
01 內容大綱 1. 基礎數據類型的補充 2. 數據類型之間的轉換 3. 編碼的進階 02 具體內容: 數據類型的補充: str 元組 列表 字典 數據類型的轉換 int bool str 三者轉換 str list 兩者轉換 list set 兩者轉換 str bytes 兩者轉換 所有數據都可以 ...
01 內容大綱
- 基礎數據類型的補充
- 數據類型之間的轉換
- 編碼的進階
02 具體內容:
數據類型的補充:
str
# str :補充的方法練習一遍就行。 s1 = 'taiBAi' # capitalize 首字母大寫,其餘變小寫 print(s1.capitalize()) # swapcase 大小寫翻轉 print(s1.swapcase()) # title 每個單詞的首字母大寫 msg= 'taibai say3hi' print(msg.title()) s1 = 'barry' # center 居中:內同居中,總長度,空白處填充 print(s1.center(20)) print(s1.center(20,'*')) ##尋找字元串中的元素是否存在 # find :通過元素找索引,找到第一個就返回,找不到 返回-1 # index:通過元素找索引,找到第一個就返回,找不到 報錯 print(s1.find('a')) print(s1.find('r')) print(s1.find('o')) print(s1.index('o'))元組
# tuple 元組中如果只有一個元素,並且沒有逗號,那麼它不是元組,它與該元素的數據類型一致。 ***【重點】 tu1 = (2,3,4) tu1 = (2) tu1 = ('太白') tu1 = ([1,2,3]) tu1 = (1,) print(tu1,type(tu1)) # # count 計數 獲取某元素在列表中出現的次數 tu = (1,2,3,3,3,2,2,3,) print(tu.count(3)) # # index 通過元素找索引(可切片),找到第一個元素就返回,找不到該元素即報錯。 tu = ('太白', '日天', '太白') print(tu.index('太白'))列表
# count 統計某個元素在列表中出現的次數 a = ["q","w","q","r","t","y"] print(a.count("q")) # index l1 = ['太白', '123', '女神', '大壯'] print(l1.index('大壯')) # sort **【重點】用於在原位置對列表進行排序 l1 = [5, 4, 3, 7, 8, 6, 1, 9] l1.sort() # 預設從小到大排序 l1.sort(reverse=True) # 從大到小排序 ** # reverse **【重點】將列表中的元素反向存放 l1.reverse() # 反轉 print(l1) # 列表可以相加 l1 = [1, 2, 3] l2 = [1, 2, 3, '太白', '123', '女神'] print(l1 + l2) # 列表與數字相乘 l1 = [1, 'daf', 3] l2 = l1*3 print(l2) 迴圈列表,改變列表大小的問題: l1 = [11, 22, 33, 44, 55] # 索引為奇數對應的元素刪除(不能一個一個刪除,此l1只是舉個例子,裡面的元素不定)。 # *** 重要 # 正常思路: # 先將所有的索引整齣來。 # # 加以判斷,index % 2 == 1: pop(index) # for index in range(len(l1)): # if index % 2 == 1: # l1.pop(index) # print(l1) ## 最簡單的: l1 = [11, 22, 33, 44, 55] del l1[1::2] #切片步長刪除 print(l1) ## 倒序法刪除元素 l1 = [11, 22, 33, 44, 55] for index in range(len(l1)-1,-1,-1): if index % 2 == 1: l1.pop(index) print(l1) # 思維置換:把索引為偶數的元素添加到一個新列表,在賦值給原列表 l1 = [11, 22, 33, 44, 55] new_l1 = [] for index in range(len(l1)): if index % 2 ==0: new_l1.append(l1[index]) l1 = new_l1 print(l1) #註意: 迴圈一個列表的時,最好不要改變列表的大小,這樣會影響你的最終的結果。字典
# 字典的補充: # update *** dic = {'name': '太白', 'age': 18} #增: dic.update(hobby='運動', hight='175') #改: dic.update(name='太白金星') ## 面試會考 dic.update([(1, 'a'),(2, 'b'),(3, 'c'),(4, 'd')]) print(dic) # 更新,有則覆蓋,無則添加 dic1 = {"name":"jin","age":18,"sex":"male"} dic2 = {"name":"alex","weight":75} dic1.update(dic2) print(dic1) # {'name': 'alex', 'age': 18, 'sex': 'male', 'weight': 75} print(dic2) # fromkeys 創建一個字典:字典的所有鍵來自一個可迭代對象,字典的值使用同一個值 dic = dict.fromkeys('abc', 100) dic = dict.fromkeys([1, 2, 3], 'alex') # 坑:值共用一個,面試題 dic = dict.fromkeys([1,2,3],[]) dic[1].append(666) print(dic) 迴圈字典,改變字典大小的問題: dic = {'k1': '太白', 'k2': 'barry', 'k3': '白白', 'age': 18} # 將字典中鍵含有'k'元素的鍵值對刪除。 #錯誤做法: # for key in dic: # if 'k' in key: # dic.pop(key) # print(dic) # 迴圈一個字典時,如果改變這個字典的大小,就會報錯。--->迴圈一個列表,然後對字典進行修改 #1: l1 = [] for key in dic: if 'k' in key: l1.append(key) print(l1) for i in l1: dic.pop(i) print(dic) #2: for key in list(dic.keys()): # ['k1', 'k2', 'k3','age'] if 'k' in key: dic.pop(key) print(dic)
數據類型的轉換
int bool str 三者轉換
str list 兩者轉換
# str ---> list s1 = 'alex 太白 武大' print(s1.split()) # ['alex', '太白', '武大'] # list ---> str # 前提 list 裡面所有的元素必須是字元串類型才可以 l1 = ['alex', '太白', '武大'] print(' '.join(l1)) # 'alex 太白 武大'
list set 兩者轉換
# list ---> set s1 = [1, 2, 3] print(set(s1)) # set ---> list set1 = {1, 2, 3, 3,} print(list(set1)) # [1, 2, 3]
str bytes 兩者轉換
# str ---> bytes s1 = '太白' print(s1.encode('utf-8')) # b'\xe5\xa4\xaa\xe7\x99\xbd' # bytes ---> str b = b'\xe5\xa4\xaa\xe7\x99\xbd' print(b.decode('utf-8')) # '太白'
所有數據都可以轉化成bool值
轉化成bool值為False的數據類型有:'', 0, (), {}, [], set(), None
數據類型的分類(瞭解)

編碼的進階
- ASCII碼:包含英文字母,數字,特殊字元與01010101對應關係。
a 01000001 一個字元一個位元組表示。
- GBK:只包含本國文字(以及英文字母,數字,特殊字元)與0101010對應關係。
a 01000001 ascii碼中的字元:一個字元一個位元組表示。
中 01001001 01000010 中文:一個字元兩個位元組表示。
- Unicode:包含全世界所有的文字與二進位0101001的對應關係。
a 01000001 01000010 01000011 00000001
b 01000001 01000010 01100011 00000001
中 01001001 01000010 01100011 00000001
- UTF-8:包含全世界所有的文字與二進位0101001的對應關係(最少用8位一個位元組表示一個字元)。
a 01000001 ascii碼中的字元:一個字元一個位元組表示。
To 01000001 01000010 (歐洲文字:葡萄牙,西班牙等)一個字元兩個位元組表示。
中 01001001 01000010 01100011 亞洲文字;一個字元三個位元組表示。
- 所有編版本(Unicode除外)不能直接互相識別。(不同編碼之間,不能直接互相識別。**)
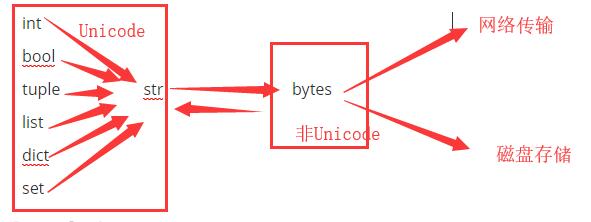
- 數據在記憶體中全部是以Unicode編碼的,但是當你的數據用於網路傳輸或者存儲到硬碟中,必須是以非Unicode編碼(utf-8,gbk等等)。
- 在記憶體中所有數據類型(除bytes類型外)都是Unicode 編碼方式,bytes 是非Unicode編碼方式。
- bytes類型 只能與str 類型互相轉化,不能與其他數據類型轉化。
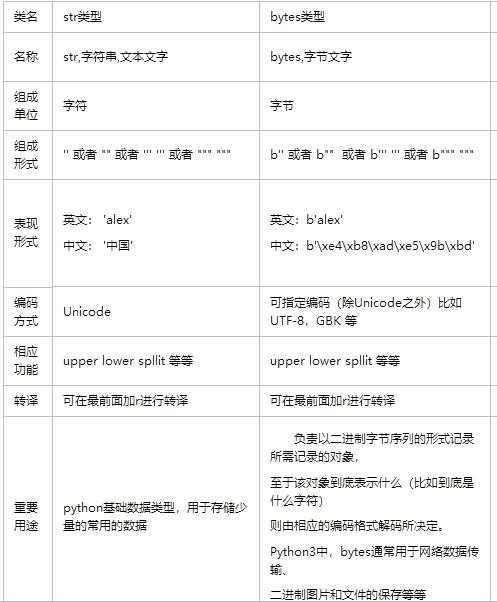
英文:
str: 'hello '
記憶體中的編碼方式: Unicode
表現形式: 'hello'
bytes :
記憶體中的編碼方式: 非Unicode
表現形式:b'hello'
中文:
str:
記憶體中的編碼方式: Unicode
表現形式:'中國'
bytes :
記憶體中的編碼方式: 非Unicode # Utf-8
表現形式:b'\xe4\xb8\xad\xe5\x9b\xbd'
註意:bytes類型也是Python基礎數據類型之一。bytes是非unicode編碼的數據類型,除此之外,python中所有數據類型的編碼均為unicode編碼。
bytes類型也稱作位元組文本,他的主要用途就是網路的數據傳輸,與數據存儲。

# str ---> bytes (Unicode ---> 非Unicode)
s1 = '中國'
b1 = s1.encode('utf-8') # 編碼
print(b1,type(b1)) # b'\xe4\xb8\xad\xe5\x9b\xbd'
b1 = s1.encode('gbk') # 編碼 # b'\xd6\xd0\xb9\xfa' <class 'bytes'>
# bytes---->str (非Unicode ---> Unicode)
b1 = b'\xe4\xb8\xad\xe5\x9b\xbd'
s2 = b1.decode('utf-8') # 解碼
print(s2)
# gbk ---> utf-8
b1 = b'\xd6\xd0\xb9\xfa'
s = b1.decode('gbk')
print(s)
b2 = s.encode('utf-8')
print(b2) # b'\xe4\xb8\xad\xe5\x9b\xbd'
# utf-8 ---> gbk
b1 = b'\xe4\xb8\xad\xe5\x9b\xbd'
s = b1.decode('utf-8')
print(s)#中國
b2 = s.encode('gbk')
print(b2) # b'\xd6\xd0\xb9\xfa'
03 總結
- 數據類型的補充: list(sort,revrse,列表的相加,乘,迴圈問題),dict (update 迴圈問題) 【重點】***
- 編碼的進階:
- bytes為什麼存在?
- str --->bytes
- gbk <-----> utf-8


