
好像博客有觀眾,那每一篇都畫個圖吧! 本節簡圖如下。 上一篇其實啥也沒講,不過node本身就是這麼複雜,走流程就要走全套。就像曾經看webpack源碼,讀了300行代碼最後就為了取package.json裡面的main屬性,導致我直接棄坑了,垃圾源碼看完對腦子沒一點好處。回頭看了我之前那篇博客,同步 ...
好像博客有觀眾,那每一篇都畫個圖吧!
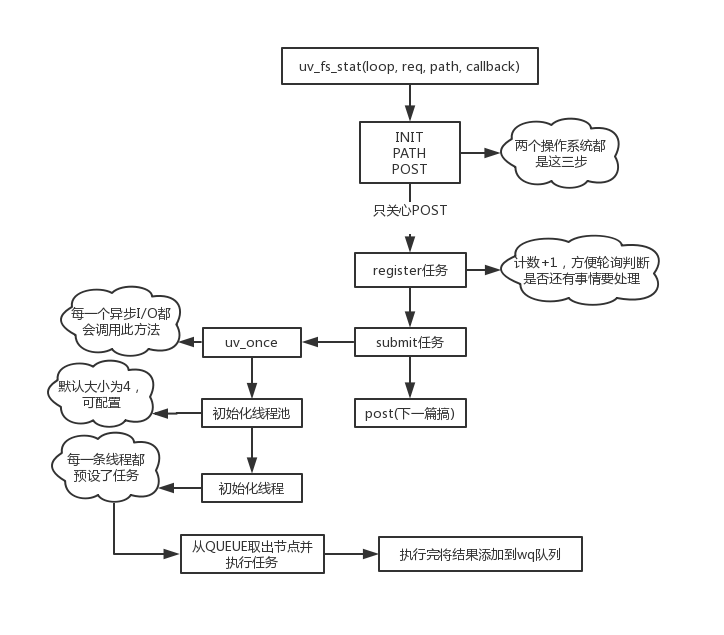
本節簡圖如下。
上一篇其實啥也沒講,不過node本身就是這麼複雜,走流程就要走全套。就像曾經看webpack源碼,讀了300行代碼最後就為了取package.json裡面的main屬性,導致我直接棄坑了,垃圾源碼看完對腦子沒一點好處。回頭看了我之前那篇博客,同步那塊講的還像回事,非同步就慘不忍睹了。不過講道理,非同步中涉及鎖、底層操作系統API(iocp)的部分我到現在也不太懂,畢竟沒有實際的多線程開發經驗,只是純粹的技術愛好者。
這一篇再次進入libuv內部,從uv_fs_stat開始,操作系統以windows為準,方法源碼如下。
// 參數分別為事件輪詢對象loop、管理事件處理的對象req、路徑path、事件回調cb int uv_fs_stat(uv_loop_t* loop, uv_fs_t* req, const char* path, uv_fs_cb cb) { int err; INIT(UV_FS_STAT); err = fs__capture_path(req, path, NULL, cb != NULL); if (err) { return uv_translate_sys_error(err); } POST; }
其實Unix版本的代碼更簡潔,直接就是
int uv_fs_stat(uv_loop_t* loop, uv_fs_t* req, const char* path, uv_fs_cb cb) { INIT(STAT); PATH; POST; }
問題不大,都是三步。
前面兩步在那篇都有介紹,這裡就不重覆了。大概就是根據操作類型初始化req對象,然後處理一下路徑,分配合理的空間給path字元串這些。
重點還是放在POST巨集。
#define POST \ do { \ if (cb != NULL) { \ uv__req_register(loop, req); \ // word_req是一個類型為uv__work的結構體 // UV__WORK_FAST_IO是I/O操作類型 // uv__fs_work是一個函數 // uv__fs_done也是一個函數 uv__work_submit(loop, \ &req->work_req, \ UV__WORK_FAST_IO, \ uv__fs_work, \ uv__fs_done); \ return 0; \ } else { \ uv__fs_work(&req->work_req); \ return req->result; \ } \ } \ while (0)
由於只關註非同步操作,所以看if分支。參數已經在註釋中給出,還需要註意的一個點是方法名,register、submit,即註冊、提交。意思是,非同步操作中,在這裡也不是執行I/O的地點,實際上還有更深入的地方,繼續往後面看。
uv__req_register這個就不看了,簡單講是把loop的active_handle++,每一輪輪詢結束後會檢測當前loop是否還有活躍的handle需要處理,有就會繼續跑,判斷標準就是active_handle數量是否大於0。
直接看下一步uv__work_submit。
// uv__word結構體 struct uv__work { void (*work)(struct uv__work *w); void (*done)(struct uv__work *w, int status); struct uv_loop_s* loop; void* wq[2]; }; // 參數參考上面 init_once是一個方法 void uv__work_submit(uv_loop_t* loop, struct uv__work* w, enum uv__work_kind kind, void (*work)(struct uv__work* w), void (*done)(struct uv__work* w, int status)) { uv_once(&once, init_once); w->loop = loop; w->work = work; w->done = done; post(&w->wq, kind); }
又是兩部曲,第一個uv_once如其名,這個方法只會執行一次,然後將loop對象和兩個方法掛在前面req的uv__work結構體上,最後調用post。
uv_once這個方法有點意思,本身跟stat操作本身毫無關係,只是對所有I/O操作做一個準備工作,所有的I/O操作都會預先調一下這個方法。windows、Unix系統的處理方式完全不同,這裡貼一貼代碼,Unix不想看也看不懂,搞搞windows系統的。
void uv_once(uv_once_t* guard, void (*callback)(void)) { // 調用過方法此處ran為1 直接返回 if (guard->ran) { return; } uv__once_inner(guard, callback); } static void uv__once_inner(uv_once_t* guard, void (*callback)(void)) { DWORD result; HANDLE existing_event, created_event; // 創建或打開命名或未命名的事件對象 created_event = CreateEvent(NULL, 1, 0, NULL); if (created_event == 0) { uv_fatal_error(GetLastError(), "CreateEvent"); } // 對&guard->event與NULL做原子比較 如果相等則將created_event賦予&guard->event // 返回第一個參數的初始值 existing_event = InterlockedCompareExchangePointer(&guard->event, created_event, NULL); // 如果第一個參數初始值為NULL 說明該線程搶到了方法第一次執行權利 if (existing_event == NULL) { /* We won the race */ callback(); result = SetEvent(created_event); assert(result); guard->ran = 1; } else { // ... } }
分塊來解釋一下上面的函數吧。
- libuv這裡直接跟操作系統通信,在windows上需要藉助其自身的event模塊來輔助非同步操作。
- 提前劇透一下,所有的I/O操作是調用獨立線程進行處理,所以這個uv_once會被多次調用,而多線程搶調用的時候有兩種情況;第一種最簡單,第一名已經跑完所有流程,將ran設置為1,其餘線程直接被擋在了uv_once那裡直接返回了。第二種就較為複雜,兩個線程同時接到了這個任務,然後都跑進了uv_once_inner中去了,如何保證參數callback只會被調用一次?這裡用上了windows內置的原子指針比較方法InterlockedCompareExchangePointer。何謂原子比較?這是只有在多線程才會出現的概念,原子性保證了每次讀取變數的值都是根據最新信息計算出來的,避免了多線程經常出現的競態問題,詳細文獻可以參考wiki。
- 只有第一個搶到了調用權利的線程才會進入if分支,之後調用callback方法,並設置event,那個SetEvent也是windowsAPI,有興趣自己研究去。
最後,所有的代碼流向都為了執行callback,參數表明這是一個函數指針,無返回值無參數,叫init_once。
static void init_once(void) { #ifndef _WIN32 // 用32位系統的去買新電腦 // 略... #endif init_threads(); }
有意思咯,線程來了。
先表明,libuv中有一個非常關鍵的數據結構:隊列,在src/queue.h。很多地方(比如之前講輪詢的某一階段取對應的callback時)我雖然說的是鏈表,但實際上用的是這個,由於鏈表是隊列的超集,而且比較容易理解,總的來說也不算錯。說這麼多,其實是初始化線程池會用到很多queue的巨集,我不想講,後面會單獨開一篇說。
下麵上代碼。
static void init_threads(void) { unsigned int i; const char* val; uv_sem_t sem; // 線程池預設大小為4 nthreads = ARRAY_SIZE(default_threads); // 可以通過環境變數UV_THREADPOOL_SIZE來手動設置 val = getenv("UV_THREADPOOL_SIZE"); // 如果設成0會變成1 大於上限會變成128 if (val != NULL) nthreads = atoi(val); if (nthreads == 0) nthreads = 1; if (nthreads > MAX_THREADPOOL_SIZE) nthreads = MAX_THREADPOOL_SIZE; threads = default_threads; // 分配空間 靜態變數threads負責管理線程 if (nthreads > ARRAY_SIZE(default_threads)) { threads = uv__malloc(nthreads * sizeof(threads[0])); if (threads == NULL) { nthreads = ARRAY_SIZE(default_threads); threads = default_threads; } } // 這裡是鎖和QUEUE相關... // 這裡給線程設置任務 喚醒後直接執行worker方法 for (i = 0; i < nthreads; i++) if (uv_thread_create(threads + i, worker, &sem)) abort(); // 無關代碼... }
除去一些不關心的代碼,剩下的就是判斷是否有手動設置線程池數量,然後初始化分配空間,最後迴圈給每一個線程分配任務。
這個worker可以先簡單看一下,大部分內容都是QUEUE相關,詳細內容全部寫在註釋裡面。
static void worker(void* arg) { // ... // 這個是給代碼塊加鎖 很多地方都有 uv_mutex_lock(&mutex); for (;;) { // ..。 // 從隊列取出一個節點 q = QUEUE_HEAD(&wq); // 表示沒有更多要處理的信息 直接退出絕不能繼續走下麵的 // 退出前還會兩個操作 1.喚醒另一個線程再次處理這個方法(可能下一瞬間來活了) 2.去掉鎖 if (q == &exit_message) { uv_cond_signal(&cond); uv_mutex_unlock(&mutex); break; } // 從隊列中移除這個節點 QUEUE_REMOVE(q); QUEUE_INIT(q); is_slow_work = 0; // node過來的都是快速通道 不會走這裡 if (q == &run_slow_work_message) { //... } // 由於已經從隊列中移除了對應節點 這裡可以把鎖去掉了 uv_mutex_unlock(&mutex); // 從節點取出對應的任務 執行work也就是實際的I/O操作(比如fs.stat...) 參考上面的uv__work_submit方法 w = QUEUE_DATA(q, struct uv__work, wq); w->work(w); // 這裡也需要加鎖 執行完節點任務後需要將結果添加到word_queue的隊列中 uv_mutex_lock(&w->loop->wq_mutex); w->work = NULL; QUEUE_INSERT_TAIL(&w->loop->wq, &w->wq); uv_async_send(&w->loop->wq_async); uv_mutex_unlock(&w->loop->wq_mutex); // 由於是for(;;) 這裡加鎖純粹是為了下一次提前準備迴圈 uv_mutex_lock(&mutex); if (is_slow_work) { /* `slow_io_work_running` is protected by `mutex`. */ slow_io_work_running--; } } }
註意是靜態方法,所以也需要處理多線程問題。註釋我寫的非常詳細了,可以慢慢看,不懂C++也大概能明白流程。
還以為這一篇能搞完,沒想到這個流程有點長,先這樣吧。

