
筆記記錄自林曉斌(丁奇)老師的《MySQL實戰45講》 (本篇內圖片均來自丁奇老師的講解,如有侵權,請聯繫我刪除) 16) --“order by”是怎麼工作的? 在林老師的課程中,第15講是前面問題的答疑,我打算最後將答疑問題統一整理出來,所以就繼續這些內容的筆記了。 全欄位排序: 假設有一個表是 ...
筆記記錄自林曉斌(丁奇)老師的《MySQL實戰45講》
(本篇內圖片均來自丁奇老師的講解,如有侵權,請聯繫我刪除)
16) --“order by”是怎麼工作的?
在林老師的課程中,第15講是前面問題的答疑,我打算最後將答疑問題統一整理出來,所以就繼續這些內容的筆記了。
全欄位排序:
假設有一個表是這麼設計的:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `city` varchar(16) NOT NULL, `name` varchar(16) NOT NULL, `age` int(11) NOT NULL, `addr` varchar(128) DEFAULT NULL, PRIMARY KEY (`id`), KEY `city` (`city`) ) ENGINE=InnoDB;
這時,你的SQL語句可以這麼寫:
select city,name,age from t where city='杭州' order by name limit 1000;
如果我們使用explain命令來看這個語句的情況會發現,extra這個欄位中的"Using filesort"表示的就是需要排序,MySQL會給每個線程分配一塊記憶體用於排序,稱為sort buffer.我們知道,非主鍵索引其實存儲的是對應的主鍵id。因此上述語句的執行流程大致如下:
- 初始化sort_buffer,確定放入name,city,age三個欄位。
- 從索引city找到第一個滿足city=‘杭州’條件的主鍵id。
- 到主鍵id索引取出整行,取name,city,age三個欄位的值,存入sort_buffer中
- 從索引city取下一個記錄的主鍵id;
- 重覆步驟3,4直到city的值不滿足查詢條件為止。
- 對sort_buffer中的數據按照欄位name做快速排序。
- 按照排序結果取前1000行返回給客戶端。
我們暫且把這個排序過程,稱為全欄位排序,執行流程的示意圖如下:
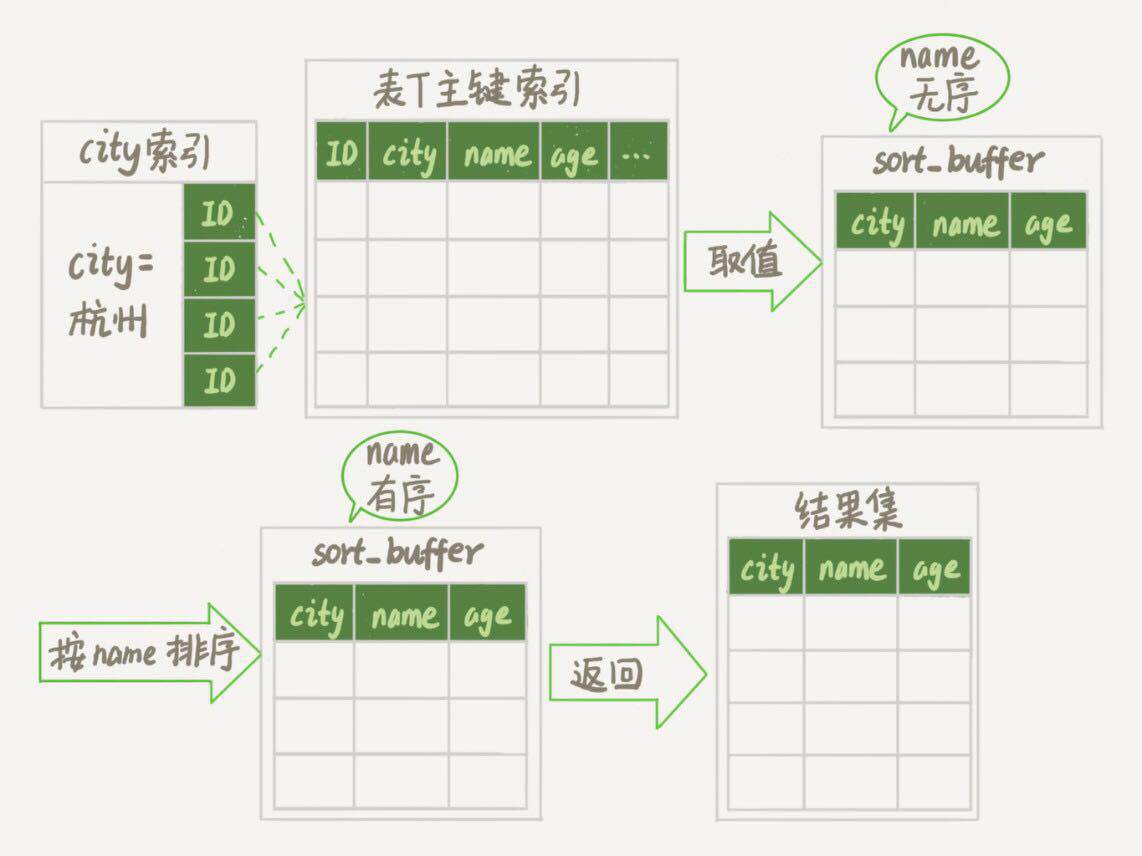
其中的“按name排序”這個動作,可能在記憶體中完成,也可能需要使用外部排序,這取決於排序所需的記憶體和參數sort_buffer_size。這個參數的含義是MySQL為排序開闢的記憶體(sort buffer)大小。如果要排序的數據量小於sort_buffer_size,排序就在記憶體中完成。但如果排序量太大,記憶體放不下,則不得不利用磁碟臨時文件輔助排序。而關於外部排序,需要知道的是:外部排序一般使用歸併演算法進行排序。可以這麼簡單理解,MySQL將需要排序的數據分成N份,每一份單獨排序後存在這些臨時文件中。然後把這N個有序文件再合併成一個有序的大文件。如果sort_buffer_size越小,需要分成的份數就越多,number_of_tmp_files的值就越大。
RowId排序:
上面這個過程中,排序操作是在sort_buffer和臨時文件中執行的。但這個演算法有一個問題,就是如果查詢要返回的欄位很多,那麼sort_buffer裡面要放的欄位就會很多,這樣能放得下的行數就會很少,要分成很多個臨時文件,排序的性能會很差。那麼,如果MySQL認為排序的單行長度太大會怎麼做呢?
我們先來修改一個參數的值。SET max_length_for_sort_data=16.這個參數是MySQL中專門用於控制排序的行數據的長度的一個參數。它的意思是,如果單行的長度超過這個值,MySQL就認為單行太大,要換一個排序演算法。上述建表中可以看到,city,name,age的總長度為36,大於我們剛剛設置的16,我們再來看看計算過程有什麼變化。
新的方式中要放入sort_buffer的欄位由原來的name,city,age變為了要排序的列(name)和主鍵Id.很明顯,這樣排序的結果是不包含city和age欄位的,因此不能直接返回。所以整個流程就變為:
- 初始化sort_buffer,確定放入兩個欄位,name和id
- 從索引city找到一個滿足city='杭州'條件的主鍵id
- 到主鍵id索引取出整行,取name,id這兩個欄位,存入sort_buffer中;
- 從索引city取下一個記錄的主鍵id
- 重覆步驟3,4,直到不滿足city='杭州'條件為止。
- 對sort_buffer中的數據按照欄位name進行排序。
- 遍歷排序結果,取前1000行,並按照id的值回到原表中取出city,name和age三個欄位返回給客戶端。
全欄位排序 VS rowid排序:
如果MySQL擔心排序記憶體太小,會影響排序效率,才會採用rowid排序演算法,這樣排序過程中一次可以排序更多行,但是需要回到原表去取數據。
如果MySQL認為記憶體足夠大,會優先選擇全欄位排序,把需要的欄位都放到sort_buffer中,這樣排序後就會直接從記憶體裡面返回查詢結果了,不用再回到原表去取數據。這也體現了MySQL的一個設計思想:如果記憶體夠,就要多利用記憶體,儘量減少磁碟訪問。對於InnoDB表來說,rowid排序會要求會標多造成磁碟讀,因此不會被優先選擇。排序是一個成本比較高的操作,其實,並不是所有的order by語句,都需要排序操作的。從上面分析的執行過程,我們可以看到,MySQL之所以需要臨時表來進行排序,原因是原來的數據都是無序的。(好像有點廢話~~)。如果能保證從city這個索引上取出來的行,天然就是按照name遞增來排序的,就可以不用排序了。
因此,我們可以在這個表上創建一個city和name的聯合索引,對應的sql語句是:
alter table t add index city_user(city,name);
這個索引除了滿足city=‘杭州’的數據會聚集在一起,還額外滿足了一個條件。那就是如果一組city='杭州'的記錄,那麼就可以保證這些記錄都是按name繼續進行排序的。所以語句執行流程就變為:
- 從索引city_user找到第一個滿足條件city=‘杭州’的主鍵id
- 到主鍵id索引去除整行,取name,city,age三個欄位的值,作為結果集的一部分直接返回。
- 從索引city_user取下一個記錄
- 重覆步驟2,3直到查到第1000條記錄或是不滿足city=‘杭州’為止。
額外補充一點,假設city=‘杭州’的數據有4000條,當你用explain命令去查看上面幾次的排序語句時會發現,除city_user這個索引外,其他的掃描行數都為4000。因為要獲取全部的city=‘杭州’之後才能按照name排序取前一行。而如果使用了city_user索引,則只需要掃描1000行就能返回結果。
那麼,還有沒有可能再快一點呢?答案是肯定的。我們之前有介紹過“覆蓋索引”.如果你要查詢的欄位完全包含在覆蓋索引之內,就不需要再返回主鍵id索引中取出全部的數據來了。即減少了回表,具體流程就不寫出來了。
上期問題:
在上期關於count計數的討論中,我們用了事務來確保數據的精確性。由於事務可以保證中間結果不被別的事務讀到,因此修改計數值和插入新的記錄的順序是不影響邏輯結果的。但是,從併發系統性能的角度考慮,你覺得在這個事務序列里,應該先插入操作記錄,還是先更新計數表呢?
關於上期的內容,具體可以點擊這裡查看上一篇。
用一個計數表記錄一個業務表的總行數,在往業務表插入數據的時候,需要給計數值加1.邏輯上實現是啟動一個事務,執行兩個語句:
- insert into 數據表。
- update 計數表,計數值加1.
應該怎麼安排這兩個語句的順序呢?併發系統性能的角度考慮,應該先插入操作記錄,再更新計數表。因為更新計數表涉及到行鎖的競爭,先插入再更新能最大程度地減少事務之間的鎖等待,提升併發度。
關於每篇最後這個問題,我打算更換一下格式,以後整理幾篇文章之後再單獨出一篇問題的總結,也方便閱讀。因此這篇就先不留下問題了。

