
一.Spark2.0的新特性Spark讓我們引以為豪的一點就是所創建的API簡單、直觀、便於使用,Spark 2.0延續了這一傳統,併在兩個方面凸顯了優勢: 1、標準的SQL支持; 2、數據框(DataFrame)/Dataset (數據集)API的統一。 在SQL方面,我們已經對Spark的SQL ...
一.Spark2.0的新特性
Spark讓我們引以為豪的一點就是所創建的API簡單、直觀、便於使用,Spark 2.0延續了這一傳統,併在兩個方面凸顯了優勢:
1、標準的SQL支持;
2、數據框(DataFrame)/Dataset (數據集)API的統一。
在SQL方面,我們已經對Spark的SQL功能做了重大拓展,引入了新的ANSI SQL解析器,並支持子查詢功能。Spark 2.0可以運行所有99個TPC-DS查詢(需求SQL:2003中的很多功能支持)。由於SQL是Spark應用所使用的主要介面之一,對SQL功能的拓展大幅削減了將遺留應用移植到Spark時所需的工作。
在編程API方面,我們合理化了API:
1、在Scala/Java中統一了DataFrames與Dataset:從Spark 2.0開始,DataFrames只是行(row)數據集的typealias了。無論是映射、篩選、groupByKey之類的類型方法,還是select、groupBy之類的無類型方法都可用於Dataset的類。此外,這個新加入的Dataset介面是用作Structured Streaming的抽象,由於Python和R語言中編譯時類型安全(compile-time type-safety)不屬於語言特性,數據集的概念無法應用於這些語言API中。而DataFrame仍是主要的編程抽象,在這些語言中類似於單節點DataFrames的概念,想要瞭解這些API的相關信息,請參見相關筆記和文章。
2、SparkSession:這是一個新入口,取代了原本的SQLContext與HiveContext。對於DataFrame API的用戶來說,Spark常見的混亂源頭來自於使用哪個“context”。現在你可以使用SparkSession了,它作為單個入口可以相容兩者,點擊這裡來查看演示。註意原本的SQLContext與HiveContext仍然保留,以支持向下相容。
更簡單、性能更佳的Accumulator API:我們設計了一個新的Accumulator API,不但在類型層次上更簡潔,同時還專門支持基本類型。原本的Accumulator API已不再使用,但為了向下相容仍然保留。
3、基於DataFrame的機器學習API將作為主ML API出現:在Spark 2.0中,spark.ml包及其“管道”API會作為機器學習的主要API出現,儘管原本的spark.mllib包仍然保留,但以後的開發重點會集中在基於DataFrame的API上。
4、機器學習管道持久化:現在用戶可以保留與載入機器學習的管道與模型了,Spark對所有語言提供支持。查看這篇博文以瞭解更多細節,這篇筆記中也有相關樣例。
R語言的分散式演算法:增加對廣義線性模型(GLM)、朴素貝葉斯演算法(NB演算法)、存活回歸分析(Survival Regression)與聚類演算法(K-Means)的支持。
二.Spark2.4 安裝
環境要求jdk 1.8以上版本,scala-2.12以上
基於的Hadoop版本,我的現有hadoop為2.6
官網下載時註意:http://spark.apache.org/downloads.html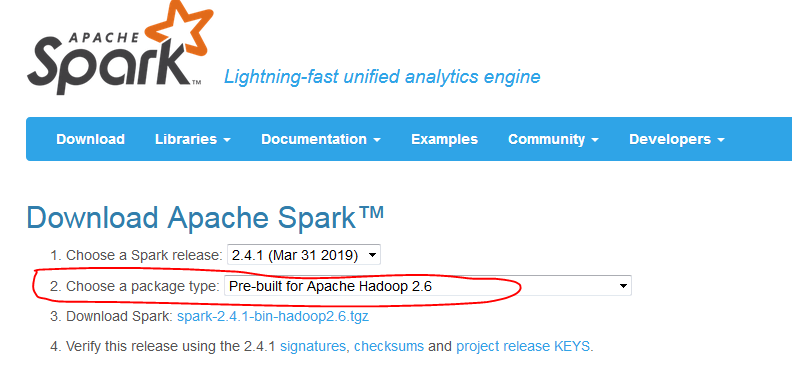
安裝架構
h220 為主節點
H221,h222 為從節點
1.解壓縮spark
[hadoop@h220 spark]$ cp spark-2.4.1-bin-hadoop2.6.tgz /home/hadoop/
[hadoop@h220 ~]$ tar -zxvf spark-2.4.1-bin-hadoop2.6.tgz
2.安裝jdk,scala
[hadoop@h220 usr]$ tar -zxvf jdk-8u151-linux-x64.tar.gz
[hadoop@h220 ~]$ tar -zxvf scala-2.12.4.tgz
3.設置環境變數
[hadoop@h220 ~]$ vi .bash_profile
export JAVA_HOME=/usr/jdk1.8.0_151
export JAVA_BIN=/usr/jdk1.8.0_151/bin
export SCALA_HOME=/home/hadoop/scala-2.12.4
export SPARK_HOME=/home/hadoop/spark-2.4.1-bin-hadoop2.6
[hadoop@h220 ~]$ source .bash_profile
4.配置spark
[hadoop@h220 ~]$ cd spark-2.4.1-bin-hadoop2.6/conf/
[hadoop@h220 conf]$ cp spark-env.sh.template spark-env.sh
[hadoop@h220 conf]$ vi spark-env.sh
添加:
export JAVA_HOME=/usr/jdk1.8.0_151
export SCALA_HOME=/home/hadoop/scala-2.12.4
export SPARK_MASTER_IP=h220
export SPARK_WORDER_INSTANCES=1
export SPARK_WORKER_CORES=1
export SPARK_WORKER_MEMORY=1g
export HADOOP_HOME=/home/hadoop/hadoop-2.6.0-cdh5.5.2
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.6.0-cdh5.5.2/etc/hadoop
[hadoop@h220 conf]$ cp slaves.template slaves
[hadoop@h220 conf]$ vi slaves
刪除localhost
添加:
h221
h222
5.copy到從節點
配置ssh證書
[hadoop@h220 ~]$ scp -r spark-2.4.1-bin-hadoop2.6 h221:/home/hadoop/
[hadoop@h220 ~]$ scp -r spark-2.4.1-bin-hadoop2.6 h222:/home/hadoop/
6.啟動,驗證
主節點:
[hadoop@h220 spark-2.4.1-bin-hadoop2.6]$ sbin/start-all.sh
[hadoop@h220 spark-2.4.1-bin-hadoop2.6]$ jps
6970 Master
從節點:
[hadoop@h221 spark-2.4.1-bin-hadoop2.6]$ jps
3626 Worker
主節點:
[hadoop@h220 spark-2.4.1-bin-hadoop2.6]$ bin/spark-shell
沒有報錯


