
一、高可用簡介 二、集群規劃 三、前置條件 四、集群配置 五、啟動集群 六、查看集群 七、集群的二次啟動 一、高可用簡介 Hadoop 高可用 (High Availability) 分為 HDFS 高可用和 YARN 高可用,兩者的實現基本類似,但 HDFS NameNode 對數據存儲及其一致性 ...
一、高可用簡介
Hadoop 高可用 (High Availability) 分為 HDFS 高可用和 YARN 高可用,兩者的實現基本類似,但 HDFS NameNode 對數據存儲及其一致性的要求比 YARN ResourceManger 高得多,所以它的實現也更加複雜,故下麵先進行講解:
1.1 高可用整體架構
HDFS 高可用架構如下:

圖片引用自:https://www.edureka.co/blog/how-to-set-up-hadoop-cluster-with-hdfs-high-availability/
HDFS 高可用架構主要由以下組件所構成:
- Active NameNode 和 Standby NameNode:兩台 NameNode 形成互備,一臺處於 Active 狀態,為主 NameNode,另外一臺處於 Standby 狀態,為備 NameNode,只有主 NameNode 才能對外提供讀寫服務。
- 主備切換控制器 ZKFailoverController:ZKFailoverController 作為獨立的進程運行,對 NameNode 的主備切換進行總體控制。ZKFailoverController 能及時檢測到 NameNode 的健康狀況,在主 NameNode 故障時藉助 Zookeeper 實現自動的主備選舉和切換,當然 NameNode 目前也支持不依賴於 Zookeeper 的手動主備切換。
- Zookeeper 集群:為主備切換控制器提供主備選舉支持。
- 共用存儲系統:共用存儲系統是實現 NameNode 的高可用最為關鍵的部分,共用存儲系統保存了 NameNode 在運行過程中所產生的 HDFS 的元數據。主 NameNode 和 NameNode 通過共用存儲系統實現元數據同步。在進行主備切換的時候,新的主 NameNode 在確認元數據完全同步之後才能繼續對外提供服務。
- DataNode 節點:除了通過共用存儲系統共用 HDFS 的元數據信息之外,主 NameNode 和備 NameNode 還需要共用 HDFS 的數據塊和 DataNode 之間的映射關係。DataNode 會同時向主 NameNode 和備 NameNode 上報數據塊的位置信息。
1.2 基於 QJM 的共用存儲系統的數據同步機制分析
目前 Hadoop 支持使用 Quorum Journal Manager (QJM) 或 Network File System (NFS) 作為共用的存儲系統,這裡以 QJM 集群為例進行說明:Active NameNode 首先把 EditLog 提交到 JournalNode 集群,然後 Standby NameNode 再從 JournalNode 集群定時同步 EditLog,當 Active NameNode 宕機後, Standby NameNode 在確認元數據完全同步之後就可以對外提供服務。
需要說明的是向 JournalNode 集群寫入 EditLog 是遵循 “過半寫入則成功” 的策略,所以你至少要有3個 JournalNode 節點,當然你也可以繼續增加節點數量,但是應該保證節點總數是奇數。同時如果有 2N+1 台 JournalNode,那麼根據過半寫的原則,最多可以容忍有 N 台 JournalNode 節點掛掉。

1.3 NameNode 主備切換
NameNode 實現主備切換的流程下圖所示:

HealthMonitor 初始化完成之後會啟動內部的線程來定時調用對應 NameNode 的 HAServiceProtocol RPC 介面的方法,對 NameNode 的健康狀態進行檢測。
HealthMonitor 如果檢測到 NameNode 的健康狀態發生變化,會回調 ZKFailoverController 註冊的相應方法進行處理。
如果 ZKFailoverController 判斷需要進行主備切換,會首先使用 ActiveStandbyElector 來進行自動的主備選舉。
ActiveStandbyElector 與 Zookeeper 進行交互完成自動的主備選舉。
ActiveStandbyElector 在主備選舉完成後,會回調 ZKFailoverController 的相應方法來通知當前的 NameNode 成為主 NameNode 或備 NameNode。
ZKFailoverController 調用對應 NameNode 的 HAServiceProtocol RPC 介面的方法將 NameNode 轉換為 Active 狀態或 Standby 狀態。
1.4 YARN高可用
YARN ResourceManager 的高可用與 HDFS NameNode 的高可用類似,但是 ResourceManager 不像 NameNode ,沒有那麼多的元數據信息需要維護,所以它的狀態信息可以直接寫到 Zookeeper 上,並依賴 Zookeeper 來進行主備選舉。
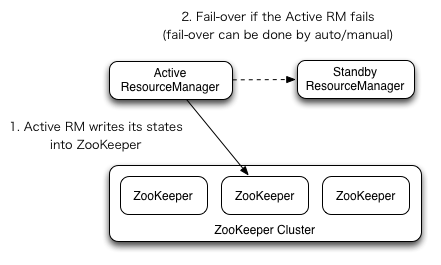
二、集群規劃
按照高可用的設計目標:需要保證至少有兩個 NameNode (一主一備) 和 兩個 ResourceManager (一主一備) ,同時為滿足“過半寫入則成功”的原則,需要至少要有3個 JournalNode 節點。這裡使用三台主機進行搭建,集群規劃如下:

三、前置條件
- 所有伺服器都安裝有JDK,安裝步驟可以參見:Linux下JDK的安裝;
- 搭建好ZooKeeper集群,搭建步驟可以參見:Zookeeper單機環境和集群環境搭建
- 所有伺服器之間都配置好SSH免密登錄。
四、集群配置
4.1 下載並解壓
下載Hadoop。這裡我下載的是CDH版本Hadoop,下載地址為:http://archive.cloudera.com/cdh5/cdh/5/
# tar -zvxf hadoop-2.6.0-cdh5.15.2.tar.gz 4.2 配置環境變數
編輯profile文件:
# vim /etc/profile增加如下配置:
export HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2
export PATH=${HADOOP_HOME}/bin:$PATH執行source命令,使得配置立即生效:
# source /etc/profile4.3 修改配置
進入${HADOOP_HOME}/etc/hadoop目錄下,修改配置文件。各個配置文件內容如下:
1. hadoop-env.sh
# 指定JDK的安裝位置
export JAVA_HOME=/usr/java/jdk1.8.0_201/2. core-site.xml
<configuration>
<property>
<!-- 指定namenode的hdfs協議文件系統的通信地址 -->
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<!-- 指定hadoop集群存儲臨時文件的目錄 -->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<property>
<!-- ZooKeeper集群的地址 -->
<name>ha.zookeeper.quorum</name>
<value>hadoop001:2181,hadoop002:2181,hadoop002:2181</value>
</property>
<property>
<!-- ZKFC連接到ZooKeeper超時時長 -->
<name>ha.zookeeper.session-timeout.ms</name>
<value>10000</value>
</property>
</configuration>3. hdfs-site.xml
<configuration>
<property>
<!-- 指定HDFS副本的數量 -->
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<!-- namenode節點數據(即元數據)的存放位置,可以指定多個目錄實現容錯,多個目錄用逗號分隔 -->
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/namenode/data</value>
</property>
<property>
<!-- datanode節點數據(即數據塊)的存放位置 -->
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/datanode/data</value>
</property>
<property>
<!-- 集群服務的邏輯名稱 -->
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<!-- NameNode ID列表-->
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<!-- nn1的RPC通信地址 -->
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop001:8020</value>
</property>
<property>
<!-- nn2的RPC通信地址 -->
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop002:8020</value>
</property>
<property>
<!-- nn1的http通信地址 -->
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop001:50070</value>
</property>
<property>
<!-- nn2的http通信地址 -->
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop002:50070</value>
</property>
<property>
<!-- NameNode元數據在JournalNode上的共用存儲目錄 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop001:8485;hadoop002:8485;hadoop003:8485/mycluster</value>
</property>
<property>
<!-- Journal Edit Files的存儲目錄 -->
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/journalnode/data</value>
</property>
<property>
<!-- 配置隔離機制,確保在任何給定時間只有一個NameNode處於活動狀態 -->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<!-- 使用sshfence機制時需要ssh免密登錄 -->
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<!-- SSH超時時間 -->
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<!-- 訪問代理類,用於確定當前處於Active狀態的NameNode -->
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 開啟故障自動轉移 -->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>4. yarn-site.xml
<configuration>
<property>
<!--配置NodeManager上運行的附屬服務。需要配置成mapreduce_shuffle後才可以在Yarn上運行MapReduce程式。-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- 是否啟用日誌聚合(可選) -->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!-- 聚合日誌的保存時間(可選) -->
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<property>
<!-- 啟用RM HA -->
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<!-- RM集群標識 -->
<name>yarn.resourcemanager.cluster-id</name>
<value>my-yarn-cluster</value>
</property>
<property>
<!-- RM的邏輯ID列表 -->
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<!-- RM1的服務地址 -->
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop002</value>
</property>
<property>
<!-- RM2的服務地址 -->
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop003</value>
</property>
<property>
<!-- RM1 Web應用程式的地址 -->
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop002:8088</value>
</property>
<property>
<!-- RM2 Web應用程式的地址 -->
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop003:8088</value>
</property>
<property>
<!-- ZooKeeper集群的地址 -->
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop001:2181,hadoop002:2181,hadoop003:2181</value>
</property>
<property>
<!-- 啟用自動恢復 -->
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<!-- 用於進行持久化存儲的類 -->
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>5. mapred-site.xml
<configuration>
<property>
<!--指定mapreduce作業運行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>5. slaves
配置所有從屬節點的主機名或IP地址,每行一個。所有從屬節點上的DataNode服務和NodeManager服務都會被啟動。
hadoop001
hadoop002
hadoop0034.4 分發程式
將Hadoop安裝包分發到其他兩台伺服器,分發後建議在這兩台伺服器上也配置一下Hadoop的環境變數。
# 將安裝包分發到hadoop002
scp -r /usr/app/hadoop-2.6.0-cdh5.15.2/ hadoop002:/usr/app/
# 將安裝包分發到hadoop003
scp -r /usr/app/hadoop-2.6.0-cdh5.15.2/ hadoop003:/usr/app/五、啟動集群
5.1 啟動ZooKeeper
分別到三台伺服器上啟動ZooKeeper服務:
zkServer.sh start5.2 啟動Journalnode
分別到三台伺服器的的${HADOOP_HOME}/sbin目錄下,啟動journalnode進程:
hadoop-daemon.sh start journalnode5.3 初始化NameNode
在hadop001上執行NameNode初始化命令:
hdfs namenode -format執行初始化命令後,需要將NameNode元數據目錄的內容,複製到其他未格式化的NameNode上。元數據存儲目錄就是我們在hdfs-site.xml中使用dfs.namenode.name.dir屬性指定的目錄。這裡我們需要將其複製到hadoop002上:
scp -r /home/hadoop/namenode/data hadoop002:/home/hadoop/namenode/5.4 初始化HA狀態
在任意一臺NameNode上使用以下命令來初始化ZooKeeper中的HA狀態:
hdfs zkfc -formatZK5.5 啟動HDFS
進入到hadoop001的${HADOOP_HOME}/sbin目錄下,啟動HDFS。此時hadoop001和hadoop002上的NameNode服務,和三台伺服器上的DataNode服務都會被啟動:
start-dfs.sh5.6 啟動YARN
進入到hadoop002的${HADOOP_HOME}/sbin目錄下,啟動YARN。此時hadoop002上的ResourceManager服務,和三台伺服器上的NodeManager服務都會被啟動:
start-yarn.sh需要註意的是,這個時候hadoop003上的ResourceManager服務通常是沒有啟動的,需要手動啟動:
yarn-daemon.sh start resourcemanager六、查看集群
6.1 查看進程
成功啟動後,每台伺服器上的進程應該如下:
[root@hadoop001 sbin]# jps
4512 DFSZKFailoverController
3714 JournalNode
4114 NameNode
3668 QuorumPeerMain
5012 DataNode
4639 NodeManager
[root@hadoop002 sbin]# jps
4499 ResourceManager
4595 NodeManager
3465 QuorumPeerMain
3705 NameNode
3915 DFSZKFailoverController
5211 DataNode
3533 JournalNode
[root@hadoop003 sbin]# jps
3491 JournalNode
3942 NodeManager
4102 ResourceManager
4201 DataNode
3435 QuorumPeerMain
6.2 查看Web UI
HDFS和YARN的埠號分別為50070和8080,界面應該如下:
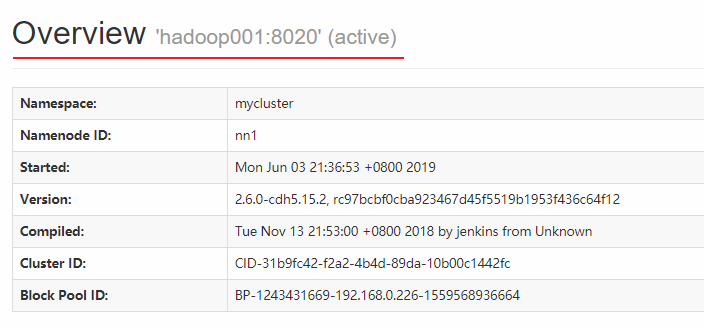
此時hadoop001上的NameNode處於可用狀態:
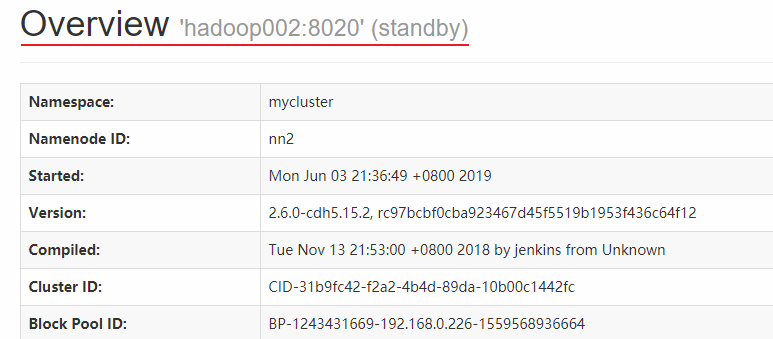
而hadoop002上的NameNode則處於備用狀態:
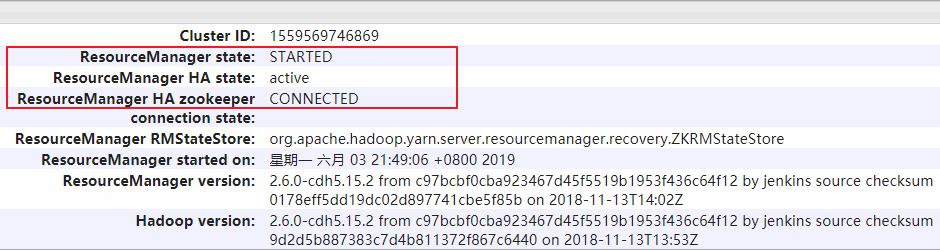
hadoop002上的ResourceManager處於可用狀態:
hadoop003上的ResourceManager則處於備用狀態:
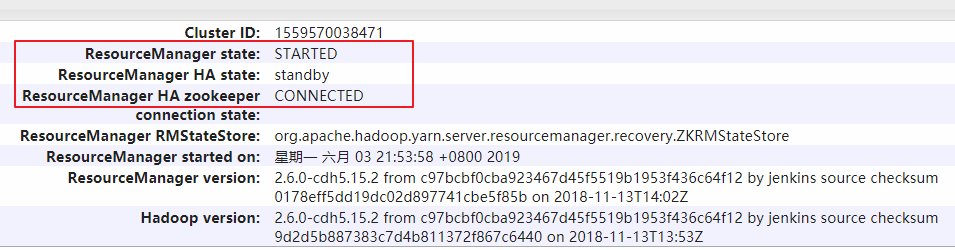
同時界面上也有Journal Manager的相關信息:
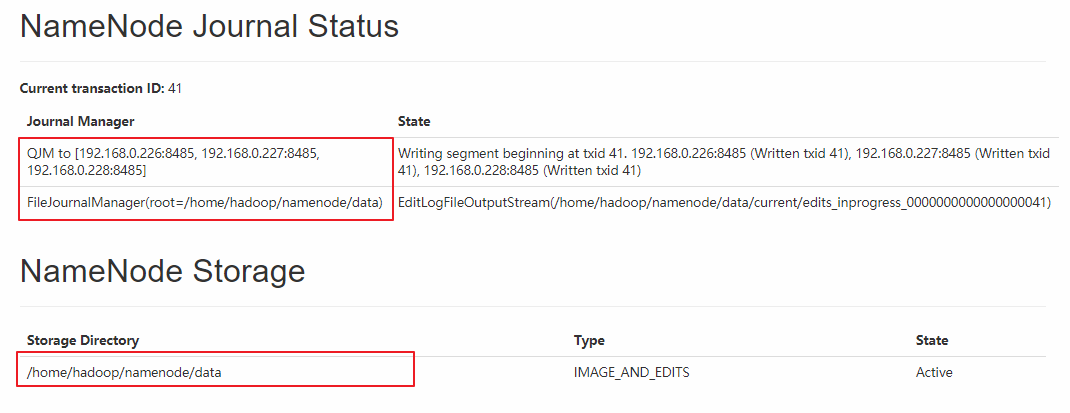
七、集群的二次啟動
上面的集群初次啟動涉及到一些必要初始化操作,所以過程略顯繁瑣。但是集群一旦搭建好後,想要再次啟用它是比較方便的,步驟如下(首選需要確保ZooKeeper集群已經啟動):
在hadoop001啟動 HDFS,此時會啟動所有與 HDFS 高可用相關的服務,包括 NameNode,DataNode 和 JournalNode:
start-dfs.sh在hadoop002啟動YARN:
start-yarn.sh這個時候hadoop003上的ResourceManager服務通常還是沒有啟動的,需要手動啟動:
yarn-daemon.sh start resourcemanager參考資料
以上搭建步驟主要參考自官方文檔:
關於Hadoop高可用原理的詳細分析,推薦閱讀:
Hadoop NameNode 高可用 (High Availability) 實現解析
更多大數據系列文章可以參見個人 GitHub 開源項目: 大數據入門指南

