
筆記記錄自林曉斌(丁奇)老師的《MySQL實戰45講》 (本篇內圖片均來自丁奇老師的講解,如有侵權,請聯繫我刪除) 21) --為什麼我只改一行語句,鎖這麼多? 之前我們介紹了間隙鎖和next-key lock的概念,但是並沒有說明加鎖規則。所以今天我們就從加鎖規則開始。但這個規則有兩點要提前說明一 ...
筆記記錄自林曉斌(丁奇)老師的《MySQL實戰45講》
(本篇內圖片均來自丁奇老師的講解,如有侵權,請聯繫我刪除)
21) --為什麼我只改一行語句,鎖這麼多?
之前我們介紹了間隙鎖和next-key lock的概念,但是並沒有說明加鎖規則。所以今天我們就從加鎖規則開始。但這個規則有兩點要提前說明一下:
- MySQL後面的版本可能會改變加鎖策略,所以這個規則受限於版本。即5.x系列 <= 5.7.24, 8.0系列 <=8.0.13.
- 如果有bad case的話請提出來,大家一起學習。(這裡我會關註丁奇老師這篇內容下的評論,如果確實有這種情況我會補充出來。)
因為間隙鎖在可重覆讀隔離級別下才有效,所以本篇接下來的描述如果沒有特殊說明,預設都是可重覆讀隔離級別。
這裡包含兩個“原則”,兩個“優化”和一個“bug”
- 原則1:加鎖的基本單位是next-key lock。next-key lock是前開後閉區間。
- 原則2:查找過程中訪問到的對象才會加鎖。
- 優化1:索引上的等值查詢,給唯一索引加鎖的時候,next-key lock退化為行鎖。
- 優化2:索引上的等值查詢,向右遍歷時且最後一個值不滿足等值條件的時候,next-key lock 退化為間隙鎖。
- 一個bug:唯一索引上的範圍查詢會訪問到不滿足條件的第一個值為止。
我們還是以上篇文章的表t為例,來解釋一下這些規則,表t的建表語句和初始化語句如下:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
有些例子可能會“毀三觀”,建議可以親手實踐一下。
案例一:等值查詢間隙鎖
第一個例子是關於等值條件操作間隙:

等值查詢的間隙鎖
由於表t中沒有id=7的記錄,所以用我們上面提到的加鎖規則判斷一下的話:
- 根據原則1,加鎖單位是next-key lock,SessionA加鎖範圍是(5,10];
- 同時根據優化2,這是一個等值查詢(id=7),而id=10不滿足查詢條件,next-key lock退化成間隙鎖,因此最終加鎖範圍是(5,10)。
所以Session B是要往這個間隙裡面插入id=8的記錄會被鎖住,但是session C修改id=10這行是可以的。
案例二:非唯一索引等值鎖
第二個例子是關於覆蓋索引上的鎖:

只加在非唯一索引上的鎖
看到這個例子,你是不是有一種“該鎖的不鎖,不該鎖的亂鎖”的感覺?我們來分析一下吧。
這裡的Session A要給索引c上c=5這一行加上讀鎖。
- 根據原則1,加鎖單位是next-key lock,因此會給(0,5]加上next-key lock.
- 要註意c是普通索引,因此僅訪問c=5這一條記錄是不能馬上停下來的,需要向右遍歷,查到c=10才放棄。根據原則2,訪問到的都要加鎖,因此要給(5,10]加上next-key lock
- 但是同時這個符合優化2:等值判斷,向右遍歷,最後一個值不滿足c=5這個等值條件,因此退化成間隙鎖(5,10)。
- 根據原則2,只有訪問到的對象才會加鎖。這個查詢使用覆蓋索引,並不需要訪問主鍵索引,所以主鍵索引上沒有加任何鎖,這就是為什麼session B的update語句可以執行完成。
但Session C要插入一個(7,7,7)的記錄,就會被Session A的間隙鎖(5,10)鎖住。需要註意的是,在這個例子中,lock in share mode只鎖了覆蓋索引,但是如果是for update就不一樣了。執行for update的時候,系統會認為你接下來要更新數據,因此會順便給主鍵索引上滿足條件的行加上行鎖。這個例子說明,鎖是加在索引上的;同時,它給我們的指導是,如果你要用lock in share mode來給行加讀鎖避免數據被更新的話,就必須得繞過覆蓋索引的優化,在查詢欄位中加入索引中不存在的欄位。比如,將Session A的查詢語句改成 select d from t where c = 5 lock in share mode.
案例三:主鍵索引範圍鎖
第三個例子是關於範圍查詢的。
舉例之前,我們先來思考一下,對於我們這個表t,下麵這兩條查詢語句,加鎖範圍相同嘛?
mysql> select * from t where id=10 for update; mysql> select * from t where id>=10 and id<11 for update;
你可能會想,id為int類型,這兩個語句是等價的吧?其實,它們並不完全等價。當然,在邏輯上這兩條語句還是等價的。但實際上它們的加鎖規則不太一樣。現在,我們就讓Session A執行第二個查詢語句,來看看加鎖效果。

主鍵索引上範圍查詢的鎖
現在我們利用前面提到的加鎖規則,來分析一下Session A會加什麼鎖呢?
- 開始執行的時候,要找到第一個id=10的行,因此本該是next-key lock(5,10].根據優化1,主鍵id上的等值條件,退化成行鎖,只加了id=10這一行的行鎖。
- 範圍查找就往後繼續找,找到id=15這一行停下來,因此需要加next-key lock(10,15].
所以,Session A這時候鎖的範圍就是主鍵索引上,行鎖id=10和next-key lock(10,15]。這樣,Session B和Session C的結果你就能理解了。這裡你需要註意一點,首次Session A定位查找id=10的行的時候,是當作等值查詢來判斷的,而向右掃描到id=15的時候,用的是範圍查詢判斷。
案例四:非唯一索引範圍鎖
接下來,我們再看兩個範圍查詢加鎖的例子,你可以對照著案例三來看。需要註意的是,案例四中查詢語句的where部分用的是欄位c。
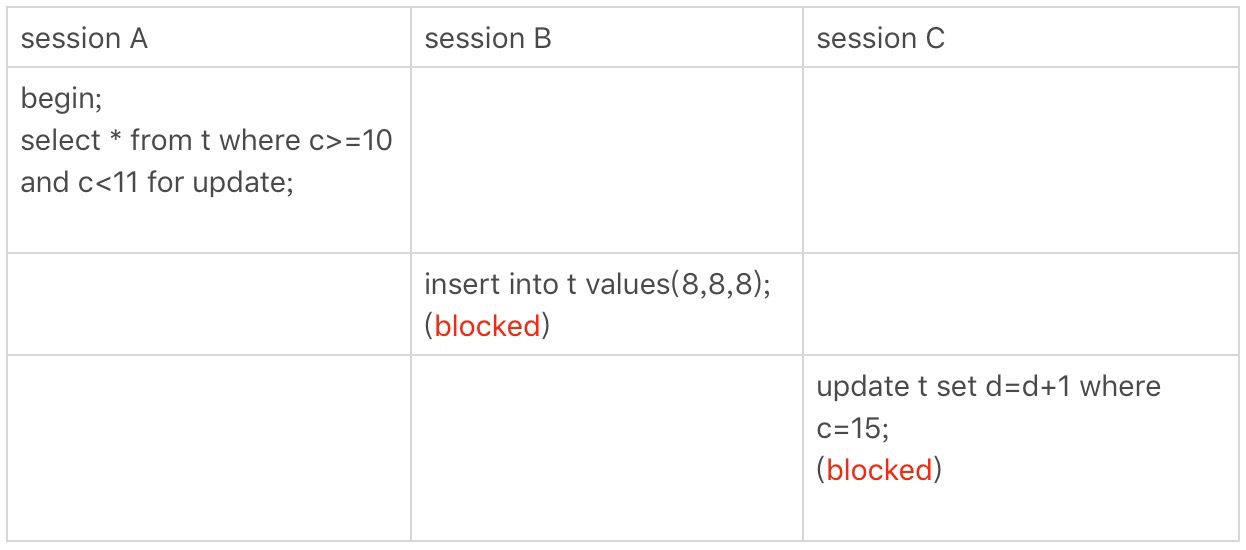
非唯一索引範圍鎖
這次Session A用欄位c來判斷,加鎖規則跟案例三唯一不同的是:在第一次用c=10定位記錄的時候,索引c上加了(5,10]這個next-key lock後,由於索引c是唯一索引,沒有優化規則,也就是說不會退變為行鎖,因此最終Session A加的鎖是,索引C上的(5,10]和(10,15]這兩個next-key lock。所以結果上看,Session B要插入(8,8,8)的這個insert語句就被堵住了。
這裡需要掃描到c=15才停止掃描,是合理的。因為InnoDB要掃到c=15,才知道不要繼續往後找了。
案例五:唯一索引範圍鎖bug
前面的四個案例,我們已經用到了加鎖規則中的兩個原則和兩個優化,接下來再看一個關於加鎖規則中的bug的案例。
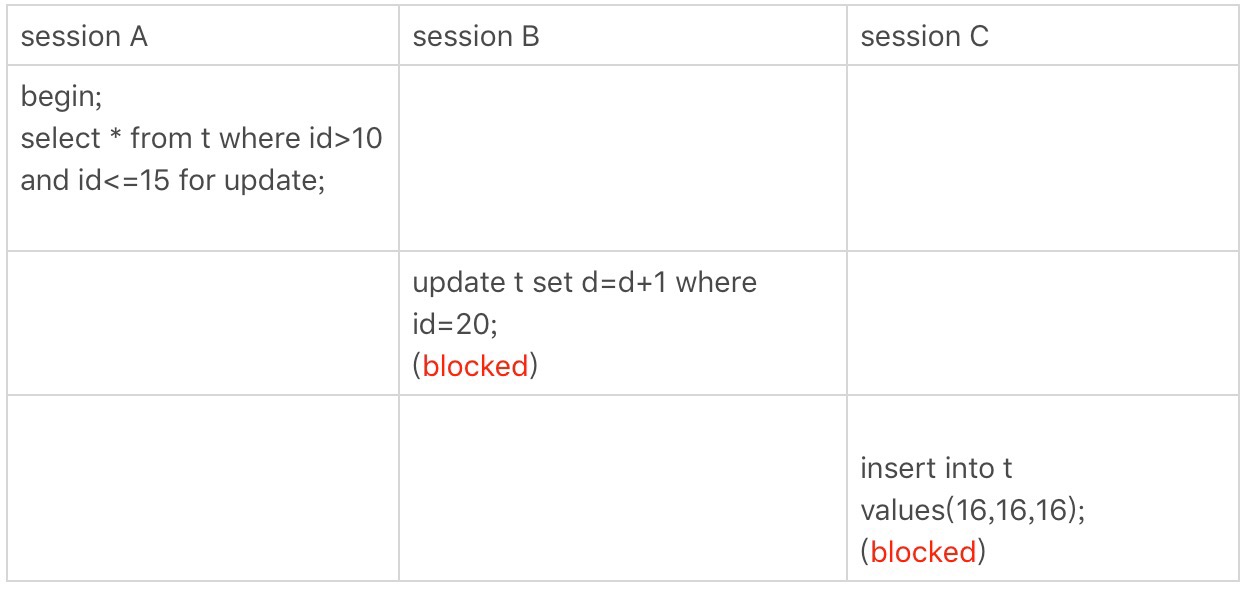
唯一索引範圍鎖的bug
Session A是一個範圍查詢,按照原則1的話,應該是索引id上只加了(10,15]這個next-key lock,並且因為id是唯一鍵,所以迴圈判斷到id=15這一行就應該停止了。但是實現上,InnoDB會往前掃描到第一個不滿足條件的行為止,也就是id=20.而且由於這個是範圍掃描,因此索引id上的(15,20]這個next-key lock也會被鎖上。
所以你看到了,Session B要更新id=20這一行的行為,其實是沒有必要的。因為掃描到了id=15,就可以確定不用往後再找了。但實現上還是這麼做了,因此認為這是一個bug。(這裡原文中丁奇老師曾與社區專家討論過,官方bug系統上也有提到過這個,但並未被verified。所以是不是bug這個事兒,如果有別的見解,歡迎提出來。)
案例六:非唯一索引上存在“等值”的例子
接下來的例子,是為了更好地說明“間隙”這個概念。這裡,我給表t插入一條新記錄。
mysql> insert into t values(30,10,30);
新插入的這一行c=10,也就是說現在表裡有兩個c=10的記錄。那麼,這時候索引c上的間隙是什麼狀態呢?你要知道,由於非唯一索引上包含了主鍵的值,所以是不可能存在“相同”的兩行的。
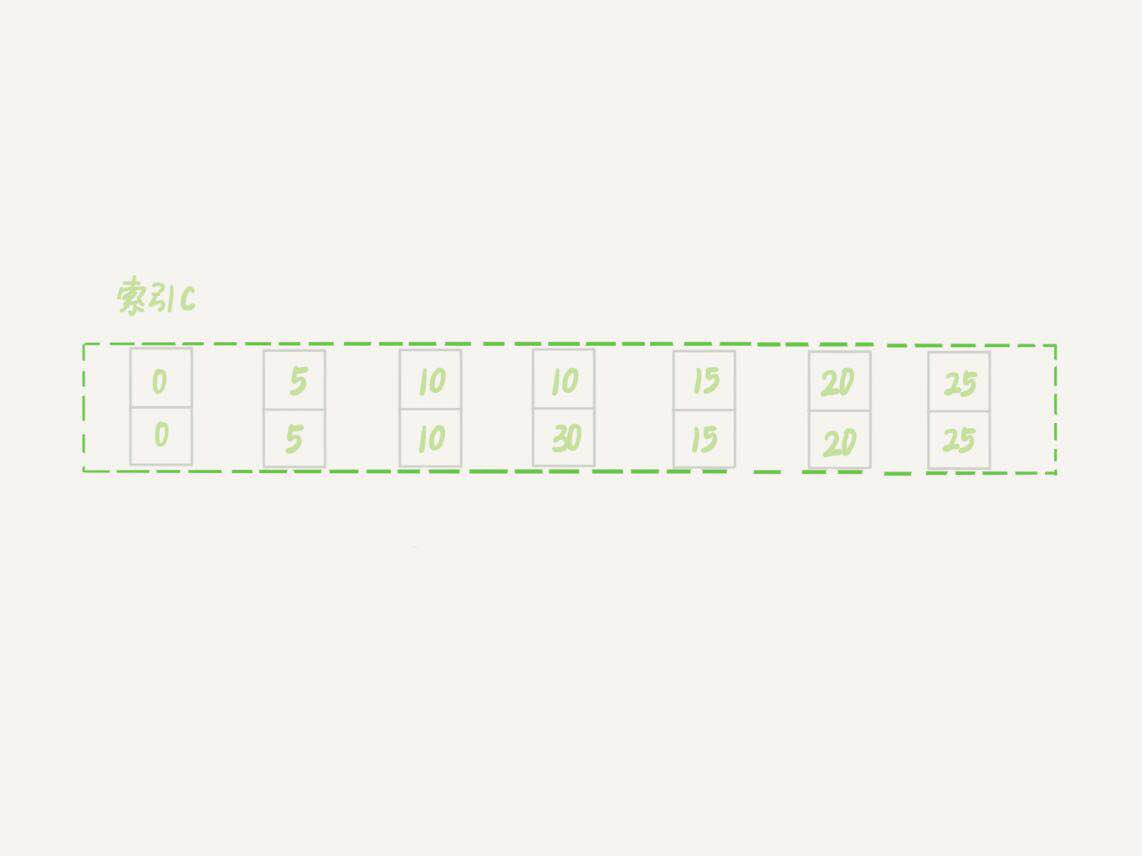
非唯一索引等值的例子
可以看到,雖然有兩個c=10,但是它們的主鍵值id是不同的(分別是10和30),因此這兩個c=10的記錄之間,也是有間隙的。圖中畫出了索引c上的主鍵id。為了跟間隙鎖的開區間形式進行區別,使用(c=10,id=30)這樣的形式,來表示索引上的一行。現在我們來驗證一下案例六。
這次我們用delete語句來驗證。註意,delete語句加鎖的邏輯是,其實跟select...for update是類似的,也就是我在文章開始總結的兩個“原則”,兩個“優化”,和一個“bug”.
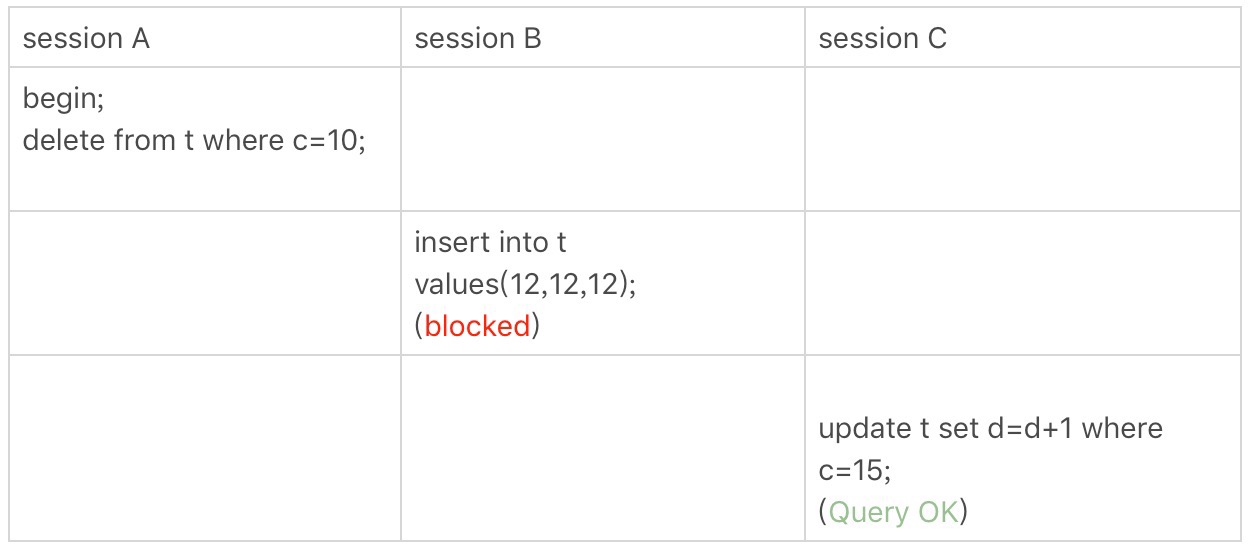
delete 示例
這時,session A在遍歷的時候,先訪問第一個c=10的記錄。同樣地,根據原則1,這裡加的是(c=15,id=15)這一行,迴圈才結束。根據優化2,這是一個等值查詢,向右查找到了不滿足條件的行,所以會退化成(c=10,id=10)到(c=15,id=15)的間隙鎖。也就是說,這個delete語句在索引c上的加鎖範圍,就是下圖中藍色區域覆蓋的部分。
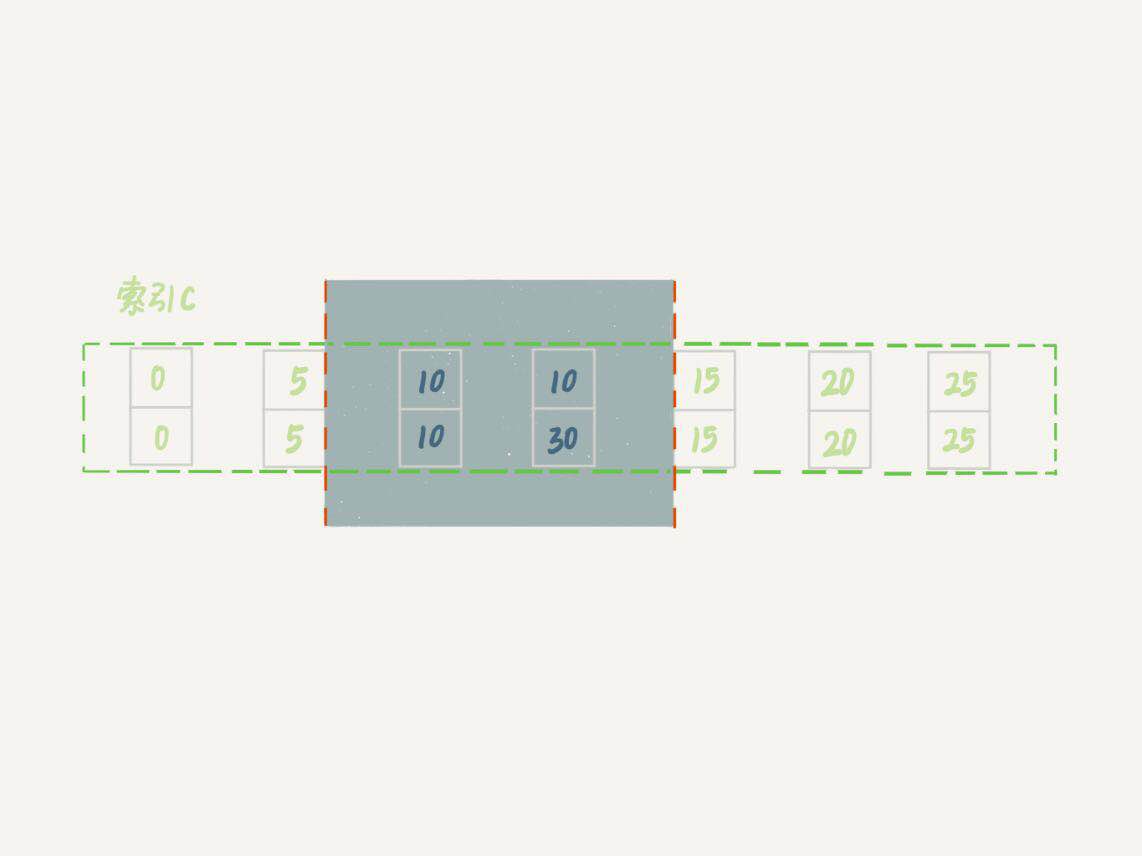
delete加鎖效果示例
這個藍色區域左右兩邊都是虛線,表示開區間,即(c=5,id=5)和(c=15,id=15)這兩行上都沒有鎖。
案例七:limit語句加鎖
例子6也有一個對照案例,場景如下所示:

limit語句加鎖
這個例子里,Session A的delete語句加了limit 2.你知道表t里c=10的記錄其實只有兩條,因此加不加limit 2,刪除效果都是一樣的,但是加鎖的效果卻不同。可以看到,session B的insert語句執行通過了,跟案例六的結果不同。這是因為,案例七里的delete語句明確加了limit 2的限制,因此在遍歷到(c=10,id=30)這一行之後,滿足條件的語句已經有兩條,就迴圈結束了。因此,索引c上加的範圍鎖就變成了從(c=5,id=5)到(c=10,id=30)這個前開後閉區間,如下圖所示。
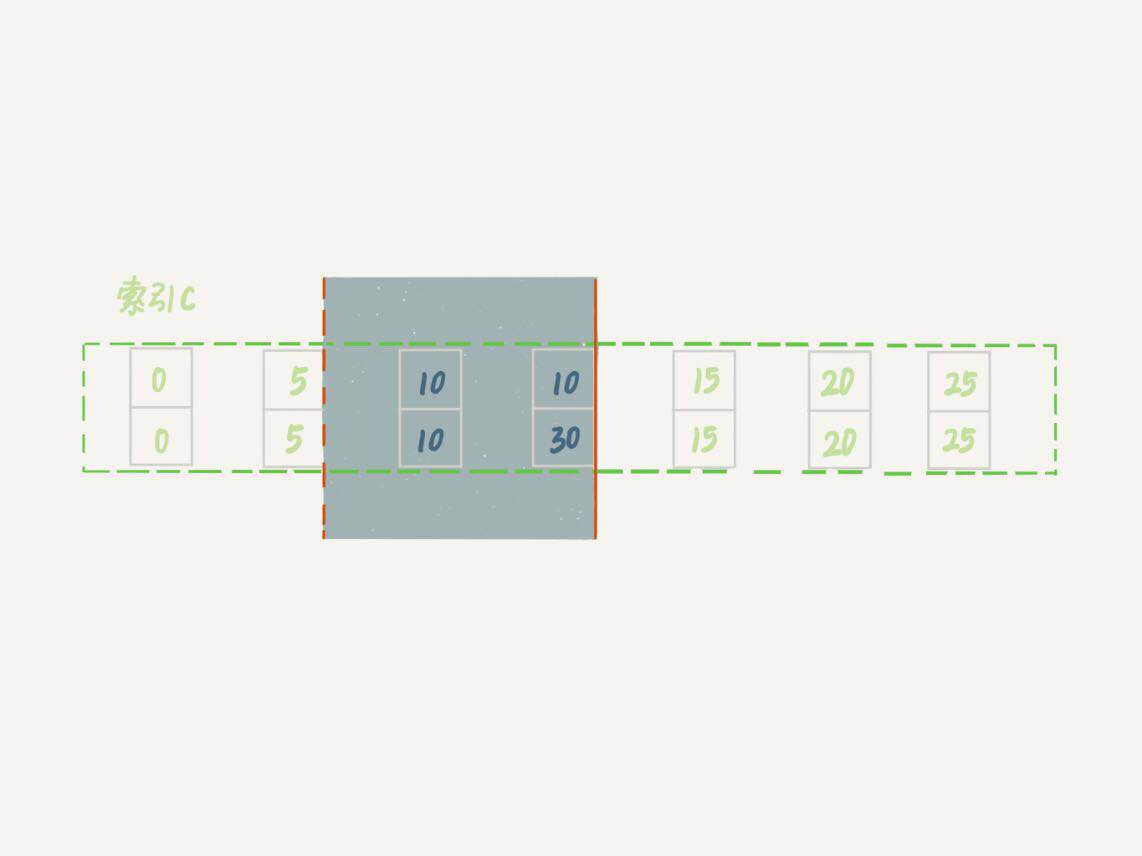
帶 limit 2的加鎖效果
可以看到,(c=10,id=30)之後的這個間隙並沒有在加鎖範圍里,因此insert語句插入c=12是可以執行成功的。這個例子對我們實踐的指導意義是,在刪除數據的時候儘量加limit 1.這樣不僅可以控制刪除數據的條數,讓操作更安全,還可以減小加鎖的範圍。
案例八:一個死鎖的例子
前面的例子中,我們在分析的時候,是按照next-key lock的邏輯來分析的,因為這樣分析比較方便。最後我們再看一個案例,目的是說明:next-key lock實際上是間隙鎖和行鎖加起來的結果。你一定會疑惑,這個概念不是一開始就說了嗎?不要著急,我們先倆看看下麵這個例子:

案例八的操作序列
現在,我們按時間順序來分析一下為什麼是這樣的結果。
- Session A啟動事務後執行查詢語句加lock in share mode,在索引c上加了next-key lock(5,10]和間隙鎖(10,15);
- Session B的udpate語句也要在索引c上加next-key lock(5,10]進入鎖等待;
- 然後Session A要再插入(8,8,8)這一行記錄,被Session B的間隙鎖鎖住。由於出現了死鎖,InnoDB讓Session B回滾。
你可能會問,Session B的next-key lock不是還沒申請成功嘛?其實是這樣的,Session B的“加next-key lock(5,10]“操作,實際上分成了兩步,先是加(5,10)的間隙鎖,加鎖成功;然後加c=10的行鎖,這時候才被鎖住的。也就是說,我們在分析加鎖規則的時候可以用next-key lock來分析。但是要知道,具體執行的時候,是要分成間隙鎖和行鎖兩段來執行的。
再次重申一下,以上的例子都是在可重覆讀隔離級別(repeatable-read)下驗證的,在這個隔離級別下遵守兩階段鎖協議,所有加鎖的資源,都是在事務提交或者回滾的時候才釋放的。
如果小伙伴們想要重現上面的例子可以搜一下具體的流程,我再重現的時候遇到了幾個小坑,希望大家可以避免。(Mysql 5.7.23)
1. 資料庫的隔離級別要是 RR(可重覆讀) 才行。
2. 要關閉Mysql的自動提交。
3. 不要使用Workbench這些工具,一般情況下即使你開多個page也是在同一個session中執行的。
4. 可以多開幾個控制台來模擬不同的Session。
5. 使用start transaction with consistent snapshot;

