體驗,老是卡巴死機的感覺。這時我們可以對這個大批量操作進行分小批事務操作處理,使每批時間比較短,減少阻塞。大而化小,小而化了。舉個例子:如果大批事務需要跑5分鐘,那就阻塞了5分鐘;如果分成10個小批,每小批0.5分鐘,那就降低了長時間阻塞的幾率,提高了用戶體驗。
把目光放寬廣一點,其實不只是在資料庫編程,有時候我們也需要在其他編程語言中,實現分批處理的邏輯,例如使用C#對大批量Excel數據進行處理。
對於如何求批次這個問題,我們當然是希望有統一的計算公式,不管是什麼編程語言都通用的,而不是換種編程語言,就得根據不同編程語言的語法重新實現這個演算法。以達到快速開發目的,一次寫的表達式,去到哪裡都能通用。
而求批次(或求分頁數)這個問題有點像初中代數的求解:
已知總數據量a,每批(或每頁)數據量為b,求所需批次(或所需總頁數)x?
假設a為388888,b為10000。
解決方案:
方法1(不推薦):
如果是資料庫編程,可能大部分人的思維習慣就是:
先用a / b得出除得盡部分,例如這裡是38;
然後再用case when去判斷a % b除不盡部分也就是餘數是否為0,如果不為0,則批次加1,例如這裡是8888,雖然不夠10000,但是也不在38個批次之內,需要在第39批次。
使用T-SQL實現:@a / @b + case when @a % @b > 0 then 1 else 0 end
缺點:
- 很明顯這樣的表達式比較長,不是很簡潔。
- 而且如果改用C#實現,可是不支持case when的,得重新修改表達式實現功能。
方法2(推薦):
可以直接根據四則運算,表達式為(@a + @b - 1) / @b
這個表達式,是博主自己想到的方法,解釋如下:
由於序號是從1開始,第1批是從1到10000,而不是從0到9999,所以這裡@a - 1,就是為了從編程習慣的角度由序號0開始;
而 + @b則是因為,0到9999中任意一個數字,除以每批數據量10000的話,都是 < 1,但實際是當1批了,需要加回。
優點:
- 單純使用四則運算,無需case when等條件判斷,代碼簡潔。
- 方便代碼移植到C#等其他語言,只需要把參數改成相應C#變數之類,無需把case when改成C#能支持的if之類條件判斷。
方法3(推薦):
可以直接根據四則運算,表達式為(@a - 1) / @b + 1
這個表達式,也是博主自己想到的方法,解釋如下:
由於序號是從1開始,第1批是從1到10000,而不是從0到9999,所以這裡@a - 1,就是為了從編程習慣的角度由序號0開始;
而 + 1則是因為,0到9999中任意一個數字,除以每批數據量10000的話,都是 < 1,但實際是當1批了,需要加回。
優點:
- 單純使用四則運算,無需case when等條件判斷,代碼簡潔。
- 方便代碼移植到C#等其他語言,只需要把參數改成相應C#變數之類,無需把case when改成C#能支持的if之類條件判斷。
方法2和方法3,從代數的角度看,關係式是等價的:
方法2關係式去掉括弧後是:@a / @b + 1 - 1 / @b
方法3關係式去掉括弧後是:@a / @b - 1 / @b + 1
腳本:
/* 問題:已知總數據量a,每批數據量為b,求所需批次x?假設a為388888,b為10000。 腳本來源:https://www.cnblogs.com/zhang502219048/p/11108723.html */ declare @a int = 388888, @b int = 10000, @x1 int, @x2 int, @x3 int --方法1(不推薦):除了四則運算外,還有取模運算,而case when條件判斷更是使腳本變得長而複雜,也不利於移植到其他編程語言 select @x1 = @a / @b + case when @a % @b > 0 then 1 else 0 end --方法2(推薦):只使用四則運算就實現 select @x2 = (@a + @b - 1) / @b --方法3(推薦):只使用四則運算就實現 select @x3 = (@a - 1) / @b + 1 --查看計算結果 select @x1 as x1, @x2 as x2, @x3 as x3
在博主的上一篇技術博文《sql server使用公用表表達式CTE通過遞歸方式編寫通用函數自動生成連續數字和日期》,說明瞭怎麼批量生成連續數字,我們就直接生成10W數據量來驗證一下本篇博文《sql server編寫簡潔四則運算表達式腳本實現計算批次功能(C#等其它編程語言也能直接用此通用表達式)》所述的計算批次表達式是否正確。
問題擴展到:
已知總數據量a,每批數據量為b,求每條數據所屬批次x?假設a為100000,b為1000。
驗證腳本:
/* 問題:已知總數據量a,每批數據量為b,求每條數據所屬批次x?假設a為100000,b為1000。 作者:zhang502219048 腳本來源:https://www.cnblogs.com/zhang502219048/p/11108723.html 腳本基於:https://www.cnblogs.com/zhang502219048/p/11108991.html */ declare @a int = 100000, @b int = 1000 select vid --方法1(不推薦):除了四則運算外,還有取模運算,而case when條件判斷更是使腳本變得長而複雜,也不利於移植到其他編程語言 , x1 = vid / @b + case when vid % @b > 0 then 1 else 0 end --方法2(推薦):只使用四則運算就實現 , x2 = (vid + @b - 1) / @b --方法3(推薦):只使用四則運算就實現 , x3 = (vid - 1) / @b + 1 into #t from fun_ConcatStringsToTable(1,@a) --查看所有數據和所屬批次 select * from #t --檢查批次計算結果是否一致 select distinct case when x1 = x2 and x2 = x3 then 'Right!' else 'Wrong!' end as Result from #t drop table #t
驗證腳本運行結果: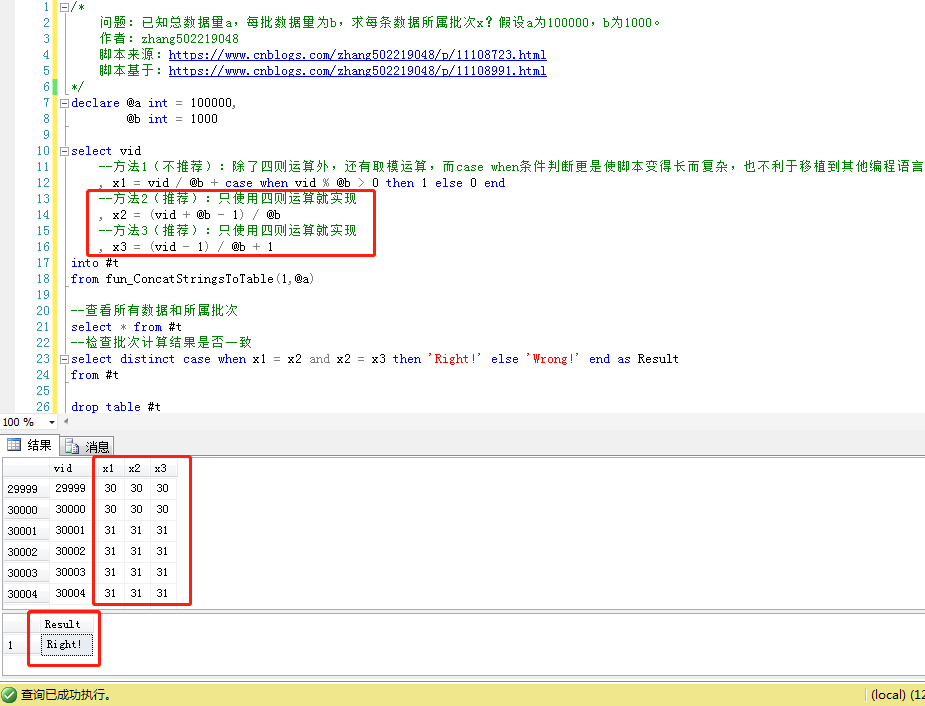
總結:
博主對於計算批次的新思路就介紹到這裡,大家如果覺得有用的話可以直接拿來用,是不是覺得很方便呢?感覺為批次計算的演算法註入了新的思想,標新立異。
【轉載請註明博文來源:https://www.cnblogs.com/zhang502219048/p/11108723.html】


