
為什麼需要Redis集群 需要提高更大的併發量 Redis官方提出擁有10萬QPS的請求量 如果業務需要Redis擁有100萬的QPS 可以通過集群來提升併發量。 需要存儲更大的數據量 一般伺服器的機器記憶體為16G-256G 如果業務需要500G的數據量 可以通過集群的分區技術來擴展數據量 需要提高 ...
-
需要提高更大的併發量
-
Redis官方提出擁有10萬QPS的請求量
-
如果業務需要Redis擁有100萬的QPS
-
可以通過集群來提升併發量。
-
-
需要存儲更大的數據量
-
一般伺服器的機器記憶體為16G-256G
-
如果業務需要500G的數據量
-
可以通過集群的分區技術來擴展數據量
-
數據分區
1.順序分區
例如一共有編號為1~100的100條數據,一共有3個分區ABC,則需要預先設計
-
1~33號數據落入A分區
-
34~66號數據落入B分區
-
67~100號數據落入C分區
2.哈希分區
hash(key) % node_count
3.順序分區 VS 哈希分區
| 分佈方式 | 特點 | 典型產品 |
|---|---|---|
| 哈希分佈 | 數據分散度高 鍵值分佈與業務無關 無法順序訪問 | 一致性哈希Memcache Redis Cluster 其他緩存產品 |
| 順序分佈 | 數據分散度易傾斜 鍵值分佈與業務有關 可順序訪問 | BigTable HBase |
哈希分區
1.節點取餘分區
-
含義:hash(key) % node_count
-
優點:hash+取餘的方式計算節點的分區很簡單
-
缺點:當節點伸縮時候,數據節點關係發生變化,導致數據遷移
-
擴容的時候建議翻倍擴容,可以降低數據的遷移量。
2.一致性哈希分區
-
含義:哈希+順時針(優化取餘)
-
約定長度232位的哈希環,在其中分佈若幹個hash點。
-
第一步對每個key做哈希處理得到hashVal
-
第二步將hashVal順時針偏移,得到的第一個hash點,即為分區的落點
-
-
優點:節點伸縮的時候,只會影響鄰近節點,但是還是會有數據遷移
-
翻倍的伸縮,可以保證最小的遷移數據且達到數據的負載均衡
-

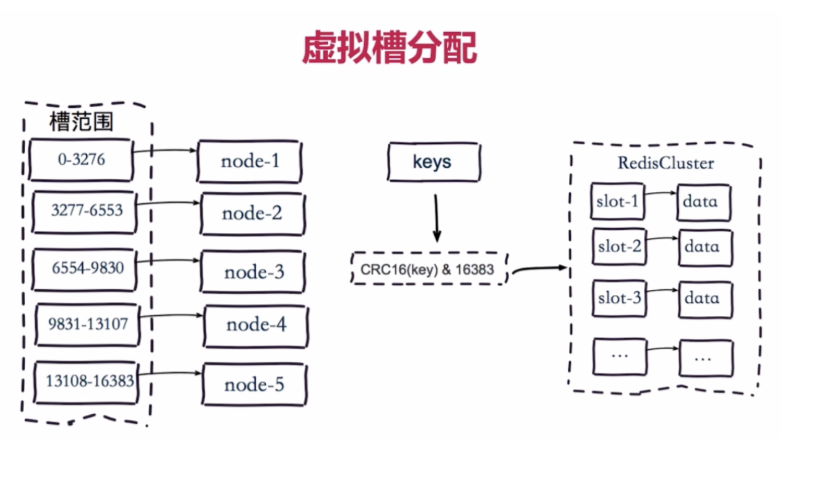
3.虛擬槽分區
-
預設虛擬槽,每個槽映射一個數據子集,一般比節點數大
-
採用CRC16(key) & 16383來決定節點
-
每個節點順序地平均分佈16384個槽,即當有5個節點時
-
A 0 ~ 3276
-
B 3277 ~ 6553
-
C 6554 ~ 9830
-
D 9831 ~ 13107
-
E 13108 ~ 16383
-

RedisCluster架構
一、節點
由多個master主節點組成,各個master都負責去讀寫,每個master都有各自的slave節點。
二、Gossip協議
多個master節點之間會使用Gossip協議進行通信
1.meet消息
用於通知新節點加入。消息發送者通知接收者加入到當前集群,meet消息通信正常完成後,接收節點會加入到集群中併進行周期性的ping、pong消息交換。
當A meet B以及A meet C之後,B就可以與C做交互了
2.ping消息
集群中交換最頻繁的消息,集群內各個節點每秒向多個其他節點發送ping消息,用於檢測節點是否線上和交換彼此狀態信息。
ping消息發送封裝了自身節點和部分其他節點的狀態數據。
3.pong消息
當接收到ping、meet消息時,作為響應消息回覆給發送方確認消息正常通信。
pong消息內部封裝了自身狀態數據。
節點也可以向集群內廣播自身的pong消息來通知整個集群對自身狀態進行更新
4.fail消息
當節點判定集群內另一個節點下線時,會向集群內廣播一個fail消息,其他節點接收到fail消息之後把對應節點更新誒下線狀態
三、指派槽
需要為RedisCluster指派槽,指定各個master節點的槽範圍,讓它進行正常的讀寫
四、複製
每個master節點包含若幹個slave節點,形成主從複製的形式,以提高高可用性。
通過各個節點之間相互監控來達到Sentinel的目的
RedisCluster安裝
RedisCluster主要配置
| 命令 | 含義 |
|---|---|
| cluster-enabled yes | 節點是否開啟集群模式 |
| cluster-node-timeout 15000 | 節點主觀下線超時時間,毫秒 |
| cluster-config-file "nodes.conf" | 集群配置文件 |
| cluster-require-full-coverage no | 是否需要所有節點全都可用,集群才能對外服務,此處推薦設置為no |
一、原生命令安裝
1.配置開啟節點
port : 7000、7001、7002、7003、7004、7005
port ${port}
daemonize yes
dir "/redisDataPath"
dbfilename "dump-${port}.rdb"
logfile "${port}.log"
cluster-enabled yes
cluster-config-file nodes-${port}.conf
2.meet
cluster meet ip port
#例如在7000埠上依次執行
cluster meet 127.0.0.1 7001
cluster meet 127.0.0.1 7002
cluster meet 127.0.0.1 7003
cluster meet 127.0.0.1 7004
cluster meet 127.0.0.1 7005
3.指派槽
cluster addslots slot [slot...]
#可以通過編寫腳本shell方便實現
#addslot.sh
port=$1
start=$2
end=$3
for slot in `seq ${start} ${end}`
do
echo "slot:${slot}"
redis-cli -p ${port} cluster addslots ${slot}
done
#
./addslot.sh 7000 0 5461
./addslot.sh 7001 5462 10922
./addslot.sh 7002 10922 16383
4.設置主從
#可以在任一節點上執行cluster nodes命令查看所有節點的node_id等信息
redis-cli -p 7000 cluster nodes
#在從節點上執行以下操作表示覆制master節點
cluster replicate node-id
#
redis-cli -h 127.0.0.1 -p 7003 cluster replicate ${node-id-7000}
redis-cli -h 127.0.0.1 -p 7004 cluster replicate ${node-id-7001}
redis-cli -h 127.0.0.1 -p 7005 cluster replicate ${node-id-7002}
二、官方工具安裝
./redis-trib.rb create --replicas 1 127.0.0.1:8000 127.0.0.1:8001
127.0.0.1:8002 127.0.0.1:8003 127.0.0.1:8004 127.0.0.1:8005
# 1 代表每個master有1個slave
# 此時,一共6個節點,每個master有1個slave,即前3個會形成master節點,後3個會形成slave節點
三、原生命令 VS redis-trib.rb
| 優點 | 缺點 | |
|---|---|---|
| 原生命令 | 易於理解Redis Cluster架構 | 生產環境不使用,太麻煩,容易犯錯 |
| redis-trib.rb | 高效,準確 生產環境可以使用 |


