一、shuffle機制概述 shuffle機制就是發生在MR程式中,Mapper之後,Reducer之前的一系列分區排序的操作。shuffle的作用是為了保證Reducer收到的數據都是按鍵排序的。 二、shuffle機制的流程 還是按照上個隨筆MR整體流程的需求來做參考: 1.Mapper中con ...
一、shuffle機制概述
shuffle機制就是發生在MR程式中,Mapper之後,Reducer之前的一系列分區排序的操作。shuffle的作用是為了保證Reducer收到的數據都是按鍵排序的。
二、shuffle機制的流程
還是按照上個隨筆MR整體流程的需求來做參考:
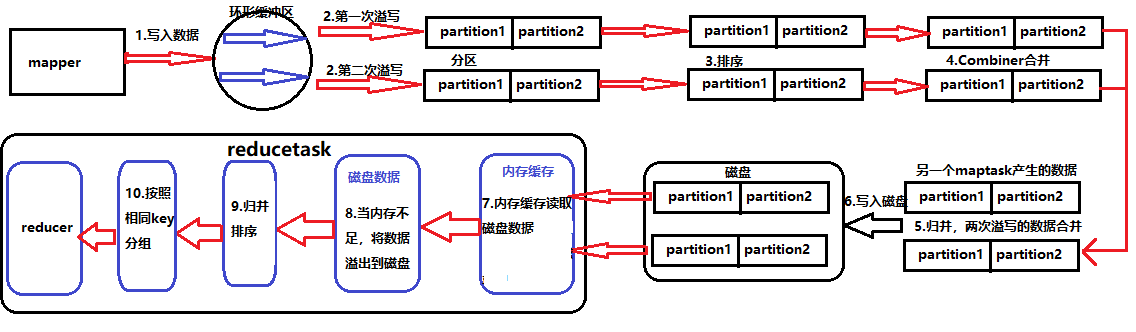
1.Mapper中context的write方法將數據寫入環形緩衝區,當容量到達80%發生溢寫;
2.按照一塊數據為128M,那麼應該會發生兩次溢寫,對溢寫出的數據進行分區;
3.然後對完成分區的數據進行區內排序;
4.如果數據量到達一定規模可以使用Combiner合併,這是一個區內合併;
5.接著會將兩次一次的數據進行歸併操作,合二為一;
6.將歸併後的數據寫入磁碟;
7.maptask工作完成後,reducetask的記憶體會緩衝讀取磁碟中的數據文件;
8.當記憶體不足時會將數據溢出到磁碟;
9.對存入磁碟的數據進行歸併排序(輔助排序在這個階段);
10.按照相同的key分組,然後一條一條讀入reducer。
如圖: