
3 、redis的5種數據類型及相應命令 redis不區分命令大小寫。 string 512m 一個散列類型鍵可包含至多232-1個欄位 一個列表類型鍵最多能容納232-1個元素 一個集合類型鍵最多能容納232-1個元素 3.1、一些實用的基礎命令 keys pattern exists key 返 ...
3 、redis的5種數據類型及相應命令
redis不區分命令大小寫。

|
string 512m 一個散列類型鍵可包含至多232-1個欄位 一個列表類型鍵最多能容納232-1個元素 一個集合類型鍵最多能容納232-1個元素 |
3.1、一些實用的基礎命令
|
keys pattern |

|
|
exists key |
返回值:存在返回1,不存在返回0 |
|
del key1 [key2 key3 ...] |
返回值:刪除的鍵的個數 |
|
type key |
返回值:string、hash、list、set、zset |

|
技巧:刪除所有複合規則的鍵(註意del不支持通配符) |
|
|
方案1 (推薦) |
在linux命令行執行下麵命令: [root@tkafka ~]# redis-cli del `redis-cli keys "a*"` 註意用的反單引號,將redis-cli keys "a*"命令的結果作為redis-cli del命令的參數。 |
|
方案2 |
在linux命令行執行下麵命令: [root@tkafka ~]# redis-cli keys "a*" | xargs redis-cli del 利用的是linux管道和xargs命令 |
3.2、字元串類型[string]
字元串類型是redis中最基本的數據類型,是其它4種數據類型的基礎,例如列表類型是以列表的形式組織字元串,集合類型是用集合的形式組織字元串。
string可存儲任何形式的字元串,比如數值形式的字元串,二進位形式的字元串,json格式的字元串等,也就是說string能存儲數值、圖片、json化對象等。
|
基礎命令 |
||
|
set key value get key |
|
|
|
mset key value [key2 value2 ...] mget key [key2 ...] |
|
|
|
append key value |
描述:向鍵值的末尾追加value,如果鍵不存在則相當於set key value。 返回值:追加後的字元串長度。 |
|
|
strlen key |
你好(6) ab(2) |
|
|
-- 當字元串類型存儲的是【整數形式的字元串】時,才可以用的命令,否則報錯: |
||
|
incr key incrby key increment |
註意:若key不存在,incr命令會預設key的值為0,再進行遞增;若key的值不是整數形式的字元串,redis會報錯。 返回值:返回遞增後的值。 |
|
|
decr key decrby key decrement |
這兩個指令功能都可以用 incrby key increment 實現 |
|
|
incrbyfloat key increment |
|
|
|
--位操作命令: |
||
|
getbit key offset |
|
|
|
setbit key offset value |
|
|
|
bitcount key [startByteIndex] [endByteIndex] |
統計字元串類型鍵中值是1的二進位位的個數。 可以加兩個參數來限制統計的位元組範圍[0開始]。 |
|
|
bitop operation destkey key1 key2 … keyN |
對多個字元串類型鍵進行位運算,並將結果存儲destkey參數指定的鍵中,operation可選AND、OR、XOR、NOT。 |
|
|
bitpos key bitValue [startByteIndex] [endByteIndex] |
獲得指定鍵中第一個位值為0或1的二進位位的偏移量[0開始]。bitValue可選0、1。 可以加兩個參數來限制查詢的位元組範圍[0開始]。 |
|
註意:包括incr在內的所有redis命令都是原子操作,無論多少客戶端同時連接,都不會出現併發性的安全問題。但是如果你希望在程式自己寫一個方法來實現incr命令的效果,就得自己在代碼層面保證該方法是線程安全的。
|
實踐 |
|
1、鍵命名實踐:【對象類型名:對象id:對象屬性名】;如user:1:age 多個單詞用“.”分隔,如user:2:first.name |
|
2、 文章訪問量 對每篇文章都用一個鍵article:articleId:visit.count來記錄該篇文章的訪問量,訪問一次就incr一次。 |
|
3、自增id 為一類對象如article定義一個鍵如articles:count,用於保存該類對象的數量。 每要增加一個該類對象時都先做一次incr,incr的返回值即可作為該新增對象的id。 |
|
4、存儲文章數據(下節會講這種實現方式的缺陷) 鍵名article:articleId:article.Data 鍵值:articleTitle,articleAuthor,aticleContent,articleTime序列化後的字元串。 獲取文章數據時,獲取鍵值後進行反序列化即可。 |
|
5、位操作命令實踐 |

3.3、散列類型[hash]

redis是採用字典結構<key, value>存儲數據的,在此之上,散列類型鍵的鍵值也是字典結構的<key, <field, value>>,其中的value只能是基礎的字元串類型。redis中的數據類型不支持數據類型嵌套,也就是說hash、list、set、zset中的元素只能是基礎的字元串類型。
散列類型適合存儲對象。鍵命名:對象類名:對象ID。
對於關係型資料庫中的表,由於其是二維表結構的,表中每條記錄擁有的欄位是一致的,無法單獨為某條記錄增減屬性而不影響其它記錄;散列類型則沒有此限制,例如user:1的欄位為name、age、phone,但user:2的欄位為name、sex、city。
|
hset key field value hsetnx key field value hget key field |
調用hset時不用區分是插入屬性還是更新屬性,且當key不存在時,hset還會自動創建key。 返回值:1表示是執行的是插入操作,0表示執行的是更新操作。 hsetnx只在欄位不存在時才進行賦值[not exists]。 |
|
hmset key field value [field2 value2 ...] hmget key field [field2 ...] |
|
|
hexist key field |
返回值:1或0 |
|
hdel key field [field2 …] |
|
|
hincrby key field increment |
返回值為增長後的欄位值。 當key不存在時,hincrby命令會自動創建key,並預設field在增長前的欄位值為0。 |
|
hgetall key hkeys key hvals key hlen key |
很多語言的redisClient會將hgetall的返回結果封裝成編程語言中的對象 |
|
實踐 |
|
1、 存儲文章數據(本節開始有講到用字元串來存儲對象的缺點,這裡實踐下用散列來存儲對象) <article:articleId,<文章各欄位名,欄位值>> 欄位有articleTitle,articleAuthor,aticleContent,articleTime |
|
2、 存儲文章縮略名【slug】 縮略名用於構成文章網址的一部分,每篇文章的縮略名必須是唯一的,發佈文章時需要驗證用戶輸入的縮略名是否已被占用;系統還應提供根據縮略名獲取文章id的功能。 <slug.to.id,<slugname,articleid>>用於存儲文章縮略名和文章id之間的映射關係。”hexists slug.to.id slugname”可以驗證縮略名是否已被占用;”hget slug.to.id slugname”可以根據縮略名獲取文章id;另外修改文章縮略名時要修改<slug.to.id,<slugname,articleid>>中相應欄位。 |
3.4、列表類型[list]
列表類型(list)內部使用雙向鏈表結構實現的。向鏈表兩端添加元素的時間複雜度為O(1),獲取元素時獲取越接近兩端的元素就越快;跟索引有關的操作較慢。

|
基礎命令 |
|
|
lPush|rPush key value [value2 ...] |
返回值:增加元素後列表的長度 |
|
lPop|rPop key |
返回值:被移除的元素值 |
|
lLen key |
實現上,redis會直接讀取現成的值,所以時間複雜度為O(1) |
|
lRem key count value |
刪除列表中前count個值為value的元素 返回值:實際刪除的元素個數 |
|
lInsert key before|AFTER pivot value |
描述:先從左到右的從列表中查找值為pivot的元素,然後根據第二個參數是BEFORE還是AFTER來決定將value插入到該元素之前還是之後。 返回值:插入後,列表中元素個數 |
|
用作數組【效率較低】 |
|
|
lRange key start end |
描述:獲取列表片段[startIndex, endIndex],索引從0開始 註意:lrange支持負索引,表示從最右邊開始數,-1表示最右邊第一個元素,即”lrange key 0 -1”可以獲取列表中所有元素。 |
|
lTrim key start end |
刪除指定索引範圍之外的所有元素 |
|
lIndex key index |
|
|
lSet key index value |
|
|
用做棧(lpush + lpop 或 rpush + rpop) |
|
|
用作隊列(lpush + rpop 或 rpush + lpop) |
|
|
rpoplpush srcQueue destQueue |
描述:從srcQueue列表類型鍵的右邊彈出一個元素,然後將其加入到destQueue列表類型鍵的左邊,並返回這個元素,當然整個過程是原子的。 rpoplpush可用於在多個隊列間傳遞數據。 |



|
實踐 |
|
1、存儲按時間排序的文章id列表 用列表類型鍵articles:list來存儲文章id列表,發佈新文章時要使用lpush將新文章的id加入此列表中,刪除文章時要使用lrem把列表中的相應文章id移除掉,這樣就可以用lrange來實現文章分頁了。 “lrange ARTICLES:LIST (pageIndex-1)*pageSize pageIndex*pageSize-1” |
|
2、存儲評論列表 用列表類型鍵ARTICLE:articleId:COMMENTS來存儲某篇文章的所有評論。 |


3.5、集合類型[set]
集合類型(set)內部是使用值為空的hashtable<E,~>實現的,常用的操作如add(E)、remove(E)、contains(E)時間複雜度都是O(1)。

|
基礎命令 |
||
|
sAdd key member [member2 ...] |
如果key不存在則會自動創建 返回值:成功插入的元素數量(插入操作前集合中已存在的元素會被忽略插入,不參與計數) |
|
|
sRem key member [member2 ...] |
返回刪除成功的元素個數 |
|
|
sMembers key |
返回集合中所有元素 |
|
|
sIsMember key member |
判斷元素是否在集合中 |
|
|
scard key |
返回集合中元素個數 |
|
|
隨機操作 |
||
|
sPop key |
從集合中隨機彈出一個元素 |
|
|
sRandMember key [count] |
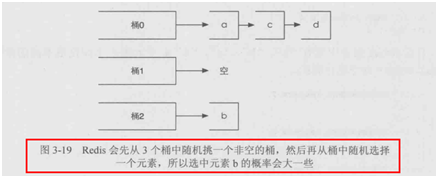
隨機從集合中獲取一個元素,可以指定count參數來隨機獲取多個元素。
|
|
|
集合間運算命令 |
||
|
sDiff key [key2 …] |
差集(A-B:所有屬於A但不屬於B的元素)。 “sDiff A B C”表示(A-B)-C |
|
|
sInter key [key2 …] |
交集 |
|
|
sUnion key [key2 …] |
並集 |
|
|
sDiffStore destCollection key1 [key2 ...] |
這3個命令會將運算結果存儲在destCollection鍵中而不會返回,常用於需要進行多步集合運算的場景中,如需要先進行差集再將結果和其它鍵計算交集。 |
|
|
sInterStore destCollection key1 [key2 ...] |
||
|
sUnionStore destCollection key1 [key2 ...] |
||

|
實踐 |
|
1、存儲文章標簽 由於一個文章的所有標簽不會重覆,且在展示時沒要求標簽順序,所以可以用集合類型鍵ARTICLE:articleId:TAGS來存儲文章標簽。 |
|
2、通過標簽搜索文章 為每個標簽定義一個集合類型鍵TAG:tagname:ARTICLES來存儲該標簽下的文章ID列表。用sMember可得到一個標簽下所有文章;用sInter可得到同屬於某幾個標簽的文章。 |

3.6、有序集合類型[zset]
在集合類型的基礎上,有序集合類型為集合中的每個元素都關聯了一個分數,所以比集合類型多了一些與分數有關的操作。有序集合中的元素不能重覆,但是不同元素的分數可以相同。
|
有序集合類型與列表類型 |
|
|
相似點 |
區別 |
|
1)有序 2)可以獲取某一範圍的元素 |
1)實現方式不同 2)列表中不能簡單地調整某個元素的位置,但是有序集合可以(通過更改這個元素的分數) 3)有序集合比列表更耗記憶體 |

|
基礎命令 |
|
|
zAdd key score member [score2 member2 ..] |
描述:加入一個指定分數的元素,若元素已存在則更新該元素的分數。分數可以是整數、double、+inf(正無窮)、-inf(負無窮)。 返回值:新加入到集合中的元素個數 |
|
zScore key member |
返回元素的分數 |
|
zIncrBy key increment member |
描述:增加某個元素的分數,分數可為負數。 返回值:更改後的分數 |
|
zCard key |
返回元素數量,類比sCard |
|
zRem key member [member2 ...] |
返回成功刪除的元素數量(不包含本來就不存在的元素) |
|
跟順序相關的命令 |
|
|
zRange key start end [withScores] |
zRange命令會按照元素分數從小到大的順序返回索引從start到end之間的所有元素[start, end],zReRange則是從大到小。加上”withScores”參數表示需要同時獲取元素的分數。 zRange可類比列表的LRange,索引都是從0開始,負數索引表示從最右邊開始往前數(-1表示最右邊的元素) zRange命令時間複雜度為O(log(n+m)),n為有序集合的基數,m為要返回的元素個數。 對於分數相同的元素,redis會按照字典序(0<9<A<Z<a<z)來進行排列。 |
|
zRevRange key start end [withScores] |
|
|
zRangeByScore key min max [withScores] [limit offset count] |
zRangeByScore命令按元素分數從小到大的順序返回分數在min和max之間的所有元素[min, max]。 如果希望分數範圍不包含端點值,可以在分數前加上”(”,例如”80 (100”表示[80, 100)。min和max支持無窮大+inf和-inf,例如”(80 +inf”表示80分以上。 limit offset count和在sql中的語義一樣,表示在獲得元素列表的基礎上向後偏移offset個元素,然後獲取前count個元素。 |
|
zRevRangeByScore key max min [withScores] [limit offset count] |
|
|
zRemRangeByRank key start end |
按排名範圍刪除,返回刪除的元素數量 |
|
zRemRangeByScore key min max |
按分數範圍刪除,返回刪除的元素數量 |
|
zCount key min max |
獲取指定分數範圍的元素個數 |
|
zRank key member |
獲得指定元素的排名(0開始) |
|
zRevRank key member |
|
|
集合間運算命令(用到再查) |
|
|
zInterStore … |
計算有序集合的交集 |
|
zUnionStore … |
計算有序集合的並集 |

|
實踐 |
|
1按文章點擊量順序獲取文章列表 集合類型鍵ARTICLES:ARTICLE.VISIT.COUNT,以文章ID作為集合元素,以文章訪問量作為元素分數。沒當一篇文章被訪問時,就用”zIncrBy ARTICLES:ARTICLE.VISIT.COUNT 1 aticleId”來更新文章訪問量。 這樣,通過”zReRange ARTICLES:ARTICLE.VISIT.COUNT (pageIndex-1)*pageSize pageIndex*pageSize-1”命令即可實現按照文章點擊量順序獲取文章列表。通過”zScore ARTICLES:ARTICLE.VISIT.COUNT articleId”可獲取某篇文章的訪問量。有了這個鍵,就不再用3.2節定義的字元串類型鍵ARTICLE:articleId:VISIT.COUNT來記錄單個文章的訪問量了。 |
|
2改進按時間順序排列文章 3.4節的列表類型鍵實現,在更改元素順序上比較麻煩;為了能夠自由更改文章發佈時間,這裡採用有序集合類型代替列表類型,以文章ID作為集合元素,文章發佈的Unix時間(一個秒數)作為元素分數;通過修改元素的分數來實現更改文章發佈時間,通過zRevRangeByScore來實現獲取指定時間範圍的文章列表。 |


