1 hadoop概述 1.1 為什麼會有大數據處理 1 hadoop概述 1.1 為什麼會有大數據處理 傳統模式已經滿足不了大數據的增長 1)存儲問題 傳統資料庫:存儲億級別的數據,需要高性能的伺服器;並且解決不了本質問題;只能存結構化數據 大數據存儲:通過分散式存儲,將數據存到一臺機器的同時,還可 ...
1 hadoop概述
1.1 為什麼會有大數據處理
傳統模式已經滿足不了大數據的增長 1)存儲問題
- 傳統資料庫:存儲億級別的數據,需要高性能的伺服器;並且解決不了本質問題;只能存結構化數據
- 大數據存儲:通過分散式存儲,將數據存到一臺機器的同時,還可以備份到其他機器上,這樣當某台機器掛掉了或磁碟壞掉了,在其他機器上可以拿到該數據,數據不會丟失(可備份)
- 磁碟不夠掛磁碟,機器不夠加機器(可橫行擴展)
- 傳統資料庫: 當資料庫存儲億級別的數據後,查詢效率也下降的很快,查詢不能秒級返回
- 大數據分析:分散式計算。也可以橫行擴展

1.2 什麼是hadoop?
Hadoop項目是以可靠、可擴展和分散式計算為目的而發展的開源軟體 Hadoop 是Apache的頂級項目 Apache:APACHE軟體基金會,支持Apache的開源軟體社區項目,為公眾提供好的軟體產品 項目主頁:http://hadoop.apache.org
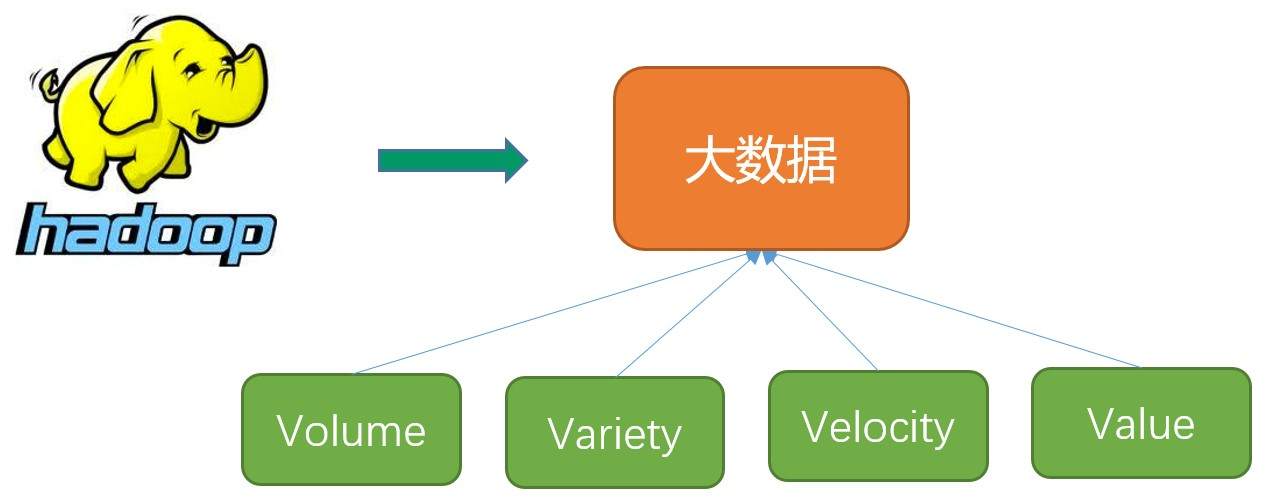
大數據的主要特點(4V)
- 數據容量大(Volume)。從TB級別,躍升到PB級別
- 數據類型繁多(Variety)。包括網路日誌、音頻、視頻、圖片、地理位置信息等,這些多類型的數據對數據的處理能力提出了更高要求
- 商業價值高(Value)。客戶群體細分,提供定製化服務;發掘新的需求同時提高投資的回報率;降低服務成本
- 處理速度快(Velocity)。這是大數據區分於傳統數據挖掘的最顯著特征。預計到2020年,全球數據使用量將達到35.2ZB。在如此海量的數據面前,處理數據的效率就是企業的生命

hadoop核心組件 用於解決兩個核心問題:存儲和計算 核心組件 1)Hadoop Common:一組分散式文件系統和通用I/O的組件與介面(序列化、Java RPC和持久化數據結構) 2)Hadoop Distributed FileSystem(Hadoop分散式文件系統HDFS) 分散式存儲, 有備份, 可擴展 3)Hadoop MapReduce(分散式計算框架) 分散式計算,多台機器同時計算一部分,得到部分結果,再將部分結果彙總,得到總體的結果(可擴展) 4)Hadoop YARN(分散式資源管理器) MapReduce任務計算的時候,運行在yarn上,yarn提供資源
hadoop的框架演變
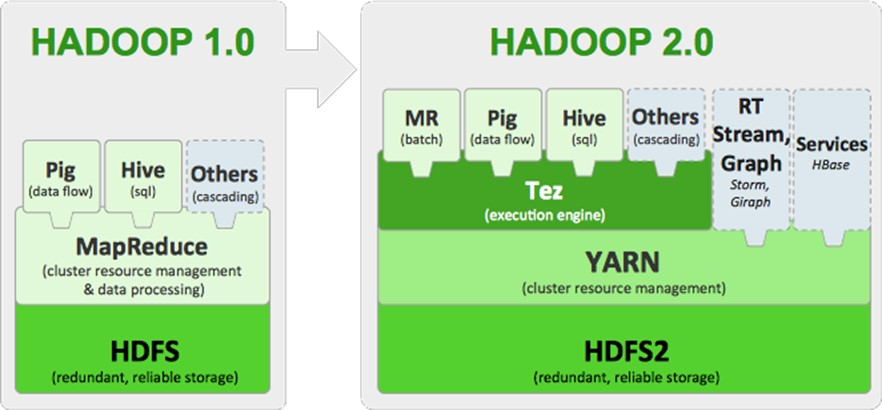
Hadoop1.0 的 MapReduce(MR1):集資源管理和任務調用、計算功能綁在一起,擴展性較差,不支持多計算框架
Hadoop2.0 的Yarn(MRv2):將資源管理和任務調用兩個功能分開,提高擴展性,並支持多計算框架 hadoop生態圈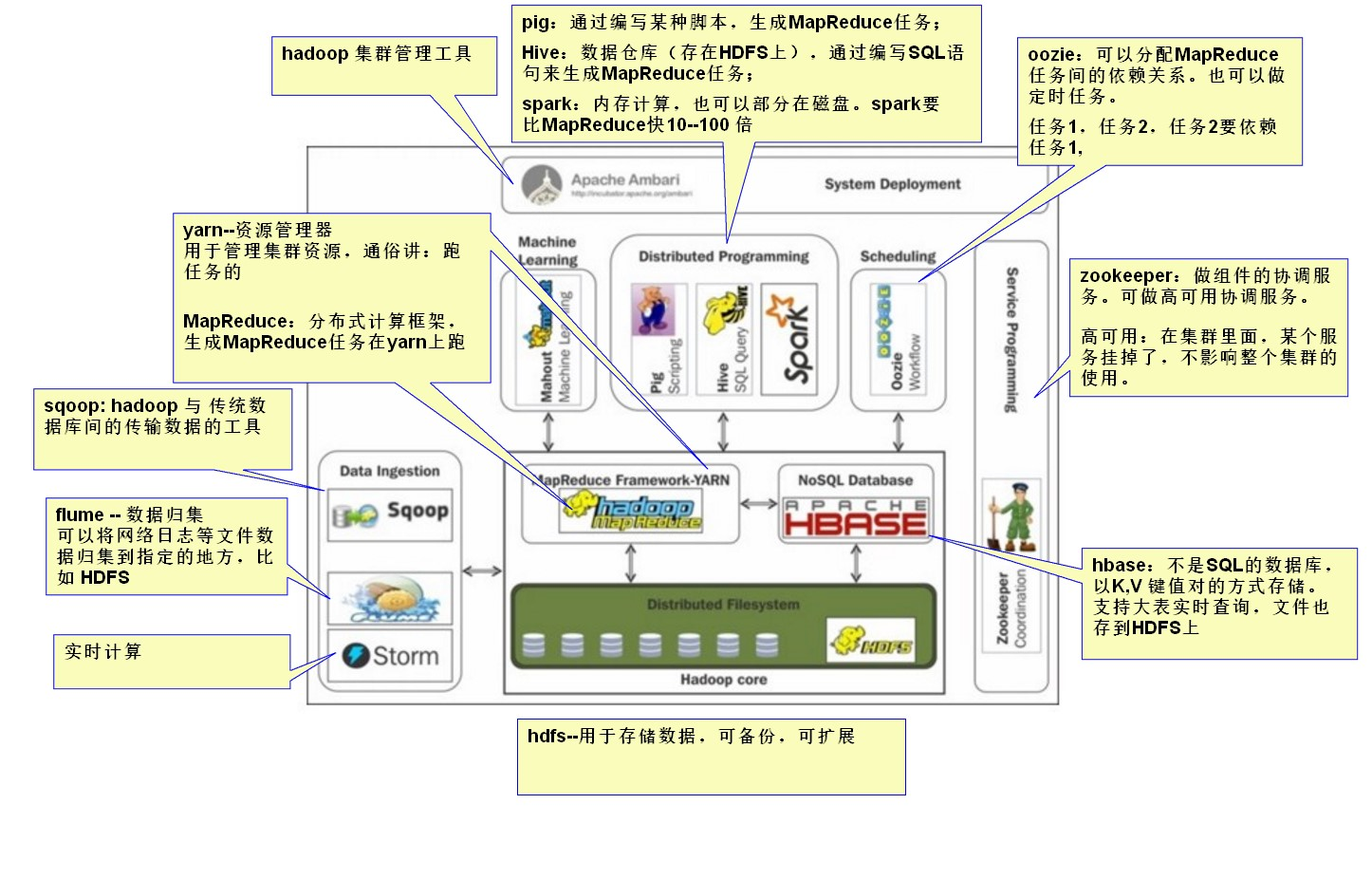

1)HDFS(Hadoop分散式文件系統) HDFS是一種數據分散式保存機制,數據被保存在電腦集群上。數據寫入一次,讀取多次。HDFS 為hive、HBase等工具提供了基礎 2)MapReduce(分散式計算框架) MapReduce是一種分散式計算模型,用以進行大數據量的計算,是一種離線計算框架 這個 MapReduce 的計算過程簡而言之,就是將大數據集分解為成若幹個小數據集,每個(或若幹個)數據集分別由集群中的一個結點(一般就是一臺主機)進行處理並生成中間結果,然後將每個結點的中間結果進行合併, 形成最終結果 3)HBASE(分散式列存資料庫) HBase是一個建立在HDFS之上,面向列的NoSQL資料庫,用於快速讀/寫大量數據。HBase使用Zookeeper進行管理,確保所有組件都正常運行
4)Sqoop(數據ETL/同步工具) Sqoop是SQL-to-Hadoop的縮寫,主要用於傳統資料庫和Hadoop之間傳輸數據 5)flume(分散式日誌收集系統) Flume是一個分散式、可靠、和高可用的海量日誌聚合的系統,如日誌數據從各種網站伺服器上彙集起來存儲到HDFS,HBase等集中存儲器中 6)Storm(流示計算、實時計算) Storm是一個免費開源、分散式、高容錯的實時計算系統。Storm令持續不斷的流計算變得容易,彌補了Hadoop批處理所不能滿足的實時要求。Storm經常用於在實時分析、線上機器學習、持續計算、分散式遠程調用和ETL等領域 7)Zookeeper(分散式協作服務) Hadoop的許多組件依賴於Zookeeper,它運行在電腦集群上面,用於管理Hadoop操作 作用:解決分散式環境下的數據管理問題:統一命名,狀態同步,集群管理,配置同步等 8)Pig(ad-hoc腳本) Pig定義了一種數據流語言—Pig Latin,它是MapReduce編程的複雜性的抽象,Pig平臺包括運行環境和用於分析Hadoop數據集的腳本語言(Pig Latin) 其編譯器將Pig Latin 翻譯成MapReduce 程式序列將腳本轉換為MapReduce任務在Hadoop上執行。通常用於進行離線分析 9)Hive(數據倉庫) Hive定義了一種類似SQL的查詢語言(HQL),將SQL轉化為MapReduce任務在Hadoop上執行。通常用於離線分析 HQL用於運行存儲在Hadoop上的查詢語句,Hive讓不熟悉MapReduce開發人員也能編寫數據查詢語句,然後這些語句被翻譯為Hadoop上面的MapReduce任務 10)Spark(記憶體計算模型) Spark提供了一個更快、更通用的數據處理平臺。和Hadoop相比,Spark可以讓你的程式在記憶體中運行時速度提升100倍,或者在磁碟上運行時速度提升10倍。 11)Oozie(工作流調度器) Oozi可以把多個Map/Reduce作業組合到一個邏輯工作單元中,從而完成更大型的任務
12)Mahout(數據挖掘演算法庫) Mahout的主要目標是創建一些可擴展的機器學習領域經典演算法的實現,旨在幫助開發人員更加方便快捷地創建智能應用程式 13)Hadoop YARN(分散式資源管理器) YARN是下一代MapReduce,即MRv2,是在第一代MapReduce基礎上演變而來的,主要是為瞭解決原始Hadoop擴展性較差,不支持多計算框架而提出的 其核心思想: 將MR1中JobTracker的資源管理和作業調用兩個功能分開,分別由ResourceManager和ApplicationMaster進程來實現 1)ResourceManager:負責整個集群的資源管理和調度 2)ApplicationMaster:負責應用程式相關事務,比如任務調度、任務監控和容錯等 14)Tez(DAG計算模型) 一個運行在YARN之上支持DAG(有向無環圖)作業的計算框架 Tez的目的就是幫助Hadoop處理這些MapReduce處理不了的用例場景,如機器學習 什麼是集群,集群和服務的關係。
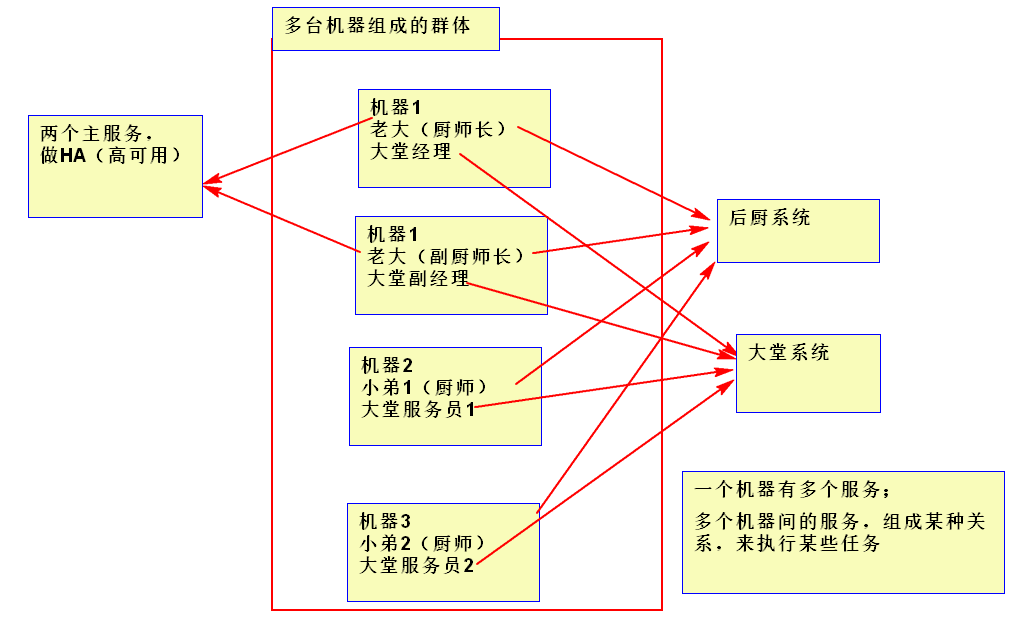
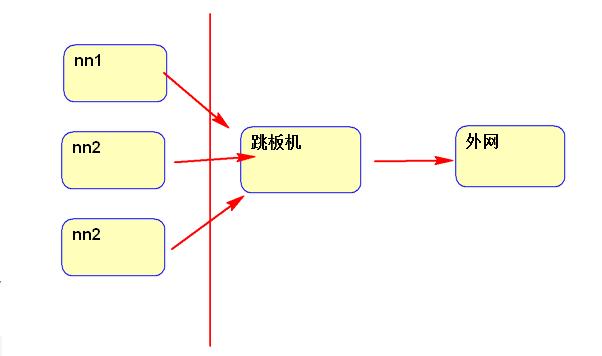
集群規劃: 一個主節點:nn1.hadoop, 一個從節點:nn2.hadoop, 三個工作節點:s1.hadoop、s2.hadoop、s3.hadoop 網路規劃: nn1.hadoop 192.168.174.160 nn2.hadoop 192.168.174.161 s1.hadoop 192.168.174.162 s2.hadoop 192.168.174.163 s3.hadoop 192.168.174.164 在企業里還應有操作機(跳板機)
2 基礎環境搭建
配置網路
1 // 查看網卡配置文件是否一致 2 vim /etc/sysconfig/network-scripts/ifcfg-ens33 3 4 // 文件配置如下: 5 TYPE="Ethernet" 6 BOOTPROTO=static 7 DEFROUTE="yes" 8 IPV4_FAILURE_FATAL="no" 9 IPV6INIT="yes" 10 IPV6_AUTOCONF="yes" 11 IPV6_DEFROUTE="yes" 12 IPV6_FAILURE_FATAL="no" 13 NAME="eno16777736" 14 UUID="cb7a79a9-8114-482b-93f0-fce73bcef88b" 15 DEVICE="eno16777736" 16 ONBOOT="yes" 17 IPADDR=192.168.142.200 18 PREFIX=24 19 GATEWAY=192.168.142.2 20 DNS1=192.168.142.2 21 DNS2=8.8.8.8 22 23 // 重啟網路 24 systemctl restart network.service 或 service network restart 25 // ping 百度,測試網路是否正常 26 ping www.baidu.com
2.1 配置阿裡雲 yum 源
1)安裝sz rz工具,用於以後用rz sz上傳下載文件
yum install -y lrzsz
2)下載 repo 文件 文件下載地址: http://mirrors.aliyun.com/repo/Centos-7.repo 3)用 rz 將下載的 Centos-7.repo 文件上傳到Linux系統的某個目錄下 4)備份並替換系統的repo文件
1 mv Centos-7.repo /etc/yum.repos.d/ 2 cd /etc/yum.repos.d/ 3 mv CentOS-Base.repo CentOS-Base.repo.bak 4 mv Centos-7.repo CentOS-Base.repo
5)執行yum源更新命令
yum clean all # 伺服器的包信息下載到本地電腦緩存起來 yum makecache yum update -y
配置完畢。
2.2 安裝常用軟體
1 yum install -y openssh-server vim gcc gcc-c++ glibc-headers bzip2-devel lzo-devel curl wget openssh-clients zlib-devel autoconf automake cmake libtool openssl-devel fuse-devel snappy-devel telnet unzip zip net-tools.x86_64 firewalld systemd
2.3 關閉防火牆
查看防火牆狀態:firewall-cmd --state 關閉防火牆:systemctl stop firewalld.service 禁止防火牆開機啟動: systemctl disable firewalld.service 查看服務是否開機啟動: systemctl is-enabled firewalld.service
2.4 關閉SELinux
查看關閉狀態 /usr/sbin/sestatus -v 關閉方法 vim /etc/selinux/config 把文件里的SELINUX=disabled
 重啟伺服器
reboot
啟動之後用
/usr/sbin/sestatus -v 查看selinux的修改狀態
重啟伺服器
reboot
啟動之後用
/usr/sbin/sestatus -v 查看selinux的修改狀態
2.5 安裝JDK
1)JDK 下載地址 地址: http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
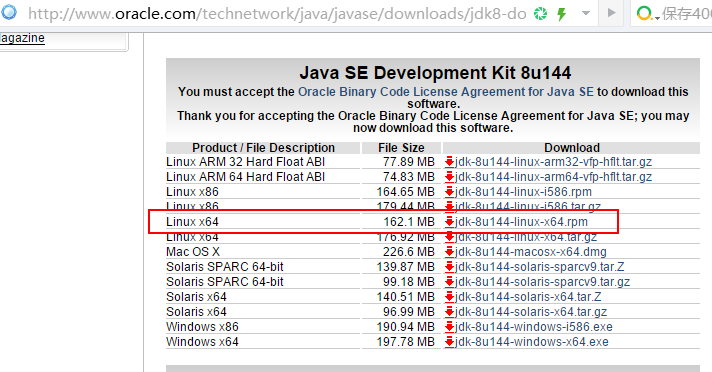
2)安裝JDK 用 rz 命令將安裝文件上傳Linux 系統 rpm -ivh jdk-8u144-linux-x64.rpm 3)配置JDK 環境變數 修改系統環境變數文件 /etc/profile,在文件尾部追加以下內容
1 export JAVA_HOME=/usr/java/jdk1.8.0_144 2 export JRE_HOME=$JAVA_HOME/jre 3 export PATH=$PATH:$JAVA_HOME/bin 4 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export 設置或顯示環境變數 用export修飾一個變數,A腳本中調用B腳本,B腳本也能拿到這個變數


4)使修改生效,並配置JDK
1 #使修改生效 2 source /etc/profile 3 #查看系統變數值 4 env | grep PATH 5 #檢查JDK 配置情況 6 env | grep JAVA_HOME
2.6 修改主安裝常用軟體主機名
1 hostnamectl set-hostname nn1.hadoop 2 #修改完後用hostname可查看當前主機名 3 hostname
2.7 創建hadoop 用戶並設置 hadoop 用戶密碼
1 #創建hadoop用戶 2 useradd hadoop 3 4 #給hadoop用戶設置密碼 5 hadoop000
2.8 給hadoop用戶,配置SSH密鑰
配置SSH密鑰的目的:使得多台機器間可以免密登錄。 實現原理: 使用ssh-keygen在linux01 上生成private和public密鑰,將生成的public密鑰拷貝到遠程機器linux02 上後,就可以使用ssh命令無需密碼登錄到另外一臺機器linux02上。如果想互相登錄,則要把公鑰私鑰都拷貝到遠程機器linux02 上。
 實現步驟:
實現步驟:
1 #切換到hadoop用戶 2 su – hadoop 3 #創建.ssh目錄 4 mkdir ~/.ssh 5 #生成ssh公私鑰 6 ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' 7 #輸出公鑰文件內容並且重新輸入到~/.ssh/authorized_keys文件中 8 cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys 9 #給~/.ssh文件加上700許可權 10 chmod 700 ~/.ssh 11 #給~/.ssh/authorized_keys加上600許可權 12 chmod 600 ~/.ssh/authorized_keys
2.9 禁止非 whell 組用戶切換到root,配置免密切換root
通常情況下,一般用戶通過執行“su -”命令、輸入正確的root密碼,可以登錄為root用戶來對系統進行管理員級別的配置。 但是,為了更進一步加強系統的安全性,有必要建立一個管理員的組,只允許這個組的用戶來執行 “su -” 命令登錄為 root 用戶,而讓其他組的用戶即使執行 “su -” 、輸入了正確的 root 密碼,也無法登錄為 root 用戶。在UNIX和Linux下,這個組的名稱通常為 “wheel” 。 回到root用戶 1)修改/etc/pam.d/su配置 su 時要求用戶加入到wheel組 修改/etc/pam.d/su文件,將“#auth required pam_wheel.so”替換成“auth required pam_wheel.so” 修改/etc/pam.d/su文件,將“#auth sufficient pam_wheel.so”替換成“auth sufficient pam_wheel.so”
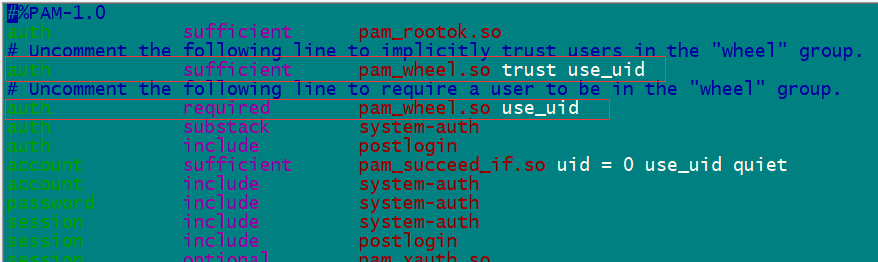
2)修改/etc/login.defs文件 只有wheel組可以su 到root cp /etc/login.defs /etc/login.defs_back 先做個備份 tail /etc/login.defs 從文件底部查看
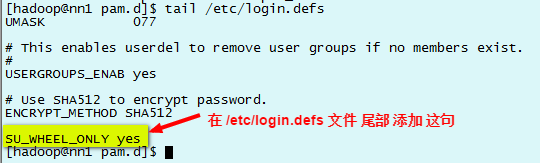
3) 添加用戶到管理員,禁止普通用戶su 到 root
1 #把hadoop用戶加到wheel組裡 2 [root@nn1 ~]# gpasswd -a hadoop wheel 3 #查看wheel組裡是否有hadoop用戶 4 [root@nn1 ~]# cat /etc/group | grep wheel
4)用 hadoop 用戶驗證一下,由於 hadoop 沒有在wheel 組裡,所以沒有 su - root 許可權。
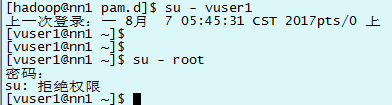
5)修改/etc/pam.d/su文件(上面已經配好) 將字元串“#auth sufficient pam_wheel.so”替換成“auth sufficient pam_wheel.so”

2.10 配置hosts 文件
在克隆機器前,配置nn1 機器的 /etc/hosts 文件,文件內需要配置nn1、nn2、s1、s2、s3 所有機器的IP 和 主機名。
修改/etc/hosts文件,追加以下內容。vim /etc/hosts1 192.168.174.160 nn1.hadoop 2 192.168.174.161 nn2.hadoop 3 192.168.174.162 s1.hadoop 4 192.168.174.163 s2.hadoop 5 192.168.174.164 s3.hadoop
2.11 克隆4台機器
執行完上面的命令,一個基礎的linux系統就配置好了。然後再根據這個虛擬機克隆出 4個linux系統
其中:nn2.hadoop: 從節點
s1.hadoop、s2.hadoop、s3.hadoop:三個工作節點
並用hadoop用戶,測試彼此之間是否能進行ssh通信
1) 虛擬機克隆右鍵 nn1 機器→ 管理 → 克隆。
克隆完成後,需要給克隆的虛擬機配置靜態IP。
2)配置靜態IP1)查看網卡硬體名稱和基本信息 ip add
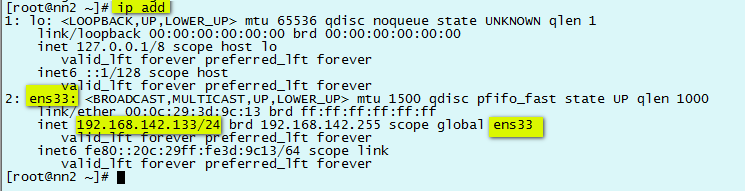
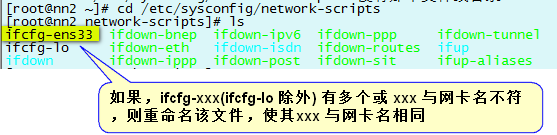 vim ifcfg-ens33
service network restart
ifcfg-xxx 中的xxx 與網卡名相同後,配置ifcfg-xxx 文件
vim ifcfg-ens33
service network restart
ifcfg-xxx 中的xxx 與網卡名相同後,配置ifcfg-xxx 文件
1 TYPE="Ethernet" 2 BOOTPROTO="static" 3 DEFROUTE="yes" 4 PEERDNS="yes" 5 PEERROUTES="yes" 6 IPV4_FAILURE_FATAL="no" 7 IPV6INIT="yes" 8 IPV6_AUTOCONF="yes" 9 IPV6_DEFROUTE="yes" 10 IPV6_PEERDNS="yes" 11 IPV6_PEERROUTES="yes" 12 IPV6_FAILURE_FATAL="no" 13 NAME="ens33" 14 UUID="d15377eb-6ffa-44c9-a06d-f7eb00f49f44" 15 DEVICE="ens33" 16 ONBOOT="yes" 17 IPADDR=192.168.142.133 18 PREFIX=24 19 GATEWAY=192.168.142.2 20 DNS1=192.168.142.2 21 DNS2=8.8.8.8
需要修改的內容,配置完的網卡文件
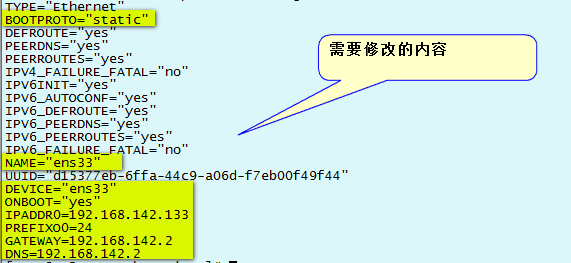
配置完後,用systemctl restart network.service重啟網路服務,當前的ssh就連接不上了,是因為網路IP被改變成你自己設置的靜態IP。 用 ip add 查看網卡信息 用 ping www.baidu.com 看是否能連接外網。
1 hostnamectl set-hostname nn1.hadoop 2 #修改完後用hostname可查看當前主機名 3 hostname
如果上不了網執行以下操作 3)配置 /etc/resolv.conf 的 nameserver cat /etc/resolv.conf 查看nameserver是否被設置正確
 vim /etc/resolv.conf 修改文件,如果不存在nameserver就在文件下麵添加,如果存在就修改,把nameserver 設置成自己對應的DNS。
4)停止掉NetworkManager服務
五台一起執行
vim /etc/resolv.conf 修改文件,如果不存在nameserver就在文件下麵添加,如果存在就修改,把nameserver 設置成自己對應的DNS。
4)停止掉NetworkManager服務
五台一起執行
1 // 停止NetworkManager服務 2 systemctl stop NetworkManager.service 3 // 並設置成開機不啟動 4 systemctl disable NetworkManager.service 5 // 之後重啟網路服務 6 systemctl restart network.service
5)修改每個機器的主機名
1 hostnamectl set-hostname nn2.hadoop 2 hostnamectl set-hostname s1.hadoop 3 hostnamectl set-hostname s2.hadoop 4 hostnamectl set-hostname s3.hadoop
3 批量腳本說明及使用
3.1 批量腳本說明
執行腳本要給腳本加上可執行許可權
1 chmod -R +x ~/hadoop_op
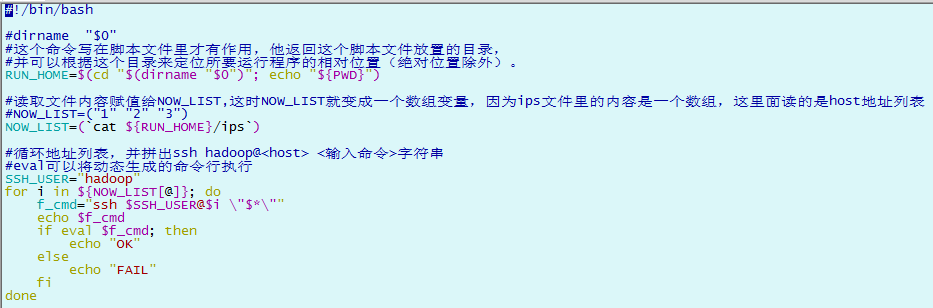
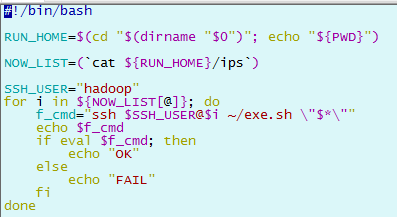
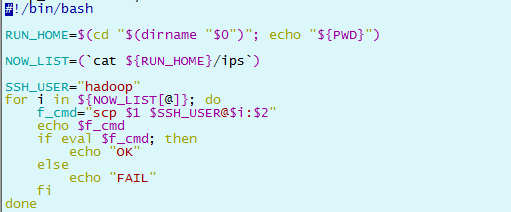
exe.sh : 執行su 命令,與ssh_root.sh 配套使用 ips :用於存放要操作的主機列表,用回車或空格隔開 scp_all.sh :用hadoop用戶拷貝當前機器的文件到其他操作機 ssh_all.sh :用hadoop 用戶可登陸其他操作機執行相應操作 ssh_root.sh : 用hadoop 用戶登錄其他操作機,並su 到 root 用戶,以root 用戶執行相應操作,與exe.sh 配套使用 1)ips

2)ssh_all.sh
3)ssh_root.sh
4)exe.sh

5)scp_all.sh
3.2 批量腳本的使用
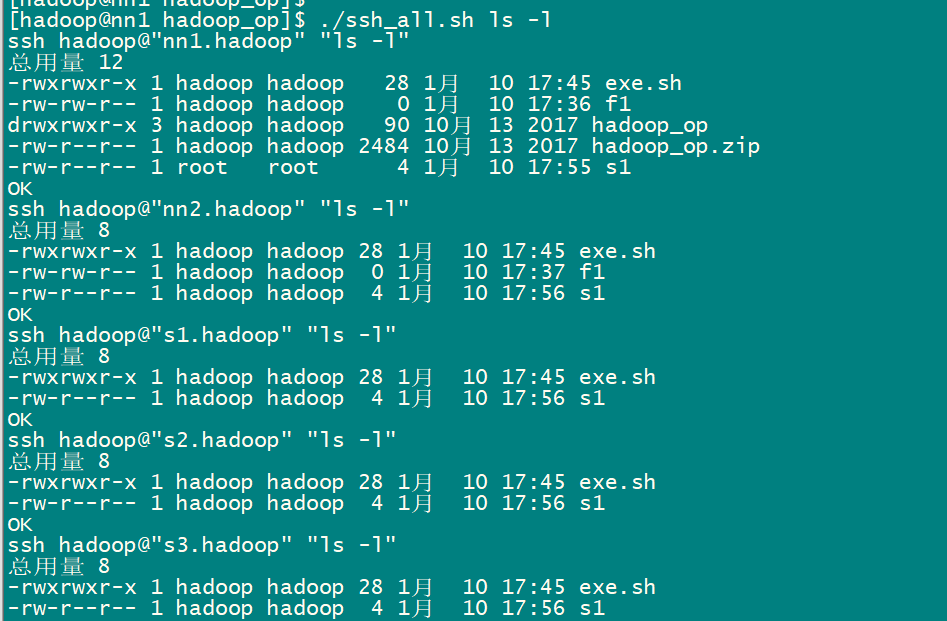
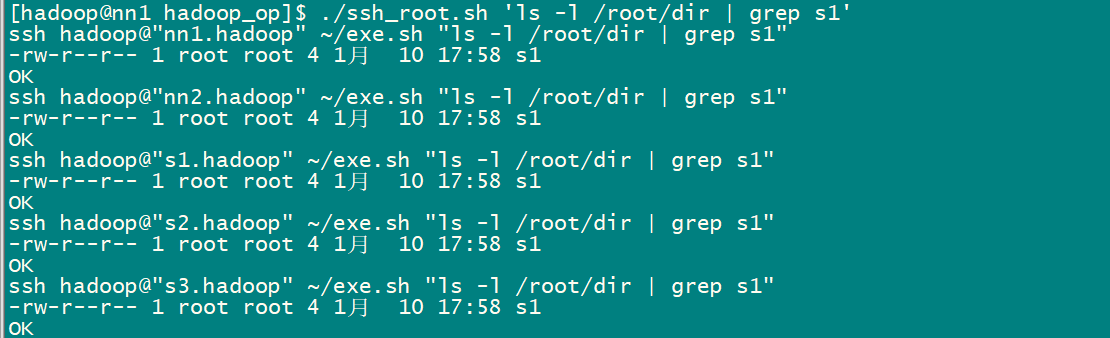
1)將批量腳本上傳到機器上 把hadoop_op.zip文件用 rz 命令上傳到 nn1.hadoop 機器上 2)解壓批量腳本,並修改批量腳本許可權 一般先切換到當前使用用戶的home目錄下 解壓: unzip hadoop_op.zip 修改許可權:chmod -R 775 ./hadoop_op 3)測試批量SSH命令 ./ssh_all.sh hostname 4)測試批量傳文件
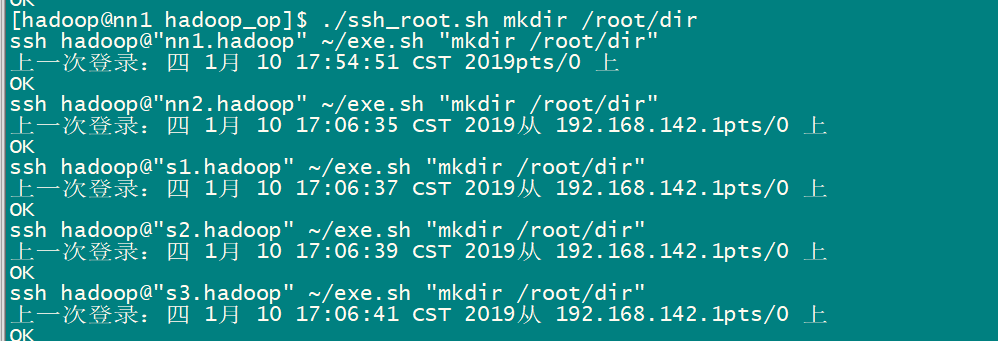
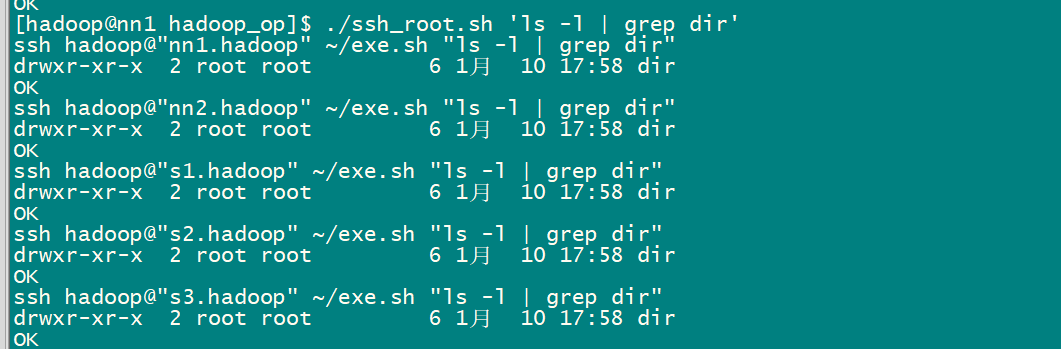
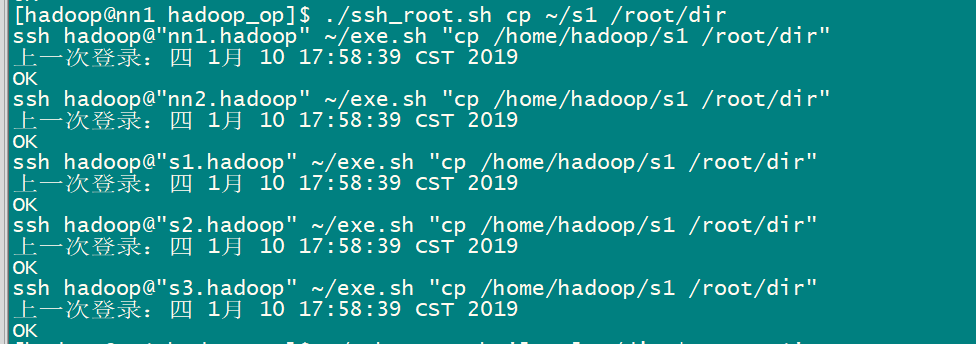
 如果想將nn1.hadoop 機器上/root下的s1 文件,分發到其他機器的/root/dir/ 目錄下,該如何操作?
1)nn1.hadoop:將/root/s1 文件拷貝到hadoop家目錄下
如果想將nn1.hadoop 機器上/root下的s1 文件,分發到其他機器的/root/dir/ 目錄下,該如何操作?
1)nn1.hadoop:將/root/s1 文件拷貝到hadoop家目錄下
2)多機分發腳本,將s1文件分發到其他機器的hadoop家目錄