MAX()/MIN() KEEP(DENSE_RANK LAST/FIRST) 函數 解釋: 1. max() 獲取最大值; 2.min() 獲取最小值; 3. keep 保持滿足括弧內條件的內容; 4.dense_rank 排序策略,連續排序,如果有兩個同一級別時,接下來是第二級別 ,例如1,2, ...
MAX()/MIN() KEEP(DENSE_RANK LAST/FIRST) 函數
解釋:
1. max() 獲取最大值;
2.min() 獲取最小值;
3. keep 保持滿足括弧內條件的內容;
4.dense_rank 排序策略,連續排序,如果有兩個同一級別時,接下來是第二級別 ,例如1,2,2,3
select names,dept,dense_rank() over(partition by dept order by age desc) rank from workers;
結果如下圖

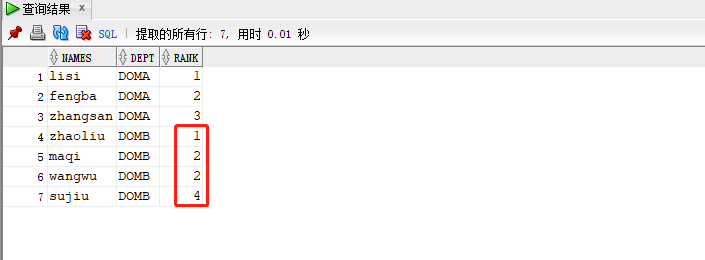
5.rank 排序策略, 跳躍排序,如果有兩個同一級別時,接下來是第三級別,例如1,2,2,4
select names,dept,rank() over(partition by dept order by age desc) rank from workers;
結果如下圖
6.first order by 按照要求對數據進行篩選,正序排
7.last order by 按照要求對數據進行篩選,倒敘排
下麵我們將進行不同的數據獲取展示:
只獲取所需要的信息,便於統計:
WITH workers AS (
SELECT 'DOMA' dept ,'zhangsan' names,23 age,4000 salaries FROM dual
UNION ALL
SELECT 'DOMA' dept ,'lisi' names,35 age,9000 salaries FROM dual
union all
SELECT 'DOMB' dept ,'wangwu' names,26 age,6500 salaries FROM dual
UNION ALL
SELECT 'DOMB' dept ,'zhaoliu' names,28 age,7000 salaries FROM dual
UNION ALL
SELECT 'DOMB' dept ,'maqi' names,26 age,6000 salaries FROM dual
UNION ALL
SELECT 'DOMA' dept ,'fengba' names,25 age,6500 salaries FROM dual
UNION ALL
SELECT 'DOMB' dept ,'sujiu' names,25 age,7000 salaries FROM dual
)
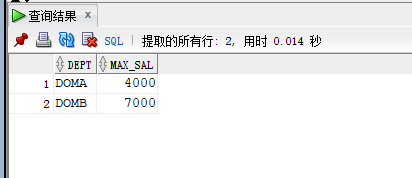
--獲取部門中年齡最小但工資最高的工資信息
SELECT A.dept,MAX(A.salaries) KEEP(DENSE_RANK FIRST ORDER BY A.age) AS max_sal FROM workers A GROUP BY A.dept;
結果如下圖
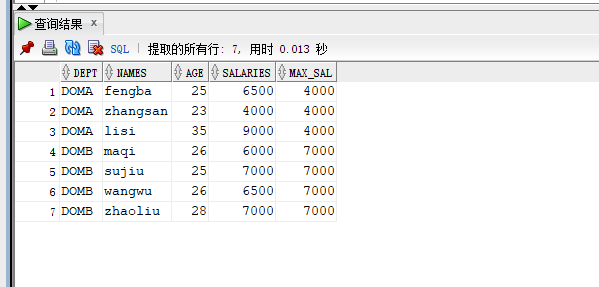
下麵是獲取人員匹配信息,將所有的信息都展示,便於直觀統計
WITH workers AS (
SELECT 'DOMA' dept ,'zhangsan' names,23 age,4000 salaries FROM dual
UNION ALL
SELECT 'DOMA' dept ,'lisi' names,35 age,9000 salaries FROM dual
union all
SELECT 'DOMB' dept ,'wangwu' names,26 age,6500 salaries FROM dual
UNION ALL
SELECT 'DOMB' dept ,'zhaoliu' names,28 age,7000 salaries FROM dual
UNION ALL
SELECT 'DOMB' dept ,'maqi' names,26 age,6000 salaries FROM dual
UNION ALL
SELECT 'DOMA' dept ,'fengba' names,25 age,6500 salaries FROM dual
UNION ALL
SELECT 'DOMB' dept ,'sujiu' names,25 age,7000 salaries FROM dual
)
--獲取部門中年齡最小但工資最高的人員信息
SELECT A.*, MAX(A.salaries) KEEP(DENSE_RANK FIRST ORDER BY A.age ) OVER(PARTITION BY A.dept) AS max_sal FROM workers A ;
結果如下圖