
1. 內容 1. 匿名函數:一句話函數,比較簡單的函數。 函數名 = lambda 參數 : 返回值 1. 此函數不是沒有名字,他是有名字的,他的名字就是你給其設置的變數,比如func。 func() 函數執行 2. lambda 是定義匿名函數的關鍵字,相當於函數的def. 3. lambda 後 ...
內容
匿名函數:一句話函數,比較簡單的函數。 函數名 = lambda 參數 : 返回值

此函數不是沒有名字,他是有名字的,他的名字就是你給其設置的變數,比如func。 func() 函數執行
lambda 是定義匿名函數的關鍵字,相當於函數的def.
lambda 後面直接加形參,形參加多少都可以,只要用逗號隔開就行。
#所有類型的形參都可以加,但是一般使用匿名函數只是加位置參數,其他的用不到 func = lambda a,b,*args,sex= 'alex',c,**kwargs: kwargs print(func(3, 4,c=666,name='alex')) # {'name': 'alex'}返回值在冒號之後設置,返回值和正常的函數一樣,可以是任意數據類型。
匿名函數不管多複雜.只能寫一行.且邏輯結束後直接返回數據.
課上練習:
def func(a,b): return a + b print(func(4,5)) # 構建匿名函數 func1 = lambda a,b: a + b print(func1(1,2))接收一個可切片的數據,返回索引為0與2的對應的元素(元組形式)。
func2 = lambda a: (a[0],a[2]) print(func2([22,33,44,55])) #(22,44) print(func2('asdfg')) #('a', 'd')寫匿名函數:接收兩個int參數,將較大的數據返回。
func = lambda a,b: a if a > b else b print(func(5,7)) # 7
內置函數
# # python 提供了68個內置函數。 #print() ''' 源碼分析 def print(self, *args, sep=' ', end='\n', file=None): # known special case of print """ print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False) file: 預設是輸出到屏幕,如果設置為文件句柄,輸出到文件 sep: 列印多個值之間的分隔符,預設為空格 end: 每一次列印的結尾,預設為換行符 flush: 立即把內容輸出到流文件,不作緩存 """ ''' print(1,2,3,4)#1 2 3 4 print(1,2,3,4,sep='&')#1&2&3&4 print(1,2,3,sep='*')#1*2*3 print(111,end='') print(222)#兩行的結果:111222 f = open('log','w',encoding='utf-8') print('寫入文件',file=f,flush=True) #int() #str() #bytes() 把字元串轉換成bytes類型 # 將字元串轉換成位元組 s = '你好' bs = bytes(s,encoding='utf-8') print(bs) #b'\xe4\xbd\xa0\xe5\xa5\xbd' # 將位元組轉換成字元串 bs = b'\xe4\xbd\xa0\xe5\xa5\xbd' s1 = str(bs,encoding='utf-8') print(s1) #你好 #bool() #set() # list() 將一個可迭代對象轉換成列表 l1 = list() #空列表 l2 = list('abcd') print(l2)#['a', 'b', 'c', 'd'] #tuple() 將一個可迭代對象轉換成元組 tu1 = tuple('abcd') print(tu1)#('a', 'b', 'c', 'd') # dict 創建字典的幾種方式 # 直接創建 dic = {'name': '太白', 'age': 18} # 元組的解構 dic = dict([(1,'one'),(2,'two'),(3,'three')] # dic = dict(one=1,two=2,three=3) print(dic)#{'one': 1, 'two': 2, 'three': 3} # fromkeys dic = { k: v for k,v in [('one', 1),('two', 2),('three', 3)]} print(dic)#{'one': 1, 'two': 2, 'three': 3} # update dic = {} dic.update([(1, 'a'), (2, 'b'), (3, 'c'), (4, 'd')]) print(dic)#{1: 'a', 2: 'b', 3: 'c', 4: 'd'} # 字典的推導式 dic = { k: v for k,v in [('one', 1),('two', 2),('three', 3)]} print(dic)#{'one': 1, 'two': 2, 'three': 3} lst1 = ['jay', 'jj', 'meet'] lst2 = ['周傑倫','林俊傑','元寶'] dic = { lst2[i]: lst1[i] for i in range(len(lst1))} print(dic)#{'周傑倫': 'jay', '林俊傑': 'jj', '元寶': 'meet'} # dic = dict(zip(['one', 'two', 'three'],[1, 2, 3])) print(dic)#{'one': 1, 'two': 2, 'three': 3} # abs() 返回絕對值*** i = -5 print(abs(i))#5 print(abs(-6)) # sum()求和【針對數字】,可以設置初始 *** print(sum([1.1,2.4,3.88]))#7.38 print(sum([1,2,3]))#6 print(sum((1,2,3),100))#106 可以設置初始值,讓初始值為100 l1 = [i for i in range(10)] print(sum(l1))#45 print(sum(l1,100))#145 s1 = '12345' #字元串 print(sum(s1)) # 錯誤 # reversed 返回的是一個翻轉的迭代器(將一個序列翻轉, 返回翻轉序列的迭代器) *** l1 = [i for i in range(10)] l1.reverse() # 列表的方法 print(l1)#[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]#對原列表操作 ret = reversed([1, 4, 3, 7, 9]) print(list(ret)) # [9, 7, 3, 4, 1] l1 = [i for i in range(10)] obj = reversed(l1) #將可迭代對象轉化為迭代器 返回的是迭代器 print(obj)#<list_reverseiterator object at 0x000002092EC877F0> print(l1)#[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] #原列表不變 print(list(obj))#[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]轉化為列表進行取值 # zip 拉鏈方法 ***面試題會考 函數用於將可迭代的對象作為參數,將對象中對應的元素打包成一個個元組,然後返回由這些元組組成的內容,如果各個迭代器的元素個數不一致,則按照長度最短的返回。 l1 = [1, 2, 3, 4, 5] tu1 = ('太白', 'b哥', '德剛') s1 = 'abcd' obj = zip(l1,tu1,s1) print(obj)#<zip object at 0x00000284D0211088> python內部提供的迭代器 for i in obj: print(i) #結果: (1, '太白', 'a') (2, 'b哥', 'b') (3, '德剛', 'c') 或: print(list(obj))#[(1, '太白', 'a'), (2, 'b哥', 'b'), (3, '德剛', 'c')] # ************* 以下方法最最最重要 # min()求最小值 和 max()求最大值 # 返回此序列最小值 l1 = [33, 2, 3, 54, 7, -1, -9] print(min(l1))#-9 print(min([1,2,-5]))#-5 # 以絕對值的方式獲取最小值 #1:求最小的絕對值 l1 = [33, 2, 3, 54, 7, -1, -9] l2 = [] func = lambda a: abs(a) for i in l1: l2.append(func(i)) print(l2)#[33, 2, 3, 54, 7, 1, 9] print(min(l2)) #1 #2:找出絕對值最小的元素 #自己寫函數 l1 = [33, 2, 3, 54, 7, -1, -9] def abss(a): return abs(a) print(min(l1,key=abss)) #-1 #直接用內置函數abs() l1 = [33, 2, 3, 54, 7, -1, -9] print(min(l1,key=abs))#-1 print(min([1,2,-5,],key=abs)) #1 ## key=函數名,按照絕對值的大小,返回此序列最小值 print(min(-5,6,-3,key=lambda x:abs(x)))# -3 可以設置很多參數比較大小 【凡是可以加key的:它會自動的將可迭代對象中的每個元素按照順序傳入key對應的函數中,以返回值比較大小。】 【 min函數迴圈的是什麼,返回的就是什麼。正常情況下:列表:返回列表中的元素。字典:返回字典的鍵。】 【 加key,是可以加'函數名',min自動會獲取傳入min函數中的參數的每個元素,然後通過函數的返回值比較大小((key=函數名,看該函數返回的是什麼。按照什麼比較大小,就將什麼設置為返回值),返回最小的返回值對應的那個傳入參數的元素。】 dic = {'a': 3, 'b': 2, 'c': 1} # 求出值最小的鍵 print(min(dic)) #a min預設會按照字典的鍵去比較大小。 #按照字典的值比較大小 #1: dic = {'a':3,'b':2,'c':1} def func(a): return dic[a] #key對應的函數的返回值是什麼,就按什麼比較大小 print(min(dic,key=func))#c #2:min函數按照什麼迴圈,lambda函數的參數位置就寫什麼。後面的返回值是根據它轉化的。 dic = {'a':3,'b':2,'c':1} func = lambda a :dic[a] print(min(dic,key=func))#c #簡化: # a為dic的key,按lambda的返回值(即dic的值dic[a])進行比較,返回最小的值對應的鍵。 dic = {'a':3,'b':2,'c':1} print(min(dic,key=lambda a:dic[a])) # c 字典中最小值對應的鍵。min函數迴圈的是什麼,返回的就是什麼。按鍵迴圈 print(dic[min(dic,key=lambda a:dic[a])]) #1 字典中最小的值 l2 = [('太白', 18), ('alex', 73), ('wusir', 35), ('口天吳', 41)] print(min(l2)) #('alex', 73) #min函數返回元組,它迴圈的是什麼,返回的就是什麼。預設按照列表中每個元組中第一個元素的首字母的Unicode比較 #自定製,+key print(min(l2,key=lambda x:x[1]))#('太白', 18) print(min(l2,key=lambda x:x[1])[0])#太白 print(min(l2,key=lambda x:x[1])[1])#18 # max最大值 與最小值用法相同 # sorted 排序函數(可加key自定製) 語法:sorted(iterable,key=None,reverse=False) iterable : 可迭代對象 key: 排序規則(排序函數),在sorted內部會將可迭代對象中的每一個元素傳遞給這個函數的參數.根據函數運算的結果進行排序 reverse :是否是倒敘,True 倒敘 False 正序 l1 = [22, 33, 1, 2, 8, 7, 6, 5] l2 = sorted(l1) print(l1)#[22, 33, 1, 2, 8, 7, 6, 5]原列表不會改變 print(l2)#[1, 2, 5, 6, 7, 8, 22, 33] #倒序: lst = [1,3,2,5,4] lst3 = sorted(lst,reverse=True) print(lst3) #[5, 4, 3, 2, 1] #字典使用sorted排序 dic = {1:'a',3:'c',2:'b'} print(sorted(dic)) # 字典排序返回的就是排序後的key [1, 2, 3] l2 = [('大壯', 76), ('雪飛', 70), ('納欽', 94), ('張珵', 98), ('b哥',96)] print(sorted(l2))#[('b哥', 96), ('大壯', 76), ('張珵', 98), ('納欽', 94), ('雪飛', 70)] print(sorted(l2,key= lambda x:x[1])) # [('雪飛', 70), ('大壯', 76), ('納欽', 94), ('b哥', 96), ('張珵', 98)]返回的是一個列表,預設從低到高 print(sorted(l2,key= lambda x:x[1],reverse=True)) #[('張珵', 98), ('b哥', 96), ('納欽', 94), ('大壯', 76), ('雪飛', 70)] #和函數組合使用 #定義一個列表,然後根據元素的長度排序 lst = ['天龍八部', '西游記', '紅樓夢', '三國演義'] #計算字元串的長度 def func(s): return len(s) print(sorted(lst, key=func))#['西游記', '紅樓夢', '天龍八部', '三國演義'] #和lambda組合使用 lst = ['天龍八部', '西游記', '紅樓夢', '三國演義'] print(sorted(lst, key=lambda s: len(s)))#['西游記', '紅樓夢', '天龍八部', '三國演義'] #按照年齡對學生信息進行排序 lst = [{'id': 1, 'name': 'alex', 'age': 18}, {'id': 2, 'name': 'wusir', 'age': 17}, {'id': 3, 'name': 'taibai', 'age': 16}, ] print(sorted(lst, key=lambda e: e['age']))#[{'id': 3, 'name': 'taibai', 'age': 16}, {'id': 2, 'name': 'wusir', 'age': 17}, {'id': 1, 'name': 'alex', 'age': 18}] # filter()篩選過濾 類似於列表推導式的篩選模式 返回的是迭代器 語法: filter(function, iterable) function: 用來篩選的函數, 在filter中會自動的把iterable中的元素傳遞給function, 然後根據function返回的True或者False來判斷是否保留此項數據 iterable: 可迭代對象 lst = [{'id': 1, 'name': 'alex', 'age': 18}, {'id': 1, 'name': 'wusir', 'age': 17}, {'id': 1, 'name': 'taibai', 'age': 16}, ] ls = filter(lambda e: e['age'] > 16, lst) #返回的是迭代器 print(list(ls))#轉化成列表 [{'id': 1, 'name': 'alex', 'age': 18}, {'id': 1, 'name': 'wusir', 'age': 17}] #列表推導式的篩選模式 l1 = [2, 3, 4, 1, 6, 7, 8] print([i for i in l1 if i > 3]) # 返回的是列表 l1 = [2, 3, 4, 1, 6, 7, 8] ret = filter(lambda x: x > 3,l1) # 返回的是迭代器 print(ret)#<filter object at 0x00000165B06D7F28> print(list(ret))#[4, 6, 7, 8] # map() 映射函數 類似於列表推導式的迴圈模式 返回的是迭代器 語法: map(function,iterable) 可以對可迭代對象中的每一個元素進映射,分別取出來執行function #列表推導式的迴圈模式 print([i**2 for i in range(1,6)]) # 返回的是列表 #[1, 4, 9, 16, 25] #計算每個元素的平方,返回新列表 ret = map(lambda x: x**2,range(1,6)) # 返回的是迭代器 print(ret)#<map object at 0x00000191237C7EB8> print(list(ret))#[1, 4, 9, 16, 25] # 計算兩個列表中相同位置的數據的和 lst1 = [1, 2, 3, 4, 5] lst2 = [2, 4, 6, 8, 10] print(list(map(lambda x, y: x+y, lst1, lst2)))#[3, 6, 9, 12, 15] # reduce # 在Python2.x版本中recude是直接 import就可以的, Python3.x版本中需要從functools這個包中導入 # reduce 的使用方式:reduce(函數名,可迭代對象) # 這兩個參數必須都要有,缺一個不行 from functools import reduce def func(x,y): return x + y ret = reduce(func,[3,4,5,6,7]) print(ret) # 結果 25 #普通函數版 from functools import reduce def func(x,y): return x * 10 + y l = reduce(func,[1,2,3,4]) print(l)#1234 第一次的時候 x是1, y是2 x乘以10就是10,然後加上y也就是2最終結果是12然後臨時存儲起來了 第二次的時候x是臨時存儲的值12 x乘以10就是 120 然後加上y也就是3最終結果是123臨時存儲起來了 第三次的時候x是臨時存儲的值123 x乘以10就是 1230 然後加上y也就是4最終結果是1234然後返回了 #匿名函數版 from functools import reduce l = reduce(lambda x,y:x*10+y,[1,2,3,4]) print(l)#1234 from functools import reduce def func(x,y): return x + y l = reduce(func,[11,2,3,4]) #第一次的時候取2個數據,之後都取1個。 print(l) ''' 第一次:x y : 11 2 x + y = 記錄: 13 第二次:x = 13 y = 3 x + y = 記錄: 16 第三次 x = 16 y = 4 ....... '''閉包:
整個歷史中的某個商品的平均收盤價。什麼叫平局收盤價呢?就是從這個商品一齣現開始,每天記錄當天價格,然後計算他的平均值:平均值要考慮直至目前為止所有的價格。
比如大眾推出了一款新車:小白轎車。
第一天價格為:100000元,平均收盤價:100000元
第二天價格為:110000元,平均收盤價:(100000 + 110000)/2 元
第三天價格為:120000元,平均收盤價:(100000 + 110000 + 120000)/3 元

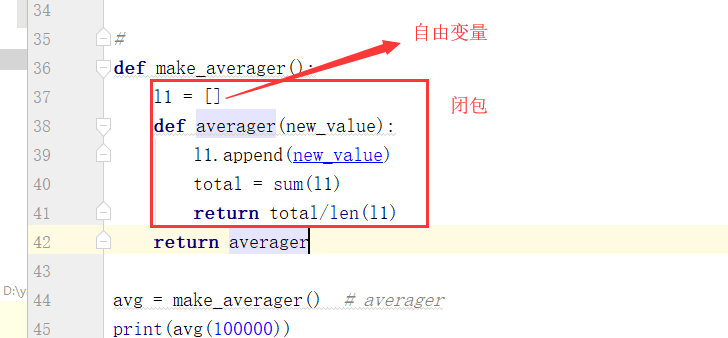
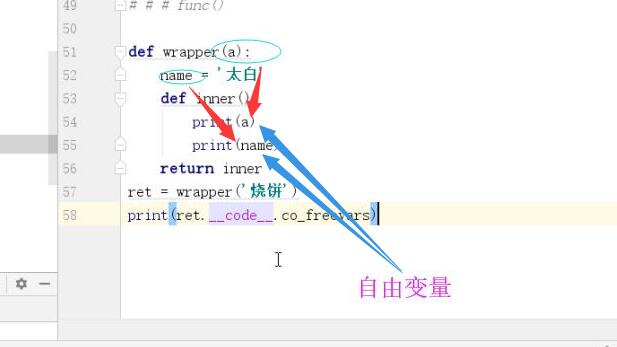
# 封閉的東西: 保證數據的安全。 # 方案一: l1 = [] # 全局變數 數據不安全 li = [] def make_averager(new_value): l1.append(new_value) total = sum(l1) averager = total/len(l1) return averager print(make_averager(100000)) print(make_averager(110000)) .....(多行代碼) l1.append(666) print(make_averager(120000)) print(make_averager(90000)) # 方案二: 數據安全,l1不能是全局變數。 # 每次執行的時候,l1列表都會重新賦值成[] li = [] def make_averager(new_value): l1 = [] l1.append(new_value) total = sum(l1) averager = total/len(l1) return averager print(make_averager(100000)) print(make_averager(110000)) .....(多行代碼) print(make_averager(120000)) print(make_averager(90000)) # 方案三: 閉包 #在函數中嵌套了一個函數。avg 這個變數接收的實際是averager函數名,也就是其對應的記憶體地址,我執行了三次avg 也就是執行了三次averager這個函數。 def make_averager(): l1 = [] def averager(new_value): l1.append(new_value) print(l1) total = sum(l1) return total/len(l1) return averager avg = make_averager() # 【重點理解】返回值averager給avg avg得到了內層函數的記憶體地址,所以外層函數執行完後,只要有內層函數的記憶體地址,下麵的print語句依然可以執行內層函數 print(avg(100000)) print(avg(110000)) print(avg(120000)) print(avg(190000)) ## 函數名.__code__.co_freevars 查看函數的自由變數 print(avg.__code__.co_freevars)#('l1',) # 函數名.__code__.co_varnames 查看函數的局部變數 print(avg.__code__.co_varnames)#('new_value', 'total') #獲取具體的自由變數對象,也就是cell對象。 print(avg.__closure__)#(<cell at 0x0000029744E374C8: list object at 0x0000029744ECE948>,) #cell_contents 自由變數具體的值 print(avg.__closure__[0].cell_contents)#[] def func(): return 666 print(func)#<function func at 0x00000219A46C9AE8> 函數名指向函數的記憶體地址 print(globals())#不包含 'ret': 666 ret = func() print(globals())#包含 'ret': 666 閉包: 多用於面試題: 什麼是閉包? 閉包有什麼作用。 閉包的定義: 1,閉包只能存在嵌套函數中。閉包是嵌套在函數中的函數 2,閉包必須是內層函數對外層函數非全局變數的引用(使用),就會形成閉包。【使用:可改變 引用:直接使用,如print()】 自由變數:被引用的非全局變數也稱作自由變數,這個自由變數會與內層函數產生一個綁定關係,自由變數不會在記憶體中消失,而且全局還引用不到。 閉包的作用:保證數據的安全。保存局部信息不被銷毀,保證數據的安全性。 閉包的應用:可以保存一些非全局變數但是不易被銷毀、改變的數據。裝飾器 # 如何判斷一個嵌套函數是不是閉包 1,閉包只能存在嵌套函數中。 2,內層函數對外層函數非全局變數的引用(使用),就會形成閉包。 # 例1:是閉包 def wrapper(): a = 1 #a是自由變數 def inner(): print(a) return inner ret = wrapper() # 例2:也是閉包!【講】 def wrapper(a,b): #傳參相當於a=2,b=3,相當於在函數內重新定義變數,所以a,b都是外層函數的非全局變數,即a,b都是自由變數 def inner(): print(a) print(b) return inner a = 2 b = 3 ret = wrapper(a,b) print(ret.__code__.co_freevars) # ('a', 'b') #用幾個就有幾個自由變數 print(ret.__closure__)#(<cell at 0x000001F3155274C8: int object at 0x00000000513A6C30>, <cell at 0x000001F3155274F8: int object at 0x00000000513A6C50>) print(ret.__closure__[0].cell_contents)# 2 print(ret.__closure__[1].cell_contents)# 3 #例3: def wrapper(): count = 1 # 不可變數據類型 def inner(): nonlocal count #count是自由變數 count += 1 print(count) # 1 inner() print(count) # 2 return inner ret = wrapper() print(ret.__code__.co_freevars)#('count',) # 如何代碼判斷閉包? def make_averager(): l1 = [] #l1是自由變數 def averager(new_value): l1.append(new_value) print(l1) total = sum(l1) return total/len(l1) return averager avg = make_averager() # averager print(avg.__code__.co_freevars)總結
匿名函數。
內置函數。
***一定要記住,敲3遍以上。**儘量記住,2遍。閉包:多用於面試題: 什麼是閉包? 閉包有什麼作用。

