
架構驅動的因素 運營商和互聯網面臨不同的歷史時期,因而大數據在各自領域承擔的使命是不一樣的 運營商面臨被管道化的挑戰,營收下滑,大數據項目承擔企業戰略轉型、數據變現的使命。同時由於成本的壓力,以及大量基礎設施和設備利舊的訴求,所以運營商在大數據項目中,對性能、成本和集成度提出了很高的要求。 互聯網企 ...
架構驅動的因素
運營商和互聯網面臨不同的歷史時期,因而大數據在各自領域承擔的使命是不一樣的
運營商面臨被管道化的挑戰,營收下滑,大數據項目承擔企業戰略轉型、數據變現的使命。同時由於成本的壓力,以及大量基礎設施和設備利舊的訴求,所以運營商在大數據項目中,對性能、成本和集成度提出了很高的要求。
互聯網企業近幾年盈利頗豐,大數據往往是承擔業務快速創新、未來探索的一種驅動因素,所以對架構的擴展性、靈活性等方面的追求優先順序在成本之上。互聯網企業每建一個數據中心通常就是幾千台的規模,這在運營商看來是不可想象的。
背後的商業驅動因素不一樣,所帶來的架構挑戰也不一樣。
大數據平臺架構
我們將以一個實際的大數據架構參與者、旁觀者的角色講述真正的實戰經驗,希望帶給讀者一些啟發。前面講到商業驅動因素不一樣,所面臨的場景不一樣,選擇的技術措施也會有所區別,但是其實存在即合理,實踐出真知
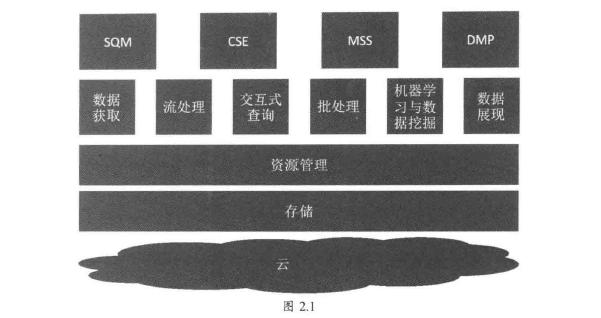
大數據平臺架構如圖2.1所示。可以看到,最上層是應用,大數據平臺最後還是要解決實際的業務問題,在運營商領域分別解決SQM(運維質量管理)、CSE(客戶體驗提升)、MSS(市場運維支撐)、DMP(數據管理平臺)等問題。這部分內容會在第3章詳細介紹。
第二層是各個組件/技術支撐,包括數據從產生獲取、處理(實時、批處理)、分析(互動式查詢、機器學習與數據挖掘)到最後的展現。這部分內容會在第4、8章介紹。
第三層,為了支持數據的存儲處理,需要統一的資源管理及分配。這部分內容會在第9章介紹。
第四層,上層框架和處理都構建在存儲的基礎上,所以存儲是基礎中的基礎。這部分內容會在第10章介紹。
第五層,大數據部署形態有雲化部署、物理機部署等多種部署模式。這部分內容會在第1 1章介紹。
第12章介紹大數據技術開發文化
平臺發展趨勢
Hadoop從2006年項目成立開始,已經風風雨雨走過了10年,從最開始的HDFS和MapReduce 兩個組件到現在完整的生態鏈。展望未來,隨著技術和業務的發展,下麵這些趨勢應該是所有設計和實現大數據平臺的人需要認真考慮的。
· Cloud First:雲優先。服務端利用雲的部署和擴展能力,保證數據訪問高併發、高可用、高可靠。
· stream Default:流優先。數據源端更多的是流數據,要求實時分析,進行秒級或分鐘級計算。
· Pervasive Analytics:普適分析。將分析能力推至數據源端、管道和服務端,低時延反饋結果
· self service:自服務。無須太多的人為干預和人力投人,使得數據合理放置,轉換為適合分析的數據類型,方便APP開發等。
現在看著風光無限的組件或者平臺,會不斷地被後來者所替代。
小結
本章簡要總結了本書的主要章節和內容。本書是圍繞一個通用的大數據處理邏輯架構來展開的。在實際的生產環境中,該架構並不是一成不變的,會根據業務來靈活地部署和應用。當然,在一個完整的企業大數據系統里,本書介紹的內容完全不夠,本書只介紹最基礎的大數據平臺,很多底層或者上層的內容可能沒有覆蓋到。另外,架構不是憑空出現的,由業務場景驅動的架構才是真正可用的架構。
謝謝支持,喜歡關註喲!


