一、作用 slave會通過被覆制同步master上面的數據,形成數據副本 當master節點宕機時,slave可以升級為master節點承擔寫操作。 允許有一主多從,slave可以承擔讀操作,提高讀性能,master承擔寫操作。即達到讀寫分離 slave會通過被覆制同步master上面的數據,形成數 ...
一、作用
-
slave會通過被覆制同步master上面的數據,形成數據副本
-
當master節點宕機時,slave可以升級為master節點承擔寫操作。
-
允許有一主多從,slave可以承擔讀操作,提高讀性能,master承擔寫操作。即達到讀寫分離
二、簡單性質
-
一個master可以有多個slave
-
每個slave只能有一個master
-
每個slave也可以有自己的多個slave
-
數據流是單向的,從master到slave
三、創建主從的方式
1.slaveof命令
#在希望成為slave的節點中執行以下命令
slaveof ${masterIP} ${masterPort}
此過程會非同步地將master節點中的數據全量地複製到當前節點中
2.通過配置實現
| 配置項 | 含義 |
|---|---|
| salveof ${masterIP} ${masterPort} | 設置當前節點作為其他節點的slave節點 |
| slave-read-only yes | 設置當前slave節點是只讀的,不會執行寫操作 |
3.取消主從的方式
#在不希望作為slave的節點中執行以下命令
salveof no one
執行完成之後,該節點的數據不會被清除。而是不會再同步master中的數據
4.查看當前節點是否主從
info replication
run_id與偏移量
1.run_id
run_id是Redis 伺服器的隨機標識符,用於 Sentinel 和集群,服務重啟後就會改變;
當slave節點複製時發現和之前的 run_id 不同時,將會對數據進行全量同步。
查看runid
redis-cli -p 6379 info server | grep run
run_id:345dda992e5064bc80e01f96ea90f729b722b2ea
2.偏移量
通過對比主從節點的複製偏移量,可以判斷主從節點數據是否一致。
-
參與複製的主從節點都會維護自身的複製偏移量。主節點(master)在處理完寫命令後,會把命令的位元組長度做累加記錄,統計信息在info replication中的master_repl_offset指標中。
-
從節點每秒上報自身的複製偏移量給主節點,因此主節點也會保存從節點的複製偏移量
-
從節點在接收到主節點發送的命令後,也會累加記錄自身的偏移量。統計在info replication中的slave_repl_offset指標中
全量複製
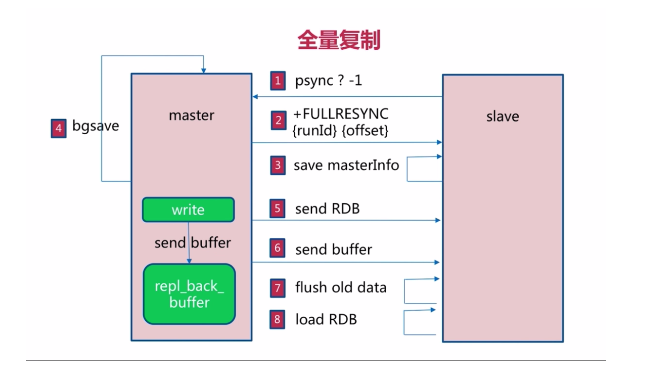
一、全量複製流程
1.slave -> master : psync ? -1
-
? 代表當前slave節點不知道master節點的runid
-
-1代表當前slave節點的偏移量為-1
2.master -> slave : +FULLRESYNC runId offset
-
master通知slave節點需要進行全量複製
-
runId:master發送自身節點的runId給slave節點
-
offset:master發送自身節點的offset給slave節點
3.slave : save masterInfo
-
slave節點保存master節點的相關信息(runId與偏移量)
4.master : bgsave
-
master節點通過bgsave命令進行RDB操作
###5.master -> slave : send RDB
-
master將bgsave完的RDB結果發送給slave節點
6.master -> slave : send buffer
-
master在執行寫操作時,會將寫命令寫入repl_back_buffer中
-
為了維護bgsave過程中執行的寫操作命令,並同步給slave,master將期間的buffer發送給slave。
7.slave : flush old data
-
slave節點將之前的數據全部清空
8.load RDB
-
slave節點載入RDB
二、全量複製的開銷
-
bgsave時間
-
RDB文件網路傳輸時間
-
slave節點清空數據時間
-
slave節點載入RDB的時間
-
可能的AOF重寫時間,當載入完RDB之後,如果開啟了AOF重寫,需要重寫AOF,以保證AOF最新
三、全量複製的高版本優化
在redis4.0中,優化了psync,簡稱psync2,實現了即使redis實例重啟的情況下也能實現部分同步
部分複製
一、部分複製流程
1.slave -> master : Connection lost
-
由於網路抖動等原因,slave對master的網路連接發生中斷
2.slave -> master : Connection to master
-
slave重新建立與master節點的連接
3.slave -> master : psync runId offset
-
slave節點發送master節點的runId以及自身的offset
4.master -> slave :CONTINUE
-
在第③步中,master節點校驗offset,在當前buffer的範圍中,則將反饋從節點CONTINUE表示部分複製。
-
如果offset不在當前buffer的範圍中,則將反饋從節點FULLRESYNC表示需要全量複製
-
buffer的大小預設為1MB,由repl_back_buffer維護
5.master -> slave : send partial data
-
發送部分數據給slave節點讓slave節點完成部分複製
故障處理
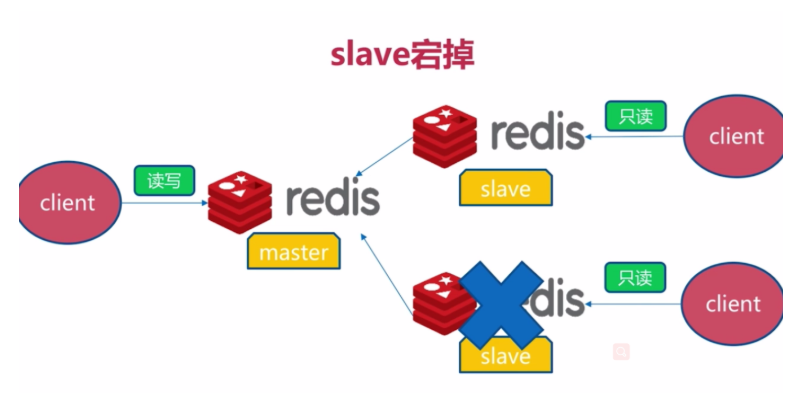
一、slave宕機故障
-
會影響redis服務的整體讀性能,對系統可用性沒有影響,將slave節點重新啟動並執行slaveof即可。
-
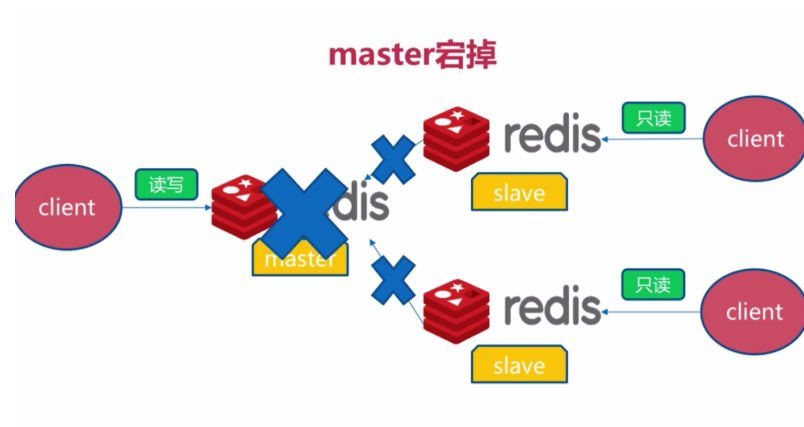
二、master宕機故障
-
redis將無法執行寫請求,只有slave節點能執行讀請求,影響了系統的可用性
-
方法1:
-
隨機找一個節點,執行slaveof no one,使其成為master節點
-
然後對其他slave節點執行slaveof newMatserIp newMasterPort
-
-
方法2:
-
馬上重啟master節點,它將會重新成為master
-
開發與運維中的問題
一、讀寫分離
-
含義:master只承擔寫請求,讀請求分攤到slave節點執行
-
可能遇到的問題
-
複製數據延遲
-
當寫操作從master同步到slave的時候,會有很短的延遲
-
當網路原因或者slave阻塞時,會有比較長的延遲
-
在這種情況下,可以通過配置一個事務中的讀寫都在主庫得已實現
-
可以通過偏移量對這類問題進行監控
-
-
讀到過期數據(在v3.2中已經解決)
-
刪除過期數據的策略1:操作key的時候校驗該key是否過期,如果已經過期,則刪除
-
刪除過期數據的策略2:redis內部有一個定時任務定時檢查key有沒有過期,如果採樣的速度比不上過期數據的產生速度,會導致很多過期數據沒有被刪除。
-
在redis集群中,有一個約定,slave節點只能讀取數據,而不能操作數據
-
-
從節點故障
-
二、配置不一致
-
maxmemory不一致:可能會丟失數據
-
例如master配置為4G,從節點配置為2G。
-
-
數據結構優化參數(例如hash-max-ziplist-entries):導致記憶體不一致
三、規避全量複製
-
第一次全量複製
-
第一次不可避免
-
小主節點(數據分片),低峰處理(夜間)
-
-
節點運行ID不匹配
-
主節點重啟(運行ID變化)
-
可以使用故障轉移進行處理,例如哨兵或集群。
-
-
複製積壓緩衝區不足
-
如果offset在緩衝區之內,則可以完成部分複製,否則需要全量複製
-
可以增大複製緩衝區的大小:rel_backlog_size,預設1M,可以提升為10MB
-
四、規避複製風暴
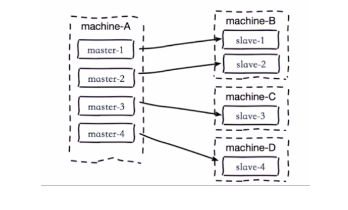
1.單主節點複製風暴
-
問題:主節點重啟,多從節點複製
-
解決:更換複製拓撲,由(m-s1,s2,s3)的模式改成(m-s1-s1a,s1b)的模式,可以減輕master的壓力
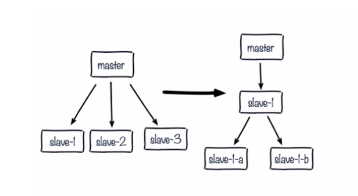
2.單機器複製風暴
-
如下圖:機器宕機後,大量全量複製
-
解決:主節點分散多機器