
SolrCloud底層 添加/更新 文檔的過程是怎樣的? 它怎麼確定文檔要發給哪個Shard? 文檔的路由是做什麼的? 有什麼路由策略? 連同一些高效的實踐建議, 統統告訴你~ ...
目錄
1 添加文檔的細節
1.1 註冊觀察者 - watcher
Solr單機服務中, 與Solr內部進行交互的類是
HttpSolrServer.
SolrCloud集群中, 與Solr內部進行交互的類是CloudSolrServer.
這裡以SolrCloud集群為例講解添加文檔的相關細節.
當Solr客戶端向CloudSolrServer發送add/update請求時, CloudSolrServer會從ZooKeeper獲取當前SolrCloud的集群狀態,併在ZooKeeper管理的配置文件/clusterstate.json和/live_nodes中註冊觀察者watcher, 便於監視ZooKeeper和SolrCloud.
註冊觀察者的好處是:
①
CloudSolrServer獲得SolrCloud的狀態後, 就能直接把要添加/修改的document發往Solr集群的leader, 從而降低網路轉發上的消耗;
② 註冊watcher有利於添加索引時的負載均衡: 如果有個節點的leader下線了,CloudSolrServer就能立刻感知到, 它就會停止往已下線的leader發送請求.
1.2 文檔的路由 - document route
CloudSolrServer添加document時, 需要確定該document發往哪個Shard. SolrCloud集群中, 每個Shard都有一個Hash區間, 添加時, SolrCloud會計算該文檔的Hash值, 然後根據它的Hash值, 把它發送到對應Hash區間的Shard.
—— 上述過程稱為文檔的分發, 由Solr的document route(文檔路由)組件來完成.
1.2.1 路由演算法
SolrCloud提供了兩種路由演算法, 創建Collection(集合, 類似於MySQL中的表)時, 需要通過router.name來指定路由策略.
① compositeId - 預設的路由演算法:
- 該策略是一致性哈希路由, Shards的哈希範圍是
80000000~7fffffff;- 創建Collection的時候必須指定numShards, 這個路由演算法將根據Shard的個數, 計算出每個Shard的哈希範圍;
- 索引數據會均勻分佈在每個Shard上;
- 這個路由策略不支持擴展Shard, 否則會導致一些已經索引到Solr中的文檔無法被檢索.
② implicit - 絕對路由策略:
- 該路由策略是直接指定索引文檔落到具體的某個Shard上;
- 索引數據並不會均勻分佈到每個Shard上;
- 使用implicit路由策略的Collection才支持 創建/擴展 Shard.
1.2.2 Solr路由的實現類
Solr中路由的基類是DocRouter, 它有2個子類: CompositeIdRouter(預設使用的), 和ImplicitDocRouter.
我們可以通過繼承DocRouter類來定製自己的document route組件.
1.2.3 implicit路由演算法的使用
通過SolrJ創建文檔索引時, 使用implicit策略指定文檔的所屬Shard:
代碼如下:
doc.addField("route", "shard_X");同時, 要在schema.xml約束文件中添加欄位:
<field name="_route_" type="string"/>利用URL創建implicit路由方式的Collection:
http://ip:port/solr/admin/collections?action=CREATE&name=coll&router.name=implicit&shards=shard1,shard2,shard3
1.2.4 Solr獲取文檔Hash值的要求
① Hash值的計算速度必須很快, 這是分散式創建索引的第一步;
② Hash值必須能均勻地分佈到每一個Shard上. 如果某個Shard中document數量遠多於其他Shard, 那麼在查詢等操作中, 文檔數量多的Shard所花的時間就會大於其他Shard, 而SolrCloud的查詢是 先分給各個Shard查詢, 然後彙總返回 的過程, 也就是說SolrCloud的查詢速度是由最慢的Shard決定的.
基於以上兩點, Solr的底層引擎Lucene使用了MurmurHash演算法, 用來提高Hash值的計算速度和均勻分佈.
關於MurmurHash哈希演算法, 可參考文末的相關鏈接.
2 添加索引的過程
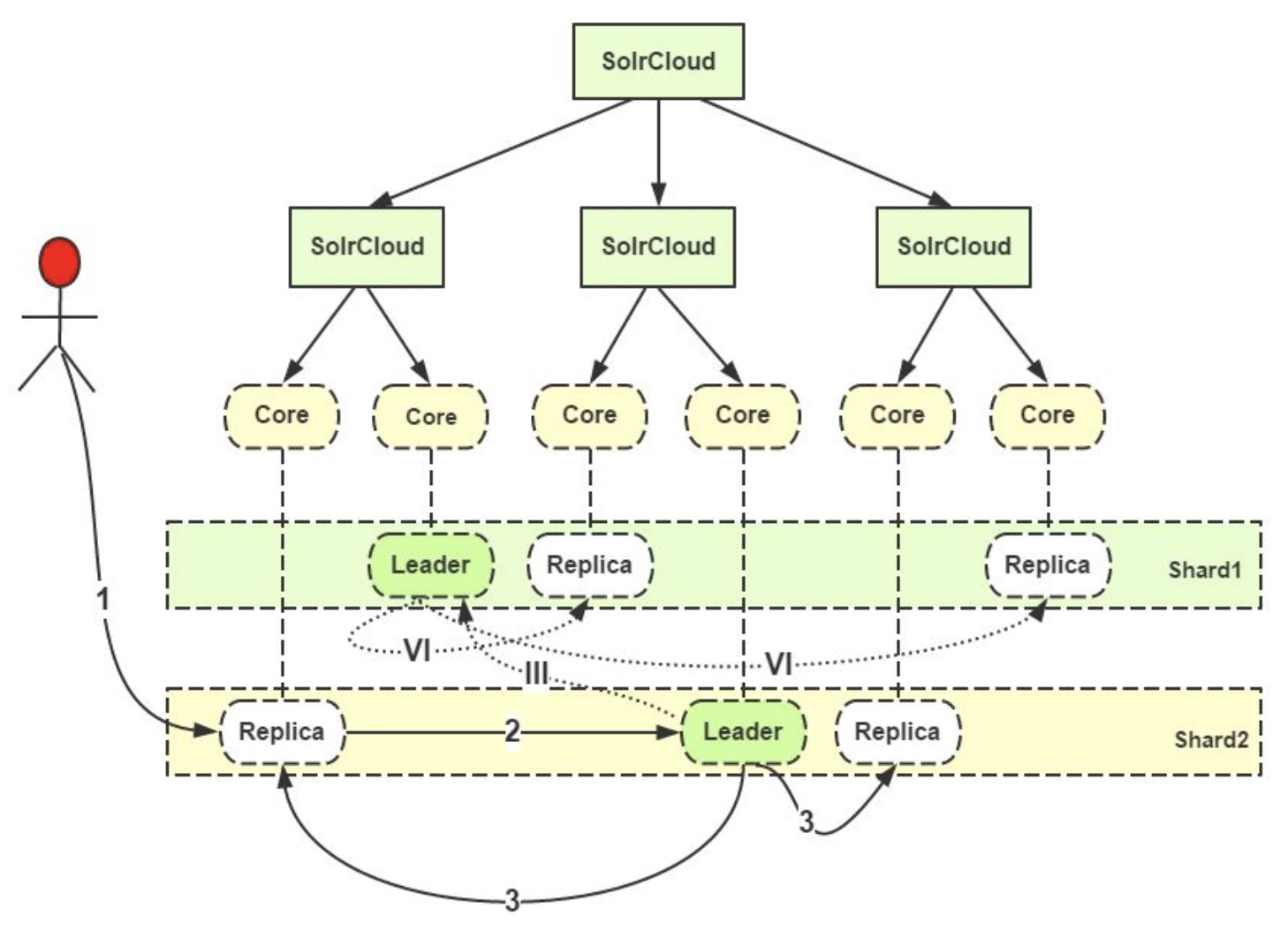
參照上圖, 解析添加索引的過程:
(1) 用戶把要添加的文檔提交給任意一個Replica(副本, 可以是主副本, 也可以是從副本);
(2) 如果接收到請求的Replica不是Leader, 它會把請求轉給同Shard中的Leader;
(3) Leader把文檔路由給本Shard的其他所有Replica;
(III) 如果根據路由規則, 當前文檔並不屬於當前的Shard, 這個Leader就會把它轉交給對應Shard的Leader;
(VI) 對應的Leader會把文檔路由給本Shard的每個Replica, 從而完成添加操作.
註意:
添加索引時, 單個document的路由非常簡單.
但是SolrCloud支持批量添加索引, 也就是說對多個document同時進行路由, 這時SolrCloud會根據document路由的去向分開存放document, 然後併發傳送到相應的Shard, 這就需要SolrCloud具有較高的併發能力.
3 更新索引的過程
(1) Leader接受到update請求後, 先將需要修改的文檔存放到本地的update log, 同時Leader還會對這個文檔分配新的version(版本信息), 對於已經存在的文檔, 如果新版本值大於舊版本值, 就會拋棄舊版本;
(2) 一旦document經過驗證並修改了version後, 就會被並行轉發到所有上線的Replica;
SolrCloud並不關註那些已經下線的Replica, 因為當它們上線之後就會有Recovery恢復進程對它們進行恢復. 如果Replica處於recovering(恢復中)的狀態, 那這個Replica就會把update放入update transaction日誌, 等待恢復完成後再做同步.
(3) 當Leader接受到所有的Replica的成功反饋後, 它才會向客戶端反饋操作成功的信息;
Shard中就算只有一個Replica是active的, Solr都會繼續接受update請求 —— 這個策略犧牲了一致性, 換取了寫入的有效性.
有一個很重要的參數:
leaderVoteWait: 只有一個Replica的時候, 這個Replica進入recovering狀態並持續一段時間等待Leader的重新上線. 如果在這段時間內Leader沒有上線, 它就會轉成Leader. 期間可能會導致部分document丟失.==> 可以借鑒ZooKeeper的選舉策略, 使用majority quorum(大多數法定人數)策略來避免這個情況: 比如當多數Replica下線了, 客戶端的寫請求就會失敗.
(4) 索引的commit(提交)有兩種:
① softcommit(軟提交): 在記憶體中生成segment, 此時document是可見的, 可以供客戶端請求查詢, 但是還沒有寫入磁碟, 系統斷電等故障後數據會丟失;
② hardcommit(硬提交): 直接把記憶體中的數據寫入磁碟, 知道寫入完成才可見.
—— 軟提交的近實時性更強, 硬提交的安全性更高.
4 Solr創建和更新索引的總結
4.1 Leader的轉發規則
(1) 請求來自Leader轉發: 只需要把數據寫到本地的ulog, 不需要轉發給Leader, 也不需要轉發給其它的Replicas. 如果當前Replica處於非活躍狀態, 就會將請求數據接受並寫入ulog, 但不會寫入索引; 如果發現有重覆的更新, 會丟棄舊版本的更新;
(2) 請求不是來自Leader, 但自己就是Leader: 需要把請求寫到本地, 並分發給其他的Replicas;
(3) 請求不是來自Leader, 自己也不是Leader: 該請求應該是最原始的請求, 就需要將請求寫到本地ulog, 順便轉發給Leader, 再由Leader分發給同一個Shard下的Replica.
(4) 每commit一次(生成新的提交點), 就會重新生成一個ulog更新日誌. 當伺服器掛掉、記憶體數據丟失的時候, 數據就可以從ulog中恢復.
4.2 高效實踐的建議
(1) 創建索引的時候最好使用CloudSolrServer: 因為CloudSolrServer會直接向Leader發送update請求, 避免了網路的額外開銷;
(2) 批量添加索引的時候, 建議在客戶端提前做好document的路由, 因為在SolrCloud內進行文檔路由的開銷比較大.
參考資料
版權聲明
作者: ma_shoufeng(馬瘦風)
出處: 博客園 馬瘦風的博客
您的支持是對博主的極大鼓勵, 感謝您的閱讀.
本文版權歸博主所有, 歡迎轉載, 但請保留此段聲明, 併在文章頁面明顯位置給出原文鏈接, 否則博主保留追究相關人員法律責任的權利.


