
筆記記錄自林曉斌(丁奇)老師的《MySQL實戰45講》 (本篇內圖片均來自丁奇老師的講解,如有侵權,請聯繫我刪除) 20) --幻讀是什麼,幻讀有什麼問題? 我們先來看看表結構和初始化數據: 表t除主鍵id外還有一個索引c,初始化語句在表中插入了6行數據。那麼如果有下麵這樣一段語句 請問是怎麼加鎖的 ...
筆記記錄自林曉斌(丁奇)老師的《MySQL實戰45講》
(本篇內圖片均來自丁奇老師的講解,如有侵權,請聯繫我刪除)
20) --幻讀是什麼,幻讀有什麼問題?
我們先來看看表結構和初始化數據:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
表t除主鍵id外還有一個索引c,初始化語句在表中插入了6行數據。那麼如果有下麵這樣一段語句
begin; select * from t where d=5 for update; commit;
請問是怎麼加鎖的,加的鎖又是什麼時候釋放的呢?由於for update,上面的語句會在執行完成select之後加一個寫鎖,而且由於兩階段鎖協議,這個寫鎖會在執行commit語句的時候釋放。由於欄位d上沒有索引,因此這條查詢語句會做全表掃描。那麼,其他被掃描到的,但是不滿足條件的5行記錄上,會不會也被加鎖呢?我們知道,InnoDB的預設隔離級別是可重覆讀,所以本文接下來沒有特殊說明的部分,都是設定在可重覆讀隔離級別下的。
幻讀是什麼?
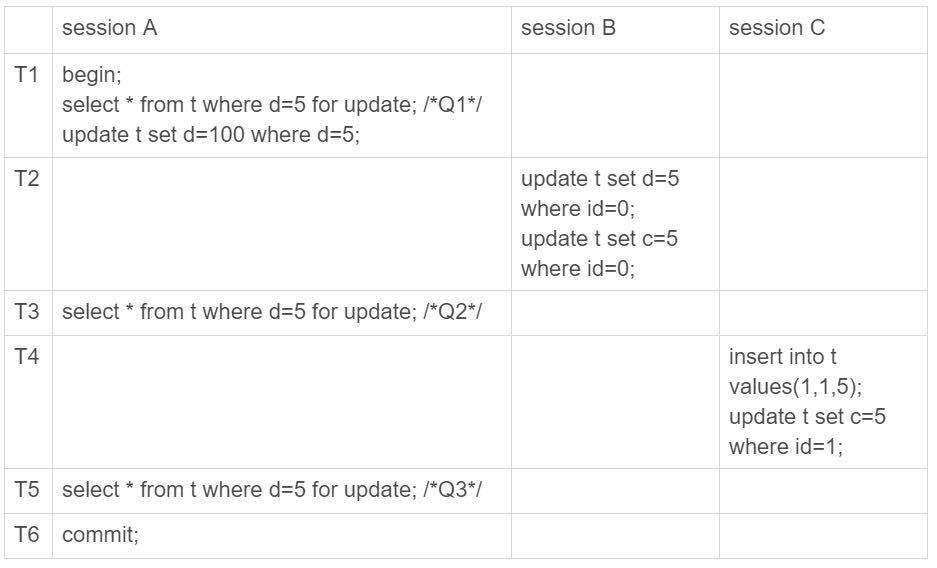
我們不妨來分析一下,如果只在d=5,也就是id=5這一行上加鎖,其他行上不加鎖,會怎麼樣。我們來看一下這種情況的場景,註意,這裡是符合剛纔假設的,只在查詢的那一行加鎖,其他行不加鎖的情況。

由上圖可以看到,在session A中執行了三次查詢,分別是Q1,Q2和Q3,他們的查詢語句都相同,但是返回結果都不同。其中Q3讀到id=1這一行的現象,被稱為“幻讀”。也就是說,幻讀值得是一個事務在前後兩次查詢同一個範圍的時候,後一次查詢看到了前一次查詢沒有看到的行。這裡需要對“幻讀”額外說明一下:
- 在可重覆讀隔離級別下,普通的查詢是快照讀,是不會看到別的事務插入的數據的。因此,幻讀在“當前讀”下才會出現。(之前有提到過,update語句是“當前讀”,select 語句如果加鎖,也是“當前讀”)
- 上面的session B的修改結果,被 session A之後的select語句(Q2,Q3)用“當前讀”看到,不能稱為“幻讀”。“幻讀”僅專指“新插入的行”。
因為這三次查詢都加了for update,都是當前讀。根據規則,就是要能讀到所有已經提交的記錄的最新值,並且Session B和Session C的兩條語句執行完成後就會提交,所以Q2和Q3就是應該看到這兩個事務的操作效果,而且也看到了,這跟事務的可見性規則並不矛盾。但這是不是真的沒有問題呢?不,這還真有一些問題。
幻讀有什麼問題?
首先是語義上的問題。Session A在T1時刻的查詢里包含for update,意思是“我要把所有d=5的行鎖住,不准別的事務進行讀寫操作”。但實際上,這個語義被破壞掉了。如果這樣還不夠明顯,可以想象一下,在T2時刻Session B中如果添加這樣一條語句:update t set c = 5 where id = 0;Session A的語義是 所有d=5的行鎖住,不准別的事務進行讀寫操作。但在T2時刻,Session B中id=0這一行沒有被Session A的聲明鎖住,同時,由於是在同一個事務中,對id=0(d=5)這一行的更新操作也能正常執行。
其次,是數據一致性的問題。我們知道,鎖的設計是為了保證數據的一致性。而這一致性,不止是資料庫內部數據狀態在此刻的一致性,還包含了數據和日誌在邏輯上的一致性。為了說明這個問題,我們給session A在T1時刻再加上一個更新語句,即:update t set d = 100 where d = 5;
update的加鎖語義和select ...for update是一致的,所以這時候加上這條update語句也很合理。session A聲明說“要給d=5的這條語句加上鎖”,也就是為了要更新數據,新加的這條update語句就把它認為加上了鎖的這一行的d值修改成100.我們來分析一下上圖執行完成之後,資料庫里會是什麼結果。
- 經過T1時刻,id=5這一行變成了(5,5,100),當然這個結果最終是在T6時刻正式提交的;
- 經過T2時刻,id=0這一行變成了(0,5,5);
- 經過T4時刻,表裡面多了一行(1,5,5);
- 其他行跟這個執行序列無關,保持不變。
這樣看起來,這些數據頁沒什麼問題。但是我們再來看看binlog里的內容
- T2時刻,Session B事務提交,寫入了兩條語句。
- T4時刻,Session C事務提交,寫入了兩條語句。
- T6時刻,Session A事務提交,寫入了update t set d = 100 where d = 5這條語句。
我們把這些語句統一放到一起的話,就是這樣的:
update t set d=5 where id=0; /*(0,0,5)*/ update t set c=5 where id=0; /*(0,5,5)*/ insert into t values(1,1,5); /*(1,1,5)*/ update t set c=5 where id=1; /*(1,5,5)*/ update t set d=100 where d=5;/* 所有 d=5 的行,d 改成 100*/
你應該可以看出問題了。這個語句序列,不論是拿到備庫執行,還是以後用binlog來克隆一個庫,這三行的結果會變成(0,5,100),(1,5,100),(5,5,100)。也就是說,id=0和id=1這兩行,發生了數據不一致。這個問題很嚴重,是不行的。我們再來仔細思考一下,這個數據不一致到底是怎麼引入的?
我們分析一下可以知道,這是我們假設“select * from t where d = 5 for update這條語句只給d=5這一行,也就是id=5的這一行加鎖”導致的。所以我們可以認為上面的設定不合理,需要更改。那要怎麼改呢,我們把掃描中碰到的行,也都加上寫鎖,再來看看執行效果。

由於Session A把所有的行都加上了寫鎖,所以Session B在執行第一個update語句的時候就被鎖住了。需要等到T6時刻Session A提交後,Session B才能繼續執行。這樣,對於id=0這一行,在資料庫里的最終結果還是(0,5,5)。在binlog裡面,執行序列是這樣的:
insert into t values(1,1,5); /*(1,1,5)*/ update t set c=5 where id=1; /*(1,5,5)*/ update t set d=100 where d=5;/* 所有 d=5 的行,d 改成 100*/ update t set d=5 where id=0; /*(0,0,5)*/ update t set c=5 where id=0; /*(0,5,5)*/
可以看到,按照日誌順序執行,id=0這一行的最終結果也是(0,5,5).所以,id=0這一行的問題解決了。但同時你也會看到,id=1這一行,在資料庫裡面的結果是(1,5,5),而根據binlog的執行結果是(1,5,100),也就是說幻讀的問題還是沒有解決。為什麼我們已經這麼“凶殘”地把所有記錄都加上鎖了,還是阻止不了這樣的問題呢?原因其實很簡單,T3時刻,我們給所有行加鎖的時候,id=1這一行還不存在,不存在自然我們的鎖對它也沒有任何辦法。也就是說,即使所有記錄都加上了鎖,還是阻止不了新插入的記錄。這也是為什麼“幻讀”會被單獨拿出來解決的原因。
如何解決幻讀?
產生幻讀的原因是,行鎖只能鎖住行,但是新插入記錄這個動作,要更新的是記錄之間的“間隙”。因此,為瞭解決幻讀的問題,InnoDB只好引入新的鎖,也就是間隙鎖(Gap Lock)。顧名思義,間隙鎖,鎖的是兩個值直接的間隙。比如文章開頭的表t,初始化插入了6個記錄,這就產生了7個間隙。

表t主鍵索引上的行鎖和間隙鎖
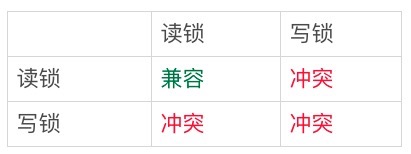
這樣,當你執行select * from t where d = 5 for update的時候,就不止是給資料庫中已有的6個記錄加上了行鎖,還同時加了7個間隙鎖。這樣就確保了無法再插入新的記錄。也就是說,這一行行的掃描結果中,不僅給行加上了鎖,也給行兩邊的空隙加上了間隙鎖。所以,行是可以加鎖的實體,行與行之間的間隙,也是可以加鎖的實體。但是間隙鎖和我們之前碰到過的鎖都不太一樣。比如行鎖,分成讀鎖和寫鎖。斜土就是這兩種類型鎖的衝突關係:
也就是說,跟行鎖有衝突關係的是“另一個行鎖”。但是間隙鎖不一樣,跟間隙鎖存在衝突關係的,是“往這個間隙中插入一個記錄”這個操作。間隙鎖之間都不存在衝突關係。這句話不是很容易理解,我們來舉個例子:

這裡session B不會被鎖住。因為表t里並沒有c=7的記錄,因此Session A加間隙鎖的間隙是(5,10)。而Session B也是在這個間隙加的間隙鎖。它們有共同的目標,即:保護這個間隙,不允許插入值。但,它們之間是不衝突的。間隙鎖和行鎖合稱next-key lock,每個next-key lock是前開後閉區間。也就是說,我們的表t初始化以後,如果用select * from t for update要把整個表所有記錄鎖起來,就形成了7個next-try lock。需要註意的是,結合上面的表t的初始化數據,最後一個區間是 (25, +supremum]。仍是前開後閉的。你可能會好奇supremum是什麼。因為整無窮是開區間。實現上,InnoDB給每個索引加了一個不存在的最大值supremum,這樣才符合我們剛纔說的“都是前開後閉的區間”。
間隙鎖和next-key lock的引入,幫我們解決了幻讀的問題,但同時也帶來了一些“困擾”。我們以這樣一個業務邏輯來舉例:任意鎖住一行,如果這一行不存的話就插入,如果存在這一行就更新它的數據,代碼如下:
begin; select * from t where id=N for update; /* 如果行不存在 */ insert into t values(N,N,N); /* 如果行存在 */ update t set d=N set id=N; commit;
可能你會建議使用 insert... on duplicate key update這條語句,但其實在有多個唯一主鍵的時候這個方法不能滿足需求,具體我們以後會展開說明。現在我們就單獨考慮一下這個邏輯。這種情景下的一個現象是,這個邏輯一旦有併發,就會碰到死鎖。你一定有點奇怪,這個邏輯每次操作前都有用for update鎖起來,已經是最嚴格的模式了,為什麼還是有死鎖呢?這裡,我們用兩個session來模擬併發,並假設N=9。

你看到了,其實都不需要用到後面的update語句,就已經形成了死鎖。我們按語句執行順序分析一下:
- Session A執行select...for update語句,由於id=9這一行並不存在,因此會加上間隙鎖(5,10);
- Session B執行select...for update語句,同樣加上間隙鎖(5,10),間隙鎖之間不會衝突,因此這個語句可以執行成功;
- Session B試圖插入一行(9,9,9),被Session A的間隙鎖擋住了,只好進入等待。
- Session A試圖插入一行(9,9,9),被Session B的間隙鎖擋住了,死鎖。
因此,間隙鎖的引入,可能會導致同樣的語句鎖住更大的範圍,這其實是影響了併發度的。當然,以上的內容都是建立在可重覆讀隔離級別下的,如果你吧隔離級別更改成讀提交,就不會有間隙鎖了。但同時,你可能需要解決出現的數據和日誌不一致問題。需要把binlog格式設置為row,這也是不少公司使用的配置組合。


