
設計關係資料庫時,為了設計出合理的資料庫表結構,需要遵從不同的規範要求,這些規範性要求被稱為範式。 目前關係資料庫有六種範式:第一範式(1NF)、第二範式(2NF)、第三範式(3NF)、巴斯-科德範式(BCNF)、第四範式(4NF)和第五範式(5NF,又稱完美範式)。 各種範式呈遞次規範,越高的範式 ...
設計關係資料庫時,為了設計出合理的資料庫表結構,需要遵從不同的規範要求,這些規範性要求被稱為範式。
目前關係資料庫有六種範式:第一範式(1NF)、第二範式(2NF)、第三範式(3NF)、巴斯-科德範式(BCNF)、第四範式(4NF)和第五範式(5NF,又稱完美範式)。
各種範式呈遞次規範,越高的範式資料庫冗餘越小。滿足高層次範式的必定滿足低層次範式,如一個資料庫設計如果符合第二範式,一定也符合第一範式。
一、基本概念
1、實體:現實世界中客觀存在的並可以相互區分的對象或事物。如"公司"、"項目"、"員工"等。
2、屬性:實體所具有的某一特性。比如"公司名稱"、"公司地址"都是實體"公司"的屬性。
3、碼:表中可以唯一確定一行數據的某個屬性[或者屬性組]。如[員工號]、[員工號,績效評定月份]。不同的表結構,對應的碼不同。下文表(二)中,[員工號,績效評定月份]屬性組就是碼。
4、主屬性:包含在任何一個碼中的屬性稱為主屬性。下文表(二)中,員工號和績效評定月份就是主屬性。
5、非主屬性:與主屬性相反,沒有在任何候選碼中出現過,這個屬性就是非主屬性。下文表二中,員工姓名、部門、部門人數、績效就是非主屬性。
二、第一範式
1、概述
第一範式指的是符合第一範式的關係中的每個屬性都不可再分。
2、實例分析
下表(一)中,由於部門信息這個屬性可以再分為部門和部門人數這兩個屬性,所以不符合第一範式。
| 員工號 | 員工姓名 | 部門 | 績效評定月份 | 績效 | |
| 部門 | 部門人數 | ||||
| 10001 | 張三 | 開發部 | 30 | 201801 | 90 |
| 10001 | 張三 | 開發部 | 30 | 201802 | 85 |
| 10002 | 李四 | 集成部 | 30 | 201801 | 88 |
| 10002 | 李四 | 集成部 | 30 | 201802 | 87 |
| 10003 | 王五 | 綜合部 | 5 | 201802 | 89 |
| 10004 | 馬六 | 綜合部 | 5 | 201802 | 85 |
表(一)
將上表修改成如下表,就滿足第一範式。
| 員工號 | 員工姓名 | 部門 | 部門人數 | 績效評定月份 | 績效 |
| 10001 | 張三 | 開發部 | 30 | 201801 | 90 |
| 10001 | 張三 | 開發部 | 30 | 201802 | 85 |
| 10002 | 李四 | 集成部 | 30 | 201801 | 88 |
| 10002 | 李四 | 集成部 | 30 | 201802 | 87 |
| 10003 | 王五 | 綜合部 | 5 | 201802 | 89 |
| 10004 | 馬六 | 綜合部 | 5 | 201802 | 85 |
表(二)
第一範式是所有關係型資料庫的最基本要求,只要在關係型資料庫管理系統(RDBMS)中已經存在的數據表,一定是符合第一範式。
3、不足
A、數據冗餘:如上表中,員工號、員工姓名、部門、部門人數數據重覆出現多次。
B、插入異常:根據三種關係完整性約束中實體完整性的要求,關係中的碼所包含的任意一個屬性都不能為空,所有屬性的組合也不能重覆(可以簡單的理解為表的主鍵)。上表中,為了唯一區分每一條記錄,需要將(員工號,績效評定月份)作為碼。如果一個新建的部門還沒有員工的話,那麼就無法將部門和部門人數的信息插入到表中,導致插入異常,無法有效記錄部門的信息。
C、刪除異常:如果將員工相關的記錄都刪除,那麼部門相關的信息也會刪除,導致了刪除異常。
D、修改異常:假如張三轉到集成部,為了保證資料庫中數據的一致性,需要修改兩條條記錄中部門與部門人數的數據,導致修改異常。
三、第二範式
1、概述
第二範式是為瞭解決第一範式所帶來的問題而設定的規則,它是在第一範式的基礎之上,消除了非主屬性對於碼的部分函數依賴。簡單地說,第二範式要求每個非主屬性完全依賴於主鍵,而不是僅依賴於主鍵其中的一部分屬性。
2、相關概念
A、函數依賴
在一張表中,如果在屬性(或屬性組)X的值確定的情況下,必定能確定屬性Y的值,那麼就可以說Y函數依賴於X,寫作 X → Y。也就是說,在數據表中,不存在任意兩條記錄,它們在X屬性(或屬性組)上的值相同,而在Y屬性上的值不同。
在上表(二)中,存在著以下的函數依賴:
★ 員工號 → 員工姓名
★ 部門 → 部門人數
★ (員工號,績效評定月份) → 績效
以下的函數依賴則不成立:
★ 員工號 → 績效評定月份
★ 員工號 → 績效
B、完全函數依賴
如果X → Y是一個函數依賴,且對X的任何一個真子集X',都不存在X' → Y,則稱X → Y是一個完全函數依賴。為了方便表述,寫作X>>Y(非正式方式)。
在上表中,存在著以下的完全函數依賴:
★ 員工號>>員工姓名
★ (員工號,績效評定月份)>>績效(員工號對應的績效不確定,績效評定月份對應的績效也不確定)
C、部分函數依賴
如果X → Y是一個函數依賴,並且存在X的一個真子集X',使得X' → Y,則稱X → Y是一個部分函數依賴。為了方便表述,寫作X>Y(非正式方式)。
在上表中,存在著以下的部分函數依賴:
★ (員工號,績效評定月份)>員工姓名
D、傳遞函數依賴
如果X→Y,Y→Z,且Y不屬於X,Y → X不成立,則稱Z傳遞函數依賴於X。為了方便表述,寫作X>>>Z(非正式方式)。(限定Y不屬於X,Y→X不成立,是因為如果Y屬於X,那麼Z部分函數依賴於X,此時X中存在多餘屬性;若Y → X成立,則有X和Y等價,則關係中沒有必要同時存在X和Y)
在上表中,存在著以下的傳遞函數依賴:
★ 員工號>>>部門人數(員工號 → 部門,部門 → 部門人數)
3、實例分析
根據定義,我們可以知道:第二範式就是判斷是否存在非主屬性對於碼的部分函數依賴,如果存在,則不滿足第二範式。
判斷一個表是否符合第二範式,可以通過以下步驟進行判斷:
★ 找出表中所有的碼;
★ 根據第一步找出的碼,找出所有的主屬性;
★ 根據主屬性,找出所有的非主屬性;
★ 判斷是否存在非主屬性對於碼的部分函數依賴,由此判定是否符合第二範式;
我們根據以上步驟來分析一下上表(二):
★ 該表的碼為:(員工號,績效評定月份)
★ 該表的主屬性為:員工號、績效評定月份
★ 該表的非主屬性為:員工姓名、部門、部門人數、績效
★ 該表的非主屬性對於碼的函數依賴關係如下:
[員工號,績效評定月份] → 績效,完全函數依賴;
[員工號,績效評定月份]→ 員工姓名,部分函數依賴;因為存在:員工號 → 員工姓名
[員工號,績效評定月份]→ 部門,部分函數依賴;因為存在:員工號 → 部門
[員工號,績效評定月份]→ 部門人數,傳遞函數依賴;因為存在:員工號 → 部門,部門 → 部門人數
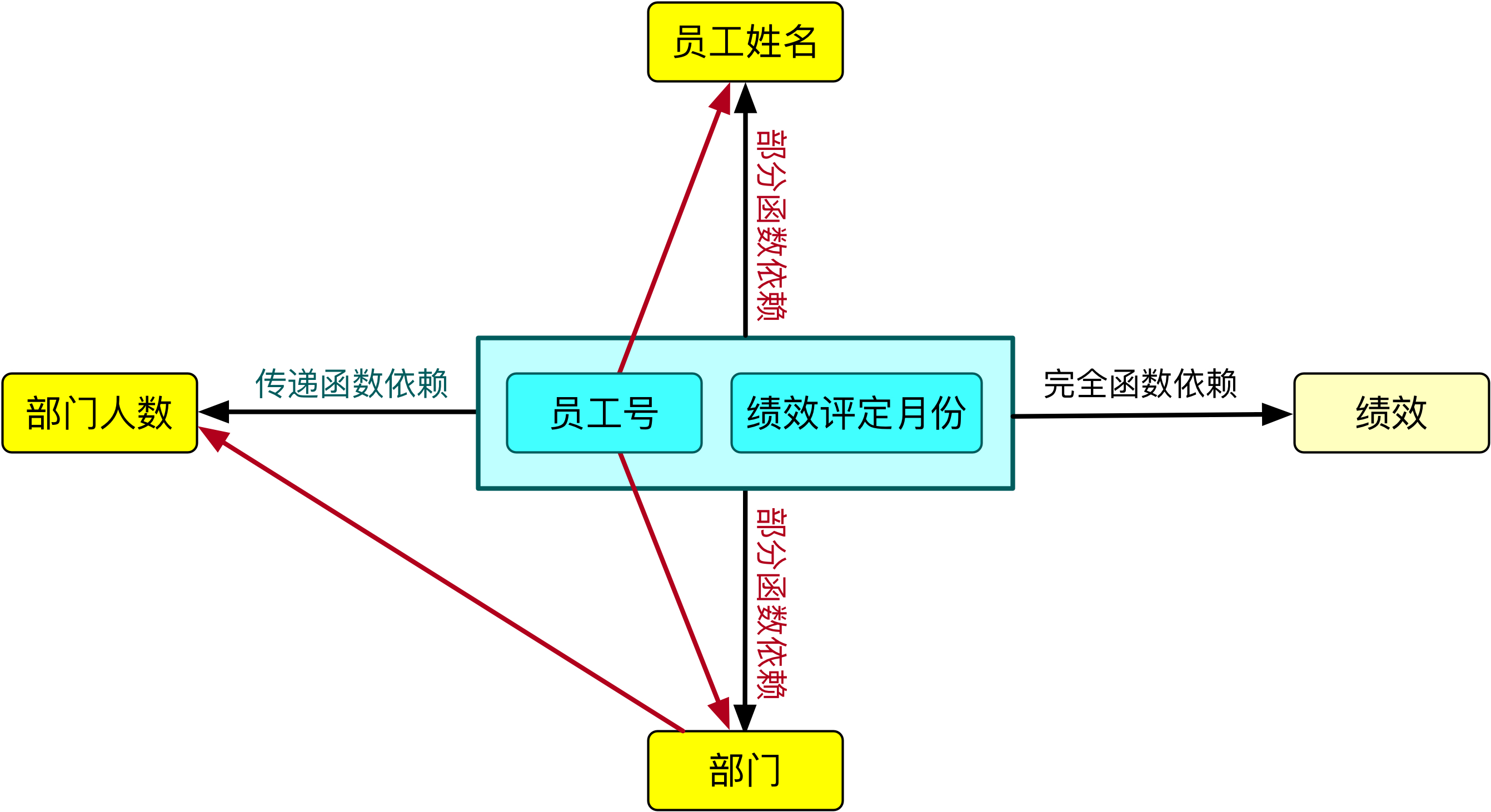
由於存在非主屬性對於碼的部分函數依賴,所以上表不符合第二範式。
為了符合第二範式的要求,我們必須消除這些部分函數依賴,將大表拆分成更多個更小的表。
我們將上表拆分成如下的兩個表:
| 員工號 | 績效評定月份 | 績效 |
| 10001 | 201801 | 90 |
| 10001 | 201802 | 85 |
| 10002 | 201801 | 88 |
| 10002 | 201802 | 87 |
| 10003 | 201802 | 89 |
| 10004 | 201802 | 85 |
表(三)
| 員工號 | 員工姓名 | 部門 | 部門人數 |
| 10001 | 張三 | 開發部 | 30 |
| 10002 | 李四 | 集成部 | 30 |
| 10003 | 王五 | 綜合部 | 5 |
| 10004 | 馬六 | 綜合部 | 5 |
表(四)
兩個表的非主屬性對於碼的函數依賴關係如下:
★ [員工號,績效評定月份]→ 績效,完全函數依賴;
★ 員工號 → 員工姓名,完全函數依賴;
★ 員工號 → 部門,完全函數依賴;
★ 員工號 → 部門人數,完全函數依賴和傳遞函數依賴;因為存在:員工號 → 部門,部門 → 部門人數
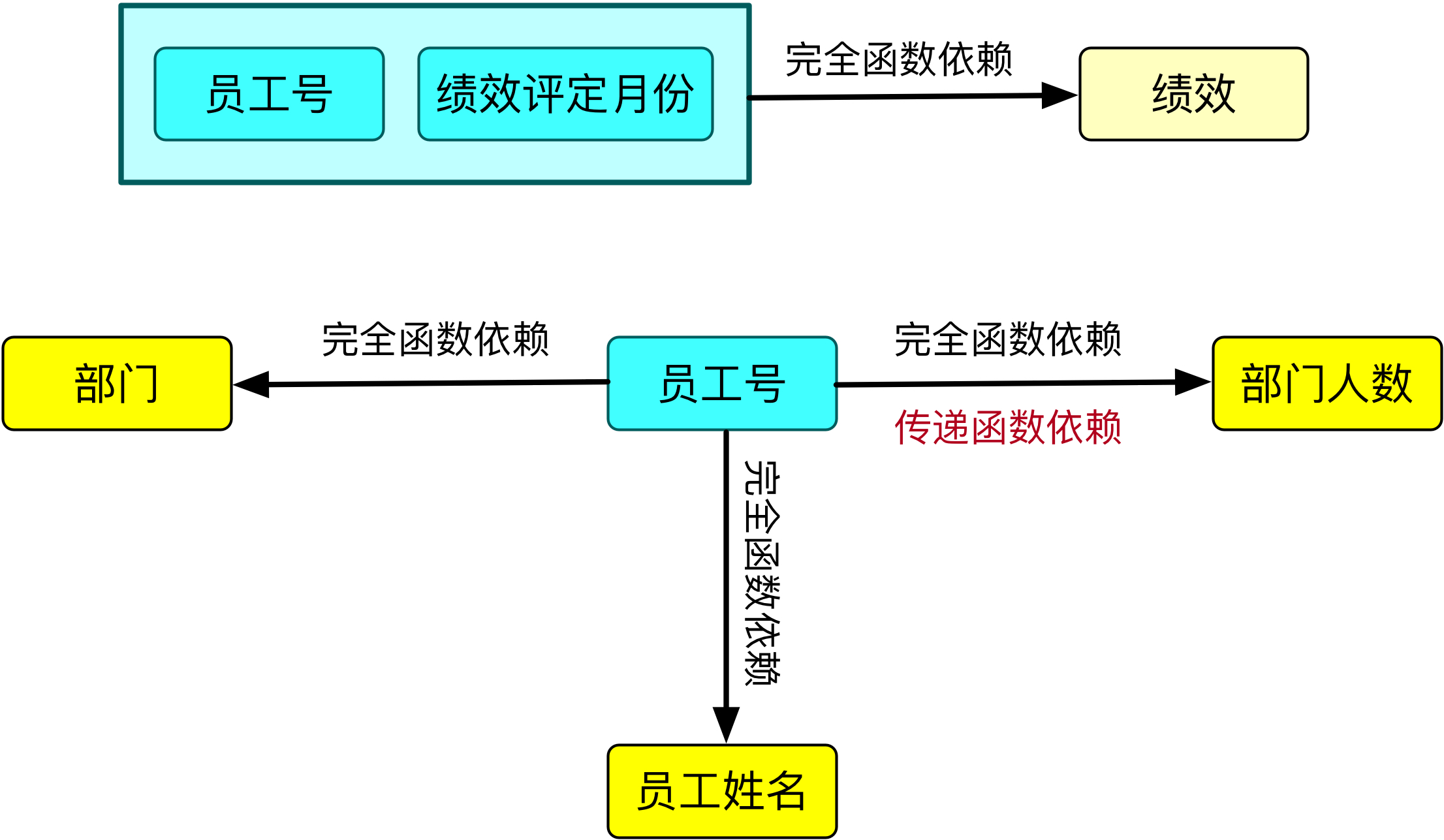
由於兩個表都符合完全函數依賴,所以兩個表都符合第二範式。
那麼第二範式是否解決了第一範式的不足呢?
A、數據冗餘:除部門人數數據重覆外,其餘無冗餘。有改進。
B、插入異常:根據三種關係完整性約束中實體完整性的要求,關係中的碼所包含的任意一個屬性都不能為空,所有屬性的組合也不能重覆(可以簡單的理解為表的主鍵)。員工-部門表中,為了唯一區分每一條記錄,需要將員工號作為碼。如果一個新建的部門還沒有員工的話,那麼就無法將部門和部門人數的信息插入到表中,導致插入異常,無法記錄部門的信息。無改進。
C、刪除異常:表(四)中,如果將員工相關的記錄都刪除,那麼部門相關的信息也會刪除,導致了刪除異常。無改進。
D、修改異常:假如張三轉到集成部,只需要改動對應的部門即可。有改進。
所以,僅僅符合第二範式的要求,很多情況下還是不夠的,為了能進一步解決這些問題,我們還需要將符合第二範式要求的表改進為符合第三範式的要求。而導致這些的原因是傳遞函數依賴。
三、第三範式
1、概述
第三範式是在第二範式的基礎之上,消除非主屬性對於碼的傳遞函數依賴。
2、實例分析
在上述例子中,由於存在員工號與部門人數的傳遞函數依賴,所以需要將表(四)進行再次拆分,拆分後所有表如下:
| 員工號 | 績效評定月份 | 績效 |
| 10001 | 201801 | 90 |
| 10001 | 201802 | 85 |
| 10002 | 201801 | 88 |
| 10002 | 201802 | 87 |
| 10003 | 201802 | 89 |
| 10004 | 201802 | 85 |
表(五)
| 員工號 | 員工姓名 | 部門 |
| 10001 | 張三 | 開發部 |
| 10002 | 李四 | 集成部 |
| 10003 | 王五 | 綜合部 |
| 10004 | 馬六 | 綜合部 |
表(六)
| 部門 | 部門人數 |
| 開發部 | 30 |
| 集成部 | 30 |
| 綜合部 | 5 |
表(七)
以上三個表均滿足第三範式,那麼第三範式是否解決了第二範式的不足呢?
A、數據冗餘:無冗餘。有改進。
B、插入異常:可以插入部門信息。有改進。
C、刪除異常:刪除員工信息,部門信息不會刪除。有改進
D、修改異常:假如張三轉到集成部,只需要改動對應的部門即可。有改進。
所以第三範式基本解決了數據冗餘、插入異常、刪除異常、修改異常等問題。
四、其它範式(待補充細化)
A、BCNF範式
1、所有非主屬性都完全函數依賴於每個候選鍵
2、所有主屬性都完全函數依賴於每個不包含它的候選鍵
3、沒有任何屬性完全函數依賴於非候選鍵的任何一組屬性
B、第四範式
解決多值依賴問題,要求把同一表內的多對多關係刪除。表示在多對多關係中,實體本身並不存儲關係,而關係都記錄在另一個中間關係表中,要選擇倆個多對多實體間的數據,必須通過中間關係表來得到,實體本身沒有存儲任何與另外一個實體的關係的記錄。
C、第五範式
也稱投影-連接範式,是資料庫規範化的一個級別,以去除多個關係之間的語義相關。一張表滿足第五範式當且僅當它的每個連接依賴可由候選鍵推出。
五、總結
範式就是在資料庫表設計時移除數據冗餘的過程。隨著範式級別的提升,數據冗餘越來越少,但資料庫的效率也越來越低。


