
前幾天工作忙得焦頭爛額時,同事問了一下關於Map的特性,剎那間懵了一下,緊接著就想起來了一些關於Map的一些知識,因為只要涉及到Collection集合類時,就會談及Map類,因此理解好Map相關的知識是灰常重要的。 Collection集合類 與 Map類的層次結構,如下圖: Map是用來存儲 K ...
前幾天工作忙得焦頭爛額時,同事問了一下關於Map的特性,剎那間懵了一下,緊接著就想起來了一些關於Map的一些知識,因為只要涉及到Collection集合類時,就會談及Map類,因此理解好Map相關的知識是灰常重要的。
Collection集合類 與 Map類的層次結構,如下圖:
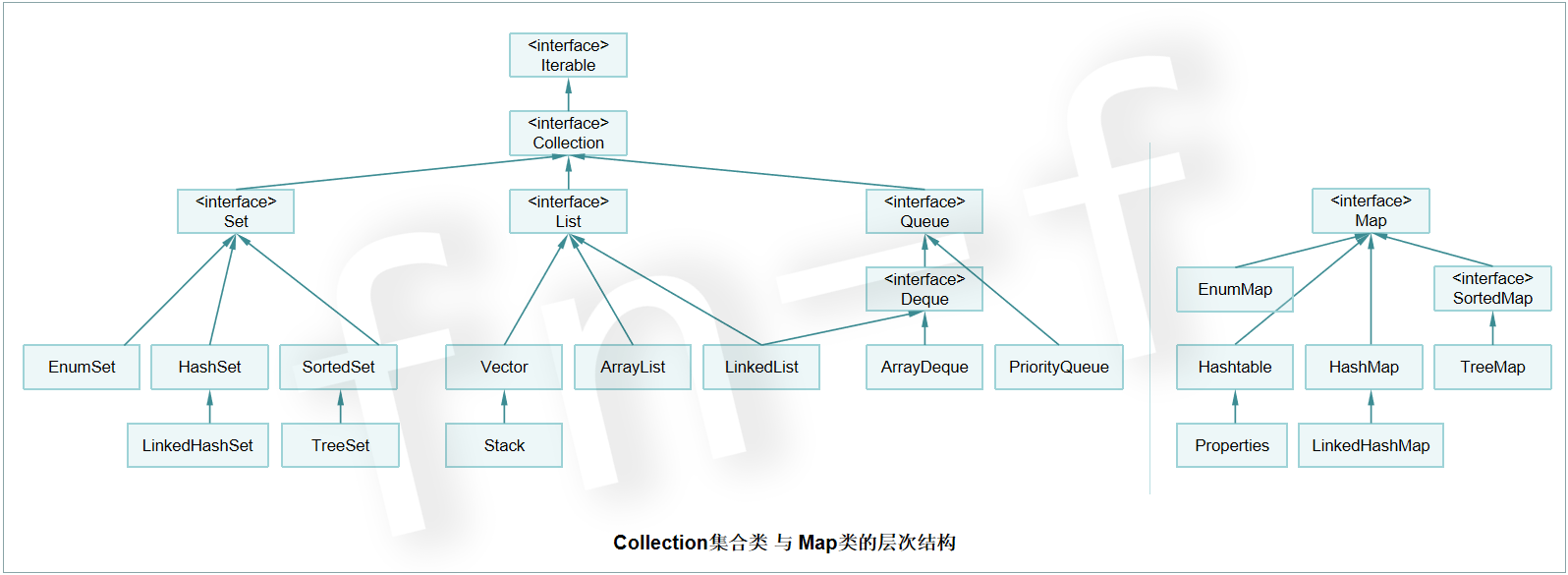
Map是用來存儲 Key-Value(K-V)鍵值對,且不允許Key重覆。(JDK 1.8)
Map的子類包含Hashtable,HashMap,LinkedHashMap,TreeMap,EnumMap,J.U.C併發包下麵包含ConcurrentHashMap,ConcurrentSkipListMap。
註:Hashtable是通過“synchronized”來實現同步,ConcurrentHashMap是通過“分段鎖”來實現併發,ConcurrentSkipListMap是通過“跳錶”來實現併發。
數據結構對比
JDK 1.7及之前,HashMap的底層是數組和鏈表結合使用,可以說其結構是單向鏈表構成的數組,即鏈表散列,又稱拉鏈法,即數組中的每一個序列空間代表一鏈表,若在插入新元素時,如果哈希衝突,則將新的元素插入到衝突的序列空間的鏈表頭部。

JDK 1.8之後,HashMap的底層是數組鏈表和二叉樹結合使用,其結構是先以鏈表結構進行存儲,如果當鏈表的節點數(閾值)大於等於8時,再將其轉換為二叉樹結構,若該二叉樹結構的節點數大於64,則再次resize,觸發rehash操作,重新分佈節點。

JDK 1.7 | 1.8 HashMap 方法分析

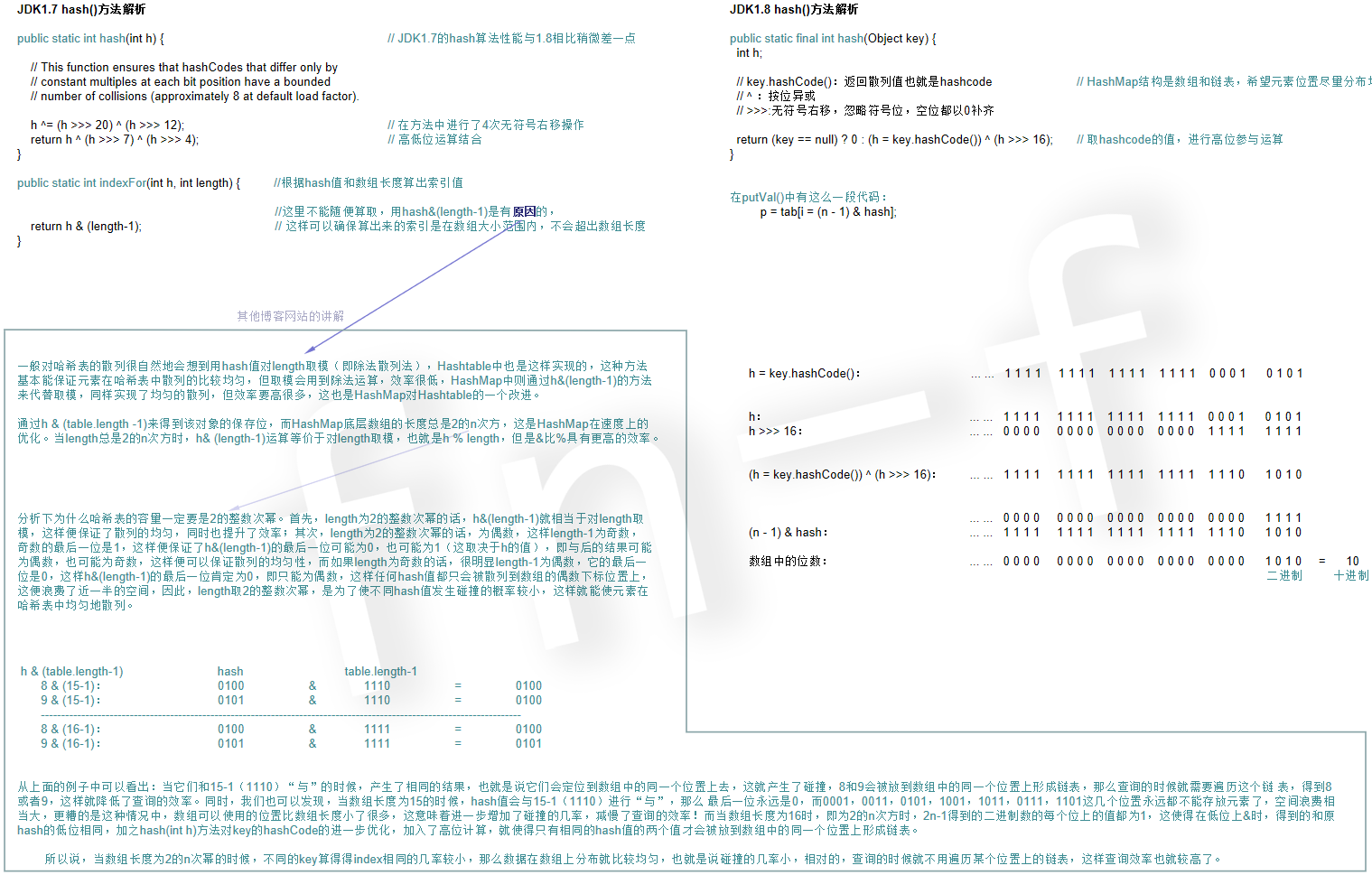
1. hashmap在JDK1.7|1.8中hash()方法優化:此處參考博客鏈接_hashmap衝突的解決方法以及原理分析
其實關於hash優化以及為什麼是2的次冪,能理解,但是總歸沒有辣麽詳細,所以就參考了其他博主的博客,如果不合適,還請提出,會進行刪除的。
2. hashmap在JDK中resize()方法
當HashMap的長度超過臨界值時(預設16*0.75=12),就會進行擴容。
通過調用resize()方法重新創建一個原HashMap大小的兩倍的元素數組newTable,最大擴容到 MAXIMUM_CAPACITY = 1 << 30,並將原先table的元素全部移到newTable裡面,重新計算hash,然後再重新根據hash分配位置。這個過程叫作rehash(最消耗性能的操作),因為它重新調用hash方法找到新的bucket位置。所以創建HashMap的時候,如果能預知元素個數,應儘量指定初始容量,這樣可以提高HashMap的性能,避免重覆resize()、rehash造成的性能損耗。
若在多線程情況下,多個線程同時出發resize()方法,會造成死迴圈操作
3. hashmap線程不安全,效率高
HashMap線程是不安全的,如果在多線程環境下,會出現未知異常(謹記)。
如果要在多線程情況下使用Map,有以下幾種可供選擇:
①、使用Hashtable(類中方法全是synchronized,效率特低,沒有過這種);
②、使用Collections.synchronizedMap(new HashMap(...));實現,但不建議使用,使用迭代器遍歷的時候修改映射結構容易出錯;
③、使用guava中ImmutableMap,它是線程安全的,且方便快捷的組裝鍵值對(建議);
ImmutableMap<String, Integer> map1 = ImmutableMap.<String, Integer>builder().put("A", 1) .put("B"2) .put("C", 3) .build();
ImmutableMap<String, Integer> map2 = ImmutableMap .<String, String>of("X", 0);
④、使用java.util.concurrent.ConcurrentHashMap,採用分段鎖(JDK1.7) / CAS(JDK1.8)、相對安全,效率高(建議);
4. hashmap其他方法解析
其他方法後續有時間在進行補充...
JDK 中 HashMap 的其他問題
暫未想到,如有錯誤,還請指正 ...

