
前面已經講解了公平模式的內容,今天來講解下關於非公平模式下的SynchronousQueue是如何進行工作的,在源碼分析的時候,先來簡單看一下非公平模式的簡單原理,它採用的棧這種FILO先進後出的方式進行非公平處理,它內部有三種狀態,分別是REQUEST,DATA,FULFILLING,其中REQU... ...
SynchronousQueue原理詳解-非公平模式
開篇
說明:本文分析採用的是jdk1.8
約定:下麵內容中Ref-xxx代表的是引用地址,引用對應的節點
前面已經講解了公平模式的內容,今天來講解下關於非公平模式下的SynchronousQueue是如何進行工作的,在源碼分析的時候,先來簡單看一下非公平模式的簡單原理,它採用的棧這種FILO先進後出的方式進行非公平處理,它內部有三種狀態,分別是REQUEST,DATA,FULFILLING,其中REQUEST代表的數據請求的操作也就是take操作,而DATA表示的是數據也就是Put操作將數據存放到棧中,用於消費者進行獲取操作,而FULFILLING代表的是可以進行互補操作的狀態,其實和前面講的公平模式也很類似。
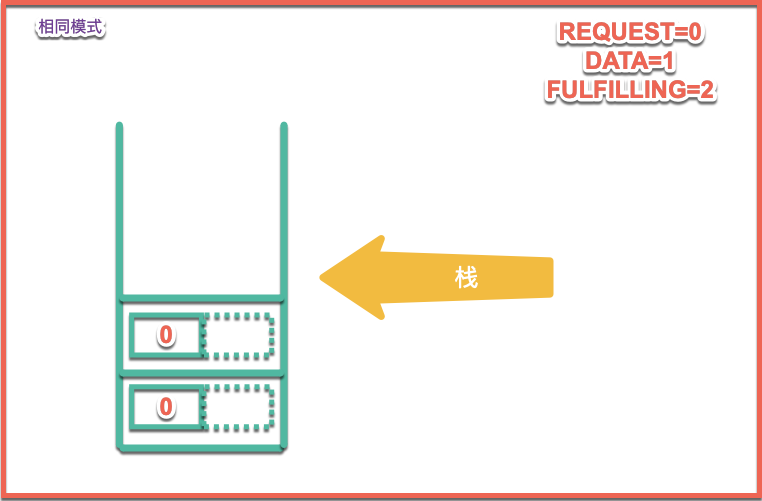
當有相同模式情況下進行入棧操作,相同操作指的是REQUEST和DATA兩種類型中任意一種進行操作時,模式相同則進行入棧操作,如下圖所示:
同REQUEST進行獲取數據時的入棧情況:
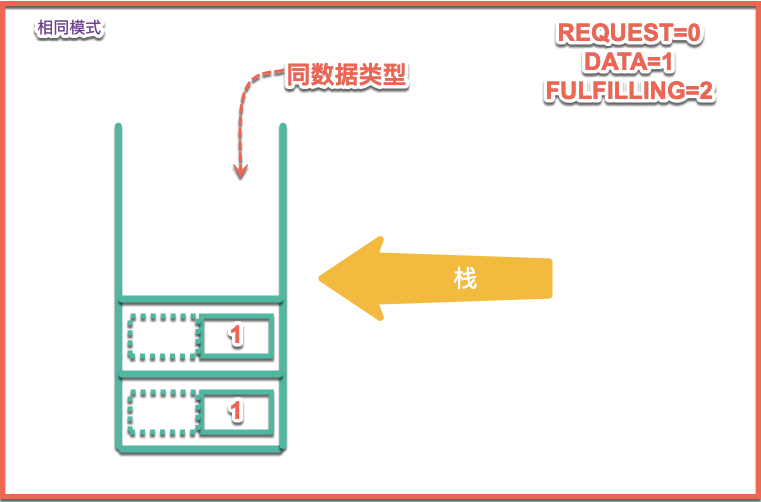
同樣的put的操作,進行數據操作時為DATA類型的操作,此時隊列情況為:
不同模式下又是如何進行操作的?當有不同模式進來的時候,他不是將當前的模式壓入棧頂,而是將FullFill模式和當前模式進行按位或之後壓入棧頂,也就是壓入一個進行FullFill請求的模式進入棧頂,請求配對操作,如下圖所示:
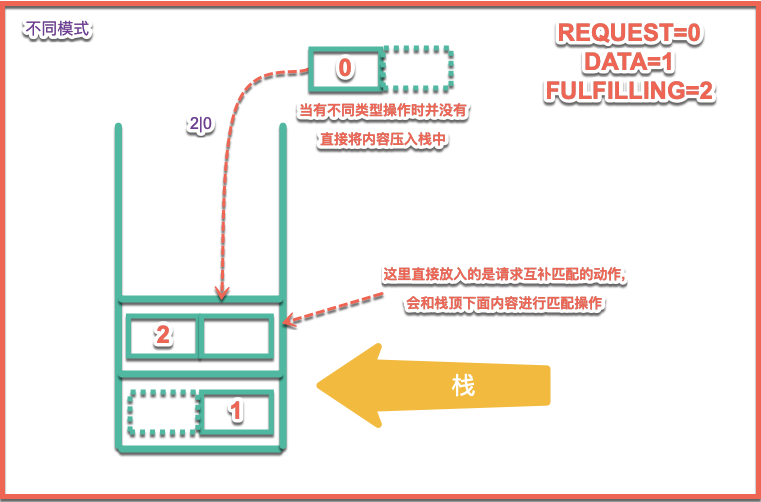
通過上圖可見,本來棧中有一個DATA模式的數據等待消費者進行消費,這時候來了一個REQUEST模式的請求操作來進行消費數據,這時候並沒有將REQUEST模式直接壓入棧頂,而是將其轉換為FULLFILLING模式,並且保留了原有的類型,這是進行FULLFILLING的請求,請求和棧頂下方元素進行匹配,當匹配成功後將棧頂和匹配元素同時進行出棧操作,詳細請見下文分析:
TransferStack
欄位信息
/** 消費者模式 */
static final int REQUEST = 0;
/** 提供者模式 */
static final int DATA = 1;
/** 互補模式 */
static final int FULFILLING = 2;
/** 棧頂指針 */
volatile SNode head;方法
| 方法名 | 描述 |
|---|---|
| isFulfilling | 判斷指定類型是否是互補模式 |
| casHead | 替換當前頭結點 |
| snode | 生成SNode節點對象 |
| transfer | 主要處理邏輯 |
| awaitFulfill | 等待fulfill操作 |
| shouldSpin | 判斷節點s是頭結點或是fulfill節點則返回true |
SNode內容
欄位信息
volatile SNode next; // 棧下一個元素
volatile SNode match; // 匹配的節點
volatile Thread waiter; // 控制park/unpark的線程
Object item; // 數據或請求
int mode; // 模式,上面介紹的三種模式方法
| 方法名 | 描述 |
|---|---|
| casNext | 判斷指定類型是否是互補模式 |
| tryMatch | 嘗試匹配節點,如果存在匹配節點則判斷是否是當前節點,直接返回判斷結果,如果沒有則替換match內容並且喚醒線程 |
| tryCancel | 生成SNode節點對象 |
| isCancelled | 主要處理邏輯 |
經過上面內容的分析,接下來就進入正題,讓我們整體先看一下下transfer都為我們做了些什麼內容,下麵是transfer源碼內容:
E transfer(E e, boolean timed, long nanos) {
/*
* Basic algorithm is to loop trying one of three actions:
*
* 1. If apparently empty or already containing nodes of same
* mode, try to push node on stack and wait for a match,
* returning it, or null if cancelled.
*
* 2. If apparently containing node of complementary mode,
* try to push a fulfilling node on to stack, match
* with corresponding waiting node, pop both from
* stack, and return matched item. The matching or
* unlinking might not actually be necessary because of
* other threads performing action 3:
*
* 3. If top of stack already holds another fulfilling node,
* help it out by doing its match and/or pop
* operations, and then continue. The code for helping
* is essentially the same as for fulfilling, except
* that it doesn't return the item.
*/
SNode s = null; // constructed/reused as needed
int mode = (e == null) ? REQUEST : DATA;
for (;;) {
SNode h = head;
if (h == null || h.mode == mode) { // 棧頂指針為空或者是模式相同
if (timed && nanos <= 0) { // 制定了timed並且時間小於等於0則取消操作。
if (h != null && h.isCancelled())
casHead(h, h.next); // 判斷頭結點是否被取消了取消了就彈出隊列,將頭結點指向下一個節點
else
return null;
} else if (casHead(h, s = snode(s, e, h, mode))) {// 初始化新節點並且修改棧頂指針
SNode m = awaitFulfill(s, timed, nanos); // 進行等待操作
if (m == s) { // 返回內容是本身則進行清理操作
clean(s);
return null;
}
if ((h = head) != null && h.next == s)
casHead(h, s.next); // help s's fulfiller
return (E) ((mode == REQUEST) ? m.item : s.item);
}
} else if (!isFulfilling(h.mode)) { // 嘗試去匹配
if (h.isCancelled()) // 判斷是否已經被取消了
casHead(h, h.next); // 彈出取消的節點並且從新進入主迴圈
else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) {//新建一個Full節點壓入棧頂
for (;;) { // 迴圈直到匹配
SNode m = s.next; // s的下一個節點為匹配節點
if (m == null) { // 代表沒有等待內容了
casHead(s, null); // 彈出full節點
s = null; // 設置為null用於下次生成新的節點
break; // 退回到主迴圈中
}
SNode mn = m.next;
if (m.tryMatch(s)) {
casHead(s, mn); // 彈出s節點和m節點兩個節點
return (E) ((mode == REQUEST) ? m.item : s.item);
} else // 如果失去了匹配
s.casNext(m, mn); // 幫助取消連接
}
}
} else { // 這裡是幫助進行fillull
SNode m = h.next; // m是頭結點的匹配節點
if (m == null) // 如果m不存在則直接將頭節點賦值為nll
casHead(h, null); // 彈出fulfill節點
else {
SNode mn = m.next;
if (m.tryMatch(h)) // h節點嘗試匹配m節點
casHead(h, mn); // 彈出h和m節點
else // 丟失匹配則直接將頭結點的下一個節點賦值為頭結點的下下節點
h.casNext(m, mn);
}
}
}
}- 模式相同的時候則進行等待操作,入隊等待操作
- 當模式不相同時,首先判斷頭結點是否是fulfill節點如果不是則進行匹配操作,如果是fulfill節點先幫助頭結點的fulfill節點進行匹配操作
接下來再來看一下awaitFulfill方法內容
SNode awaitFulfill(SNode s, boolean timed, long nanos) {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
// 等待線程
Thread w = Thread.currentThread();
// 等待時間設置
int spins = (shouldSpin(s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
if (w.isInterrupted()) // 判斷當前線程是否被中斷
s.tryCancel(); // 嘗試取消操作
SNode m = s.match; // 獲取當前節點的匹配節點,如果節點不為null代表匹配或取消操作,則返回
if (m != null)
return m;
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel();
continue;
}
}
if (spins > 0)
spins = shouldSpin(s) ? (spins-1) : 0;
else if (s.waiter == null)
s.waiter = w; // establish waiter so can park next iter
else if (!timed)
LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}通過上面的源碼,其實我們之前分析同步模式的時候差不太多,變化的地方其中包括返回內容判斷這裡判斷的是match節點是否為null,還有就是spins時間設置這裡發現了shoudSpin用來判斷是否進行輪訓,來看一下shouldSpin方法:
/**
* 判斷節點是否是fulfill節點,或者是頭結點為空再或者是頭結點和當前節點相等時則不需要進行輪訓操作
*/
boolean shouldSpin(SNode s) {
SNode h = head;
return (h == s || h == null || isFulfilling(h.mode));
}實際上就是判斷節點是否是fulfill節點,或者是頭結點為空再或者是頭結點和當前節點相等時則不需要進行輪訓操作,如果滿足上述條件就不小進行輪訓等到操作了直接進行等待就行了。
接下來我們來用例子一點點解析原理:
首先先進行一個put操作,這樣可以簡單分析下內部信息。
/**
* SynchronousQueue原理內容
*
* @author battleheart
*/
public class SynchronousQueueDemo1 {
public static void main(String[] args) throws Exception {
SynchronousQueue<Integer> queue = new SynchronousQueue<>();
Thread thread1 = new Thread(() -> {
try {
queue.put(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
thread1.start();
}
}首先它會進入到transfer方法中,進行第一步的判斷他的類型信息,如下所示:
SNode s = null; // constructed/reused as needed
int mode = (e == null) ? REQUEST : DATA;通過上面代碼可以看到e=1所以是DATA類型,接下來進行判斷是如何進行操作,當前堆棧是空的,如何判斷堆棧為空呢?上面也講到了head節點為空時則代表堆棧為空,接下來就要判斷如果head節點為空或head指向的節點和當前操作內容模式相同,則進行等待操作,如下代碼所示:
SNode h = head;
if (h == null || h.mode == mode) { // empty or same-mode
if (timed && nanos <= 0) { // can't wait
if (h != null && h.isCancelled())
casHead(h, h.next); // pop cancelled node
else
return null;
} else if (casHead(h, s = snode(s, e, h, mode))) {
SNode m = awaitFulfill(s, timed, nanos);
if (m == s) { // wait was cancelled
clean(s);
return null;
}
if ((h = head) != null && h.next == s)
casHead(h, s.next); // help s's fulfiller
return (E) ((mode == REQUEST) ? m.item : s.item);
}
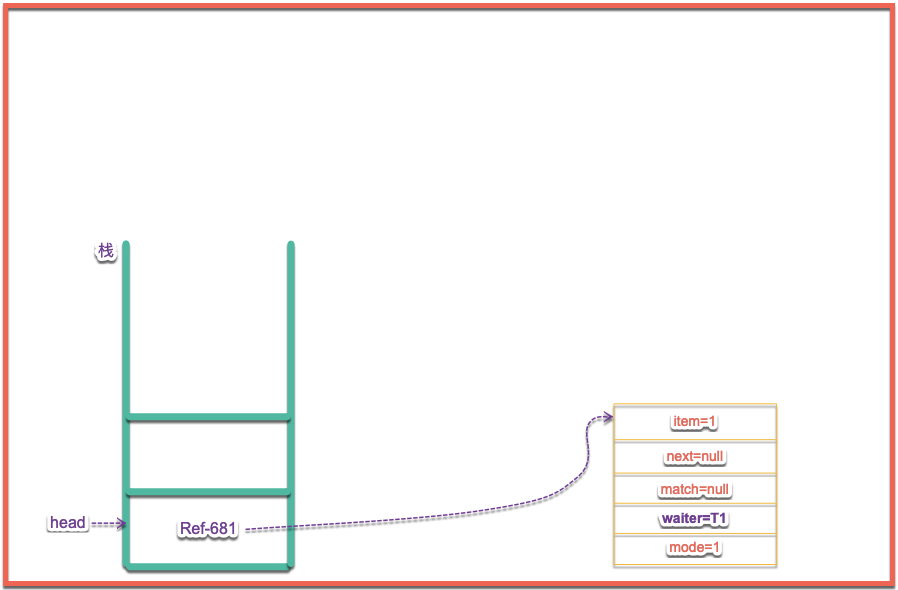
} 顯然頭結點是空的,所以進入到第一個fi語句中執行等待操作,如果指定了timed則判斷時間是否小於0,如果小於0則直接null,反之判斷當前節點是否不是頭結點以及頭結點是否取消,潘祖條件彈出頭結點,並將下一個節點設置為頭結點,上述條件在當前例子中都不滿足,所以要進入到下麵這段代碼中,首先進行對s進行初始化值,並且進行入棧操作,casHead(h, s = snode(s, e, h, mode)),下麵看一下棧中的情況如下圖所示:
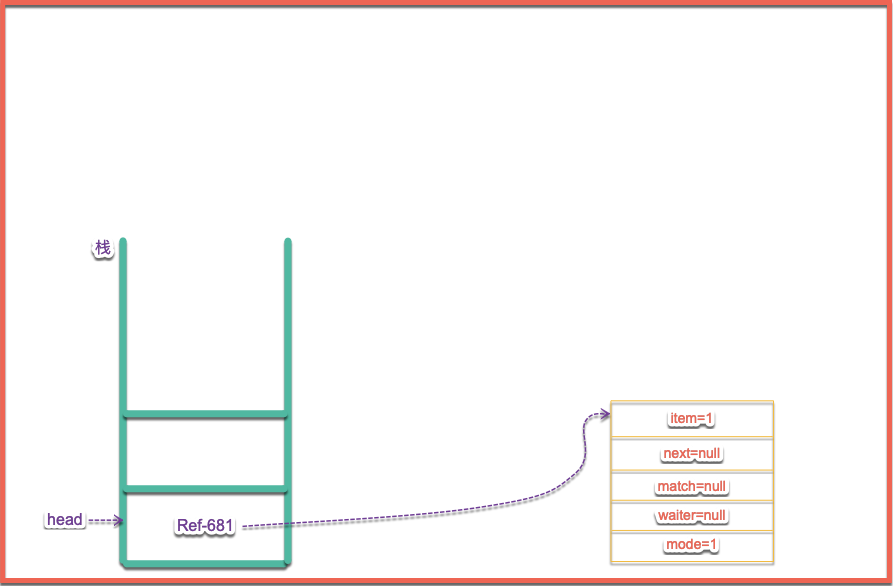
當執行完了入棧操作之後接下來要執行awaitFulfill這裡的操作就是輪訓以及將當前節點的線程賦值,並且掛起當前線程。此時的棧的情況如下圖所示:
當有同樣的模式進行操作時候也是重覆上述的操作內容,我們這裡模擬兩次put操作,讓讓我們看一下棧中的情況如下圖所示:
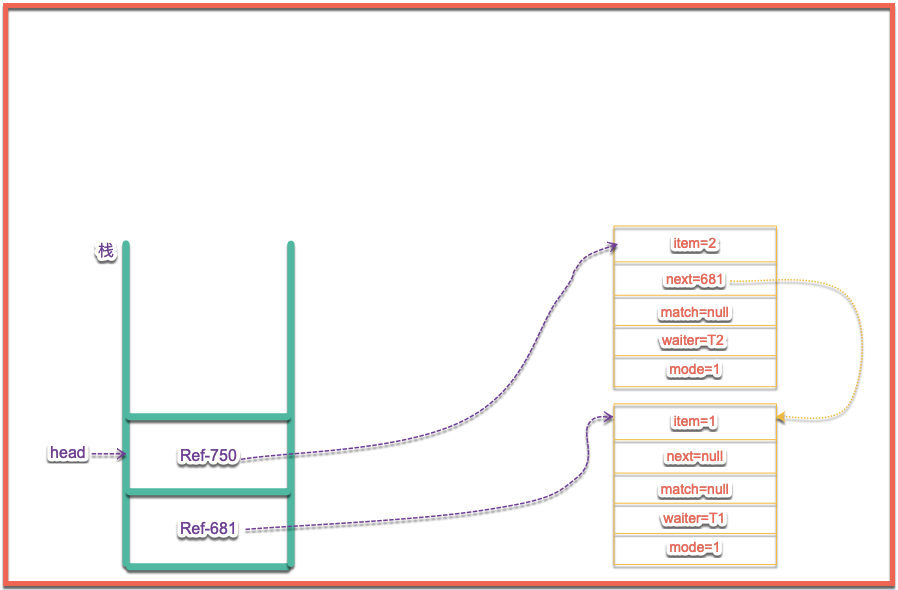
通過上圖可以看到,其實就是將頭結點移動到了新的節點上,然後新節點的next節點維護這下一個節點的引用,好了,上述內容分析是同模式的操作,接下來我們試著進行take操作時,這時候會發什麼內容呢?
/**
* SynchronousQueue例子二進行兩次put操作和一次take操作
*
* @author battleheart
*/
public class SynchronousQueueDemo1 {
public static void main(String[] args) throws Exception {
SynchronousQueue<Integer> queue = new SynchronousQueue<>();
Thread thread1 = new Thread(() -> {
try {
queue.put(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
thread1.start();
Thread.sleep(2000);
Thread thread2 = new Thread(() -> {
try {
queue.put(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
thread2.start();
Thread.sleep(2000);
Thread thread6 = new Thread(() -> {
try {
queue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
thread6.start();
}
}上面例子正好符合上面例子兩次put操作的截圖,進行兩次put操作過後再進行take操作,接下來我們來看一下take操作是如何進行操作的,換句話說當有不同模式的操作時又是如何進行處理呢?上面分析的內容是同種操作模式下的,當有不同操作則會走下麵內容:
else if (!isFulfilling(h.mode)) { // try to fulfill
if (h.isCancelled()) // already cancelled
casHead(h, h.next); // pop and retry
else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) {
for (;;) { // loop until matched or waiters disappear
SNode m = s.next; // m is s's match
if (m == null) { // all waiters are gone
casHead(s, null); // pop fulfill node
s = null; // use new node next time
break; // restart main loop
}
SNode mn = m.next;
if (m.tryMatch(s)) {
casHead(s, mn); // pop both s and m
return (E) ((mode == REQUEST) ? m.item : s.item);
} else // lost match
s.casNext(m, mn); // help unlink
}
}
} else { // help a fulfiller
SNode m = h.next; // m is h's match
if (m == null) // waiter is gone
casHead(h, null); // pop fulfilling node
else {
SNode mn = m.next;
if (m.tryMatch(h)) // help match
casHead(h, mn); // pop both h and m
else // lost match
h.casNext(m, mn); // help unlink
}
}最下麵的else我們等會來進行分析,我們看到如果不是同模式的話,則會先判斷是否是fulfill模式,如果不是fulfill模式,則進入到第一個if語句中,顯然通過圖示6可以得出,頭結點head模式並不是fillfull模式,則進入到該if語句中,上來首先判斷當前頭結點是否被取消了,如果被取消則將頭結點移動到棧頂下一個節點,反之則將s節點賦值為fulfill模式按位或當前節點模式,個人認為目的是既保留了原有模式也變成了fulfill模式,我們開篇就講到了,REQUEST=0,二進位則是00,而DATA=1,其二進位為01,而FULFILLING=2,其二進位表示10,也就是說如果當前節點是REQUEST的話那麼節點的內容值時00|10=10,如果節點是DATA模式則s節點的模式時01|10=11,這樣的話11既保留了原有模式也是FULFILLING模式,然後將頭節點移動到當前s節點,也就是將FULFILLING模式節點入棧操作,目前分析到這裡時casHead(h, s=snode(s, e, h, FULFILLING|mode),棧的情況如下圖所示:
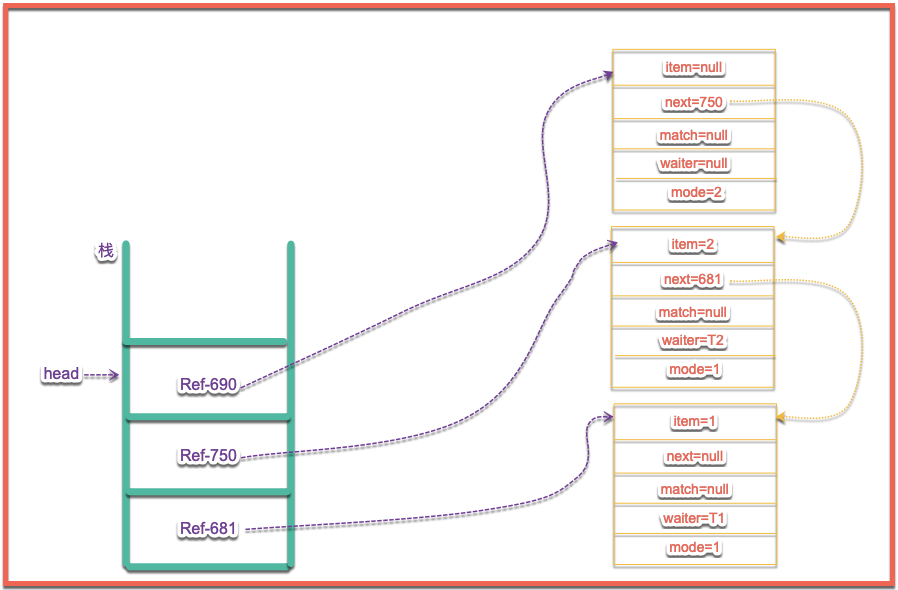
接下來運行for迴圈裡面內容,先運行如下內容:
SNode m = s.next; // m is s's match
if (m == null) { // all waiters are gone
casHead(s, null); // pop fulfill node
s = null; // use new node next time
break; // restart main loop
}先判斷當前節點也就是頭結點s的下一個節點上圖中head=s節點,所以s.next節點代表的是Ref-750,判斷當前節點是否為空,如果為空的話代表沒有可匹配的節點,先對head進行替換為null代表堆棧為空,然後將當前s節點設置為null,退出fulfill匹配模式進入到主迴圈中,會重新進行對當前節點進行操作,是消費還是匹配,顯然本例子中m節點是不為空的,所以這裡不會運行,跳過之後運行下麵內容:
SNode mn = m.next;
if (m.tryMatch(s)) {
casHead(s, mn); // pop both s and m
return (E) ((mode == REQUEST) ? m.item : s.item);
} else // lost match
s.casNext(m, mn); // help unlinkmn節點在上圖中對應的是Ref-681,這裡是重點,m.tryMatch(s),m節點嘗試匹配s節點,進入到方法里,到這一步是我們再來看一下頭結點的元素的內容:
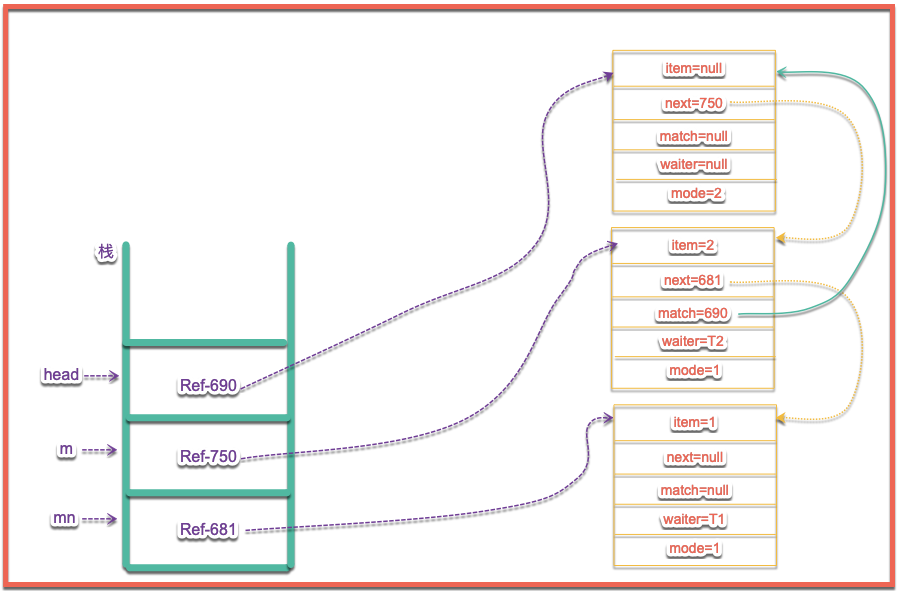
並且喚醒m節點的,告訴m節點,你現在有匹配的對象了你可以被喚醒了,這裡喚醒之後就會進入到awaitFulfill下麵的操作
SNode m = awaitFulfill(s, timed, nanos);
if (m == s) { // wait was cancelled
clean(s);
return null;
}
if ((h = head) != null && h.next == s)
casHead(h, s.next); // help s's fulfiller
return (E) ((mode == REQUEST) ? m.item : s.item);運行這裡的線程顯然是上圖中的m節點,因為m節點被喚醒了,m==s代表的是取消了節點,顯然沒有進行該操作,然後就是幫助頭結點進行fulfill操作,這裡重點說一下這段代碼:
if ((h = head) != null && h.next == s)
casHead(h, s.next); 獲取當前頭結點,也就是上圖中的頭結點如果不為空而且h.next節點為m節點正好是m節點進行操作時的s節點,也就是說這個語句是成立的,直接將頭節點指向了上圖的mn節點,這裡的操作和take中的下麵操作是一樣的,也就是幫助fulfill操作彈出棧頂和棧頂匹配的節點內容,下麵代碼:
SNode mn = m.next;
if (m.tryMatch(s)) {
casHead(s, mn); // pop both s and m
return (E) ((mode == REQUEST) ? m.item : s.item);
} else // lost match
s.casNext(m, mn); // help unlink重點是casHead的代碼,彈出s和m兩個節點,此時棧中內容如下圖所示:
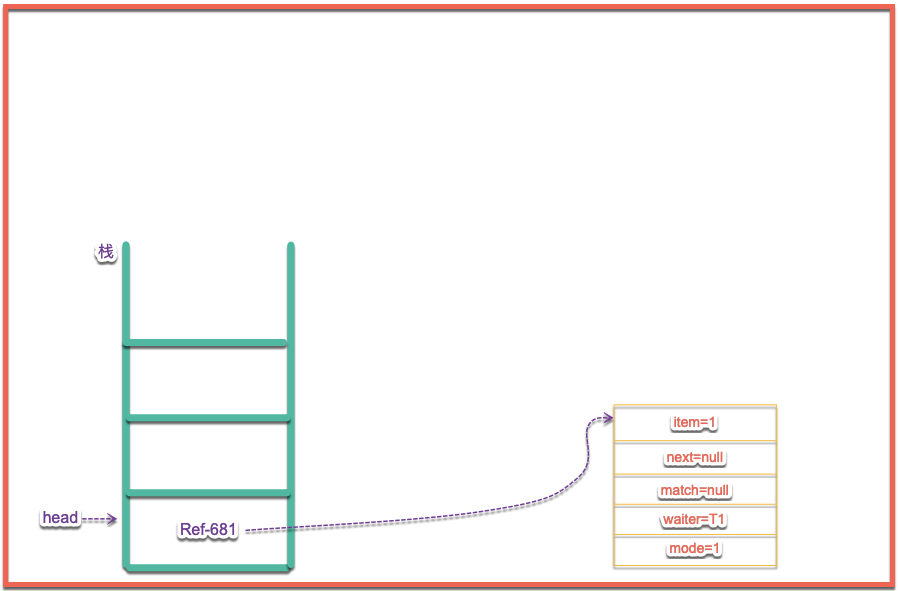
主要的流程分析完畢了,但是細心的朋友會發現,最後面還有一個幫助fulfill的操作,(transfer中)代碼如下所示:
else { // help a fulfiller
SNode m = h.next; // m is h's match
if (m == null) // waiter is gone
casHead(h, null); // pop fulfilling node
else {
SNode mn = m.next;
if (m.tryMatch(h)) // help match
casHead(h, mn); // pop both h and m
else // lost match
h.casNext(m, mn); // help unlink
}
}個人理解是這樣的,我們上面也分析到瞭如果模式是相同模式情況和如果是不同模式且模式不為匹配模式的情況,但是還會有另外一種情況就是如果是不同模式並且頭結點是匹配模式的就會進入到幫助去fullfill的情況,我來畫圖說明一下該情況:
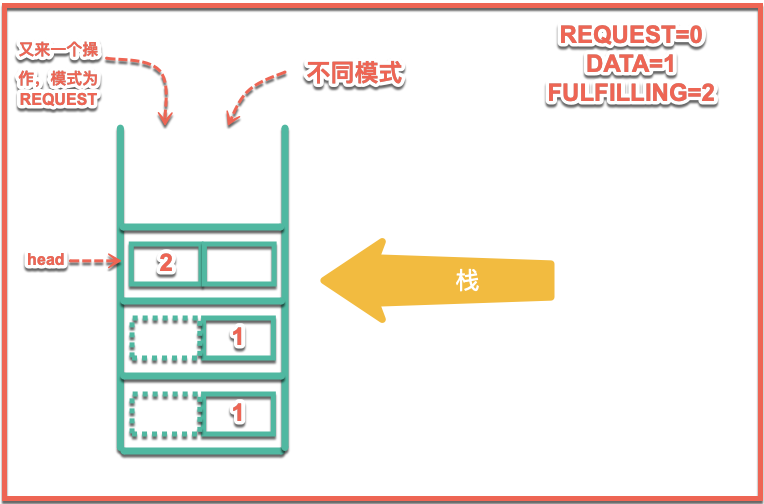
如上圖所示,上一個匹配操作沒有進行完然後又來了一個請求操作,他就會幫助head進行匹配操作,也就是運行上面的代碼邏輯,邏輯和匹配內容是一樣的。
接下來讓我們看一下取消的clean方法內容:
void clean(SNode s) {
s.item = null; // 將item值設置為null
s.waiter = null; // 將線程設置為null
SNode past = s.next; // s節點下一個節點如果不為空,並且節點是取消節點則指向下下個節點,這裡是結束的標識,代表沒有了。
if (past != null && past.isCancelled())
past = past.next;
// 如果取消的是頭節點則運行下麵的清理操作,操作邏輯很簡單就是判斷頭結點是不是取消節點,如果是則將節點一定到下一個節點
SNode p;
while ((p = head) != null && p != past && p.isCancelled())
casHead(p, p.next);
// 取消不是頭結點的嵌套節點。
while (p != null && p != past) {
SNode n = p.next;
if (n != null && n.isCancelled())
p.casNext(n, n.next);
else
p = n;
}
}通過源碼可以看到首先是先找到一個可以結束的標識past,也就說到這裡就結束了,判斷是否不是頭節點被取消了,如果是頭節點被取消了則進行第一個while語句,操作也很簡單就是將頭節點替換頭結點的下一個節點,如果不是頭節點被取消了則進行下麵的while語句操作,其實就是將取消的上一個節點的下一個節點指定為被取消節點的下一個節點,到此分析完畢了。
結束語
如果有分析不正確的請各位指正,我這邊改正~

