
字典 字典又稱為符號表、關聯數組或映射(map),是一種用於保存鍵值對(key value)的數據結構。 那麼 C 語言中有沒有這樣 key value 型的內置數據結構呢? 答案:沒有。 說起鍵值對,是不是想到了 Java 中的 Map?Java中的 Map 實現有兩個:HashMap 和 Tre ...
字典
字典又稱為符號表、關聯數組或映射(map),是一種用於保存鍵值對(key-value)的數據結構。
那麼 C 語言中有沒有這樣 key-value 型的內置數據結構呢? 答案:沒有。
說起鍵值對,是不是想到了 Java 中的 Map?Java中的 Map 實現有兩個:HashMap 和 TreeMap。
HashMap的底層是 hash 表,TreeMap 的底層是二叉搜索樹,而 Redis 必須要求的一點就是效率,所以 Redis 中的字典使用的是 hash 表。
那麼下麵我們就拿 Redis 中的字典與 Java 中的 HashMap 對比一下
- Redis 定義的字典結構是什麼?Java 的呢?
- Java 和 Redis 的字元串結構有什麼區別?
Redis 中字典的數據結構是什麼?
Redis 中字典的底層使用的 hash 表,它的具體結構如下:
/*
* 字典
*
* 每個字典使用兩個哈希表,用於實現漸進式 rehash
*/
typedef struct dict {
// 特定於類型的處理函數
dictType *type;
// 類型處理函數的私有數據
void *privdata;
// 哈希表(2 個)
dictht ht[2];
// 記錄 rehash 進度的標誌,值為 -1 表示 rehash 未進行,否則表示 rehash 進行到了 ht[0] 具體索引上
int rehashidx;
} dict;
/*
* 哈希表
*/
typedef struct dictht {
// 哈希表節點指針數組(俗稱桶,bucket)
dictEntry **table;
// 指針數組的大小
unsigned long size;
// 指針數組的長度掩碼,用於計算索引值
// 總是等於 size - 1
unsigned long sizemask;
// 哈希表現有的節點數量
unsigned long used;
} dictht;
/*
* 哈希表節點
*/
typedef struct dictEntry {
// 鍵
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 鏈往後繼節點
struct dictEntry *next;
} dictEntry;哈希表的基本結構這裡就不再解釋了,不知道的可以百度一下。這裡解釋一下 dict 中的內容,如下(出自《Redis設計與實現第二版》第四章:字典):

Java 中 HashMap 的具體實現就不多說了,結構和上面不一樣。
Java 中 HashMap 和 redis 中字典的比較
Hash 演算法的比較
當要將一個新的鍵值對添加到字典裡面時,需要先根據鍵值對的鍵計算出哈希值和索引值,然後再根據索引值,將包含新鍵值對的哈希表節點放到哈希表數組的指定索引下麵。
Redis 是通過 MurmurHash2 演算法求出 key 的 hash 值;Java 是通過引入 hashCode 的概念計算 hash 值。
解決 hash 衝突的方法
當有兩個或以上的鍵值對被分配到 hash 表數組的同一個索引上面時,即發生了 hash 衝突。那麼 Redis 如何解決的 hash 衝突呢?
這就用到 dictEntry 結構的 next 節點了,通過 next 將 hash 表節點串起來。例:k1-v1 和 k2-v2 分配到了同一個索引下,示意圖如下(出自《Redis設計與實現第二版》第四章:字典):
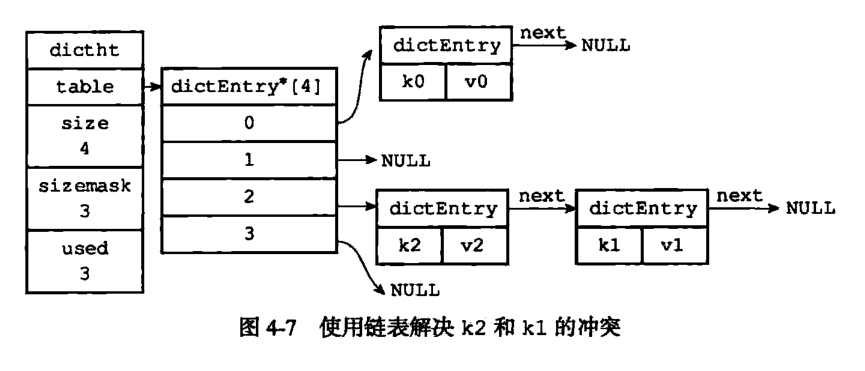
所以,理論上來說在特殊情況下 hash 會退化成鏈表。而 Java 為瞭解決 hash 表退化的問題,在 JDK1.8 的 HashMap 中引入了紅黑樹。
擴容與收縮(rehash)
隨著操作的不斷進行,哈希表保存的鍵值對會逐漸的增多或減少,如果hash表保存的鍵值對過多,會影響查詢的效率;反之,如果過小,又會浪費空間。所以程式就需要對哈希表的大小進行相應的擴容或者收縮。
無論擴容還是收縮,都涉及到三個問題:
(1)觸發條件是什麼?是手動觸發還是自動觸發。
(2)擴容或者收縮的規則是什麼?具體過程是怎樣的?
(3)當哈希表在擴容時,是否允許別的線程來操作這個哈希表?
** Redis 的實現**
Redis 中的擴展和收縮是通過 rehash 操作完成的,擴容的觸發條件是:
1) 當伺服器沒有執行 BGSAVE 命令或者 BGREWRITEAOF 命令時,負載因數大於等於 1 時觸發。
2) 當伺服器正在執行 BGSAVE 命令或者 BGREWRITEAOF 命令時,負載因數大於等於 5 時觸發。
其中:哈希表的負載因數 = 哈希表已保存節點數量 / 哈希表總長度。
收縮的條件是:哈希表的負載因數 < 0.1。
擴容的規則是:擴容至第一個大於等於 ht[0].used(當前包含鍵值對數量)* 2 的 2^n;
收縮的規則是:收縮至第一個大於等於 ht[0].used(當前包含鍵值對數量)* 2 的 2^n;
擴容和收縮的過程一樣,都是:
1) 為字典的 ht[1] 哈希表分配空間。
2) 將保存在 ht[0] 中的所有鍵值對 rehash 到 ht[1] 上。
3) 釋放 ht[0] ,ht[1] = ht[0],再為 ht[1] 新創建一個空的哈希表。
當 Redis 中的哈希表在擴容時,必須得能允許別的請求來操作哈希表。否則一旦要rehash一個很大的哈希表時,就得拒絕所有對該哈希表的請求,這是不被允許的。所以 Redis 在上面的第二步(rehash)是漸進式 rehash 的。rehash的詳細步驟如下(出自《Redis設計與實現第二版》第四章:字典):

因為在進行漸進式 rehash 的過程中,字典會同時使用 ht[0] 和 ht[l] 兩個哈希表,所以在漸進式 rehash 進行期間,字典的刪除(delete)、査找(find)、更新(update)等操作,會在兩個哈希表上進行。例如,要在字典裡面査找一個鍵的話,程式會先在ht[0]裡面進行査找,如果沒找到的話,就會繼續到ht[l]裡面進行査找,諸如此類。
另外,在漸進式 rehash 執行期間,新添加到字典的鍵值對一律會被保存到 ht[l] 裡面, 而 ht[0] 則不再進行任何添加操作,這一措施保證了 ht[0] 包含的鍵值對數量會只減不 增,並隨著 rehash 操作的執行而最終變成空表。
漸進式 rehash 的好處在於既將哈希表的擴容操作變成了線程安全的,又把計算量分攤到了對字典的每個增刪改查操作上面。
上期思考問題
上一篇遺留的問題:
Redis 中的 SDS(Simple Dynamic String)、Java中的 (StringBuilder、StringBuffer、ArrayList ),他們的擴容規則分別是什麼呢?
Redis 中的 SDS 的擴容規則是:
- 如果對 SDS 進行修改之後, SDS 的長度(也即是 len 屬性的值)將小於1M,那麼程式分配和 len 屬性同樣大小的未使用空間,這時 SDS len 屬性的值將和 free 屬性的值相同。舉個例子,如果進行修改之後, SDS 的 len 將變成 13 位元組,那麼程式也會分配 13 位元組的未使用空間, SDS 的 buf 數組的實際長度將變成 13 + 13 + 1 = 27 位元組(額外的一位元組用於保存空字元)。
- 如果對 SDS 進行修改之後, SDS 的長度將大於等於 1MB ,那麼程式會分配 1M 的未使用空間。舉個例子,如果進行修改之後,SDS 的 len 將變成 30MB,那麼程式會分配 1M 的未使用空間,SDS 的 buf 數組的實際長度將為 30MB + 1MB + 1byte。
Java中:
StringBuilder 和 StringBuffer 都繼承了 AbstractStringBuilder,擴容規則都是:擴容至 newCapacity 和 oldCapacity * 2 + 2 的最大值。部分代碼如下:
private int newCapacity(int minCapacity) { // overflow-conscious code int newCapacity = (value.length << 1) + 2; if (newCapacity - minCapacity < 0) { newCapacity = minCapacity; } return (newCapacity <= 0 || MAX_ARRAY_SIZE - newCapacity < 0) ? hugeCapacity(minCapacity) : newCapacity; }ArrayList:如果容量允許的情況下擴容至 newCapacity 和 oldCapacity + oldCapacity / 2 的最大值。 部分代碼如下:
private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }
本期思考問題:
本篇介紹了 Redis 中有關擴容和收縮的3個問題,那麼對應的 Java 中 HashMap 關於擴容和收縮的問題又是怎麼處理的呢?


