
ChannelPipeline貫穿io事件處理的大動脈 上一篇,我們分析了NioEventLoop及其相關類的主幹邏輯代碼,我們知道netty採用線程封閉的方式來避免多線程之間的資源競爭,最大限度地減少併發問題,減少鎖的使用,因而能夠有效減低線程切換的開銷,減少cpu的使用時間。此外,我們還簡單分析 ...
ChannelPipeline貫穿io事件處理的大動脈
上一篇,我們分析了NioEventLoop及其相關類的主幹邏輯代碼,我們知道netty採用線程封閉的方式來避免多線程之間的資源競爭,最大限度地減少併發問題,減少鎖的使用,因而能夠有效減低線程切換的開銷,減少cpu的使用時間。此外,我們還簡單分析了netty對於線程組的封裝EventLoopGroup,目前一般採用roundRobin的方式在多個線程上均勻地分配channel。通過前面幾篇文章的分析,我們已經對channel的初始化,註冊到EventLoop上,SingleThreadEventLoop的線程啟動過程以及線程中運行的代碼邏輯有了一些瞭解,此外我們也分析了用於處理基於TCP協議的io事件的NioEventLoop類的具體的迴圈邏輯,通過對代碼的詳細分析,我們瞭解了對於connect,write,read,accept事件的不同處理邏輯,但是對於write和read事件的處理邏輯我們並沒有分析的很詳細,因為這些事件的處理涉及到netty中另一個很重要的模塊,ChannelPipeline以及一系列相關的類如Channel, ChannelHandler, ChannelhandlerContext等的理解,netty中的事件處理採用了經典的責任鏈(responsbility chain)的的設計模式,這種設計模式使得netty的io事件處理框架易於擴展,並且為業務邏輯提供了一個很好的抽象模型,大大降低了netty的使用難度,使得io事件的處理變得更符合思維習慣。
好了,廢話了那麼多,其實主要是想把前面分析的幾篇的文章做一個小結和回顧,然後引出本篇的主題--netty的io事件處理鏈模式。
因為netty的代碼結構相對來說還是很規整,它的模塊之間的邊界劃分比較明確,EventLoop作為io事件的“發源地”,與其交互的對象是Channel類,而ChannelPipeline,ChannelhandlerContext, ChannelHandler等幾個類則是與Channel交互,他們並不直接與EventLoop交互。
ChannelPipeline的結構圖
首先每一個Channel在初始化的時候就會創建一個ChannelPipeline,這點我們在前面分析NioSocketChannel的初始化時也分析到了。目前ChannelPipeline的實現只有DefaultChannelPipeline一種,所以我們也以DefaultChannelPipeline來分析。DefaultChannelPipeline內部有一個雙向鏈表結構,這個鏈表的每個節點都是一個AbstractChannelHandlerContext類型的節點,DefaultChannelPipeline剛初始化時就會創建兩個初始節點,分別是HeadContext和TailContext,這兩個節點也並不完全是標記節點,他們都有各自實際的作用,
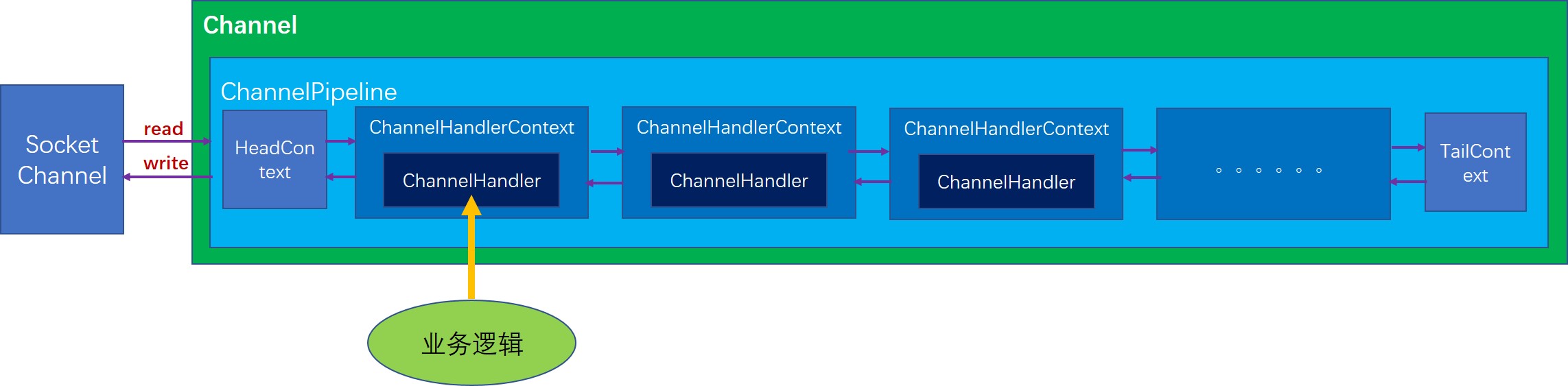
- HeadContext,實現了bind,connect,disconnect,close,write,flush等等幾個方法,基本都是通過直接調用unsafe的相關方法實現的。而對於其他的方法基本都是通過調用AbstractChannelHandlerContext的fire方法將事件傳給下一個節點。
- TailContext, 主要用於處理寫數據幾乎沒有實現任何邏輯,它的功能幾乎全部繼承自AbstractChannelHandlerContext,而AbstractChannelHandlerContext對於大部分事件處理的實現都是簡單地將事件向下一個節點傳遞。註意,這裡下一個節點不一定是前一個還是後一個,要根據具體事件類型或者具體的操作而定,對於ChannelOutboundInvoker介面中的方法都是從尾節點向首節點傳遞事件,而對於ChannelInboundInvoker介面中的方法都是從首節點往尾節點傳遞。我們可以形象地理解為,首節點是最靠近socket的,而尾節點是最原理socket的,所以有數據進來時,產生的讀事件最先從首節點開始向後傳遞,當有寫數據的動作時,則會從尾節點向頭結點傳遞。
下麵,我們以兩個最重要的事件讀事件和寫事件,來分析netty的這種鏈式處理結構到底是怎麼運轉的。
讀事件
首先,我們需要找到一個產生讀事件並調用相關方法使得讀事件開始傳遞的例子,很自然我們應該想到在EventLoop中會產生讀事件。
如下,就是NioEventLoop中對於讀事件的處理,通過調用NioUnsafe.read方法
// 處理read和accept事件
if ((readyOps & (SelectionKey.OP_READ | SelectionKey.OP_ACCEPT)) != 0 || readyOps == 0) {
unsafe.read();
}我們繼續看NioByteUnsafe.read方法,這個方法我們之前在分析NioEventLoop事件處理邏輯時提到過,這個方法首先會通過緩衝分配器分配一個緩衝,然後從channel(也就是socket)中將數據讀到緩衝中,每讀一個緩衝,就會觸發一個讀事件,我們看具體的觸發讀事件的調用:
do {
// 分配一個緩衝
byteBuf = allocHandle.allocate(allocator);
// 將通道的數據讀取到緩衝中
allocHandle.lastBytesRead(doReadBytes(byteBuf));
// 如果沒有讀取到數據,說明通道中沒有待讀取的數據了,
if (allocHandle.lastBytesRead() <= 0) {
// nothing was read. release the buffer.
// 因為沒讀取到數據,所以應該釋放緩衝
byteBuf.release();
byteBuf = null;
// 如果讀取到的數據量是負數,說明通道已經關閉了
close = allocHandle.lastBytesRead() < 0;
if (close) {
// There is nothing left to read as we received an EOF.
readPending = false;
}
break;
}
// 更新Handle內部的簿記量
allocHandle.incMessagesRead(1);
readPending = false;
// 向channel的處理器流水線中觸發一個事件,
// 讓取到的數據能夠被流水線上的各個ChannelHandler處理
pipeline.fireChannelRead(byteBuf);
byteBuf = null;
// 這裡根據如下條件判斷是否繼續讀:
// 上一次讀取到的數據量大於0,並且讀取到的數據量等於分配的緩衝的最大容量,
// 此時說明通道中還有待讀取的數據
} while (allocHandle.continueReading());為了代碼邏輯的完整性,我這裡把整個迴圈的代碼都貼上來,其實我們要關註的僅僅是pipeline.fireChannelRead(byteBuf)這一句,好了,現在我們找到ChannelPipeline觸發讀事件的入口方法,我們順著這個方法,順藤摸瓜就能一步步理清事件的傳遞過程了。
DefaultChannelPipeline.fireChannelRead
如果我們看一下ChannelPipeline介面,這裡面的方法名都是以fire開頭的,實際就是想表達這些方法都是觸發了一個事件,然後這個事件就會在內部的處理器鏈表中傳遞。
我們看到這裡調用了一個靜態方法,並且以頭結點為參數,也就是說事件傳遞是從頭結點開始的。
public final ChannelPipeline fireChannelRead(Object msg) {
AbstractChannelHandlerContext.invokeChannelRead(head, msg);
return this;
}AbstractChannelHandlerContext.invokeChannelRead(final AbstractChannelHandlerContext next, Object msg)
可以看到,這個方法中通過調用invokeChannelRead執行處理邏輯
static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) {
// 維護引用計數,主要是為了偵測資源泄漏問題
final Object m = next.pipeline.touch(ObjectUtil.checkNotNull(msg, "msg"), next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
// 調用invokeChannelRead執行處理邏輯
next.invokeChannelRead(m);
} else {
executor.execute(new Runnable() {
@Override
public void run() {
next.invokeChannelRead(m);
}
});
}
}AbstractChannelHandlerContext.invokeChannelRead(Object msg)
這裡可以看到,AbstractChannelHandlerContext通過自己內部的handler對象來實現讀數據的邏輯。這也體現了ChannelHandlerContext在整個結構中的作用,其實它是起到了在ChannelPipeline和handler之間的一個中間人的角色,那我們要問:既然ChannelHandlerContext不起什麼實質性的作用,那為什麼要多這一個中間層呢,這樣設計的好處是什麼?我認為這樣設計其實是為了盡最大可能對使用者屏蔽netty框架的細節,試想如果沒有這個context的中間角色,使用者必然要詳細地瞭解ChannelPipeline,並且還要考慮事件傳遞是找下一個節點,還要考慮下一個節點應該沿著鏈表的正序找還是沿著鏈表 倒敘找,所以這裡ChannelHandlerContext的角色我認為最大的作用就是封裝了鏈表的邏輯,並且封裝了不同類型操作的傳播方式。當然也起到了一些引用傳遞的作用,如channel引用可以簡介地傳遞給用戶。
好了,回到正題,從前面的方法中我們知道讀事件最先是從HeadContext節點開始的,所以我們看一下HeadContext的channelRead方法(因為HeadContext也實現了handler方法,並且返回的就是自身)
private void invokeChannelRead(Object msg) {
// 如果這個handler已經準備就緒,那麼就執行處理邏輯
// 否則將事件傳遞給下一個處理器節點
if (invokeHandler()) {
try {
// 調用內部的handler的channelRead方法
((ChannelInboundHandler) handler()).channelRead(this, msg);
} catch (Throwable t) {
notifyHandlerException(t);
}
} else {
fireChannelRead(msg);
}
}HeadContext.channelRead
這裡的調用也是一個重要的註意點,這裡調用了ChannelHandlerContext.fireChannelRead方法,這正是事件傳播的方法,fire開頭的方法的作用就是將當前的操作(或者叫事件)從當前處理節點傳遞給下一個處理節點。這樣就實現了事件在鏈表中的傳播。
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ctx.fireChannelRead(msg);
}小結
到這裡我們先暫停一下,總結一下讀事件(或者是讀操作)在ChannelPipeline內部的傳播機制,其實很簡單,
- 首先外部調用者會通過unsafe最終調用ChannelPipeline.fireChannelRead方法,並將從channel中讀取到的數據作為參數傳進來
- 以頭結點作為參數調用靜態方法AbstractChannelHandlerContext.fireChannelRead
- 然後頭結點HeadContext開始調用節點的invokeChannelRead方法(即ChannelHandlerContext的invokeChannelRead方法),
- invokeChannelRead方法會調用當前節點的handler對象的channelRead方法執行處理邏輯
- handler對象的channelRead方法中可以調用AbstractChannelHandlerContext.fireChannelRead將這個事件傳遞到下一個節點
- 這樣事件就能夠沿著鏈條不斷傳遞下去,當然如果業務處理需要,完全可以在某個節點將事件的傳遞終止,也就是在這個節點不調用ChannelHandlerContext.fireChannelRead
寫事件
此外,我們分析一下寫數據的操作是怎麼傳播的。分析寫數據操作的入口並不想讀事件那麼好找,在netty中用戶的代碼中寫數據最終都是被放到內部的緩衝中,當NioEventLoop中監聽到底層的socket可以寫數據的事件時,實際上是吧當前緩衝中的數據發送到socket中,而對於用戶來講,是接觸不到socketChannel這一層的。
根據前面的分析,我們知道,用戶一般都會與Channel,ChannelHandler, ChannelhandlerContext這幾種類打交道,寫數據的操作也是通過Channel的write和writeAndFlush觸發的,這兩個方法區別在於writeAndFlush在寫完數據後還會觸發一次刷寫操作,將緩衝中的數據實際寫入到socket中。
AbstractChannel.write
仍然是將操作交給內部的ChannelPipeline,觸發流水線操作
public ChannelFuture write(Object msg, ChannelPromise promise) {
return pipeline.write(msg, promise);
}DefaultChannelPipeline.write
這裡可以很清楚地看出來,寫數據的操作從為節點開始,但是TailContext並未重寫write方法,所以最終調用的還是AbstractChannelHandlerContext中的相應方法。
我們沿著調用鏈往下走,發現write系列的方法其實是將寫操作傳遞給了下一個ChannelOutboundHandler類型的處理節點,註意這裡是從尾節點向前找,遍歷鏈表的順序和讀數據正好相反。
真正調用
public final ChannelFuture write(Object msg, ChannelPromise promise) {
return tail.write(msg, promise);
}AbstractChannelHandlerContext.write
從這個方法可以明顯地看出來,write方法將寫操作交給了下一個ChannelOutboundHandler類型的處理器節點。
private void write(Object msg, boolean flush, ChannelPromise promise) {
ObjectUtil.checkNotNull(msg, "msg");
try {
if (isNotValidPromise(promise, true)) {
ReferenceCountUtil.release(msg);
// cancelled
return;
}
} catch (RuntimeException e) {
ReferenceCountUtil.release(msg);
throw e;
}
// 沿著鏈表向前遍歷,找到下一個ChannelOutboundHandler類型的處理器節點
final AbstractChannelHandlerContext next = findContextOutbound(flush ?
(MASK_WRITE | MASK_FLUSH) : MASK_WRITE);
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
if (flush) {
// 調用AbstractChannelHandlerContext.invokeWriteAndFlush方法執行真正的寫入邏輯
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {
// 如果當前是非同步地寫入數據,那麼需要將寫入的邏輯封裝成一個任務添加到EventLoop的任務對隊列中
final AbstractWriteTask task;
if (flush) {
task = WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = WriteTask.newInstance(next, m, promise);
}
if (!safeExecute(executor, task, promise, m)) {
// We failed to submit the AbstractWriteTask. We need to cancel it so we decrement the pending bytes
// and put it back in the Recycler for re-use later.
//
// See https://github.com/netty/netty/issues/8343.
task.cancel();
}
}
}AbstractChannelHandlerContext.invokeWrite
我們接著看invokeWrite0方法
private void invokeWrite(Object msg, ChannelPromise promise) {
if (invokeHandler()) {
invokeWrite0(msg, promise);
} else {
write(msg, promise);
}
}AbstractChannelHandlerContext.invokeWrite0
這裡可以清楚地看到,最終是調用了handler的write方法執行真正的寫入邏輯,這個邏輯實際上就是有用戶自己實現的。
private void invokeWrite0(Object msg, ChannelPromise promise) {
try {
// 調用當前節點的handler的write方法執行真正的寫入邏輯
((ChannelOutboundHandler) handler()).write(this, msg, promise);
} catch (Throwable t) {
notifyOutboundHandlerException(t, promise);
}
}到這裡,我們已經知道寫入的操作是怎麼從尾節點開始,也知道了通過調用當前處理節點的AbstractChannelHandlerContext.write方法可以將寫入操作傳遞給下一個節點,那麼數據經過層層傳遞後,最終是怎麼寫到socket中的呢?回答這個問題,我們需要看一下HeadContext的代碼!我們知道寫入的操作是從尾節點向前傳遞的,那麼頭節點HeadContext就是傳遞的最後一個節點。
HeadContext.write
最終調用了unsafe.write方法。
在AbstractChannel.AbstractUnsafe的實現中,write方法將經過前面一系列處理器處理過的數據存放到內部的緩衝中。
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) {
unsafe.write(msg, promise);
}刷寫操作的傳遞
前面我們提到,寫數據的操作除了write還有writeAndFlush,這個操作除了寫數據,還會緊接著執行一次刷寫操作。刷寫操作也會從尾節點向前傳遞,最終傳遞到頭結點HeadContext,其中的flush方法如下:
public void flush(ChannelHandlerContext ctx) {
unsafe.flush();
}在AbstractChannel.AbstractUnsafe的實現中,flush操作會將前面存儲在內部緩衝區中的數據吸入到socket中,從而完成刷寫。
總結
本節,我們主要通過io事件處理中最重要的兩種事件,即讀事件和寫事件為切入點 詳細分析了netty中對於這兩種事件的處理方法。其中寫數據的事件與我們之前在jdk nio中建立起的印象差別還是不大的,都是對從socket中讀取的數據進行處理,但是寫事件跟jdk nio中的概念就有較大差別了,因為netty對數據的寫入做了很大的改變和優化,用戶代碼中通過channel調用相關的寫數據的方法,這個方法會觸發處理器鏈條上的所有相關的處理器對待寫入的數據進行加工,最後在頭結點HeadCOntext中被寫入channel內部的緩衝區,通過flush操作將緩衝的數據寫入socket中。
這裡面最重要的也是最值得我們學習的一點就是責任鏈模式,顯然,這又是一次對責任鏈模式的成功運用,是的框架的擴展性大大增強,而且面向用戶的介面更加容易理解,簡單易用,向用戶屏蔽了大部分框架實現細節。


