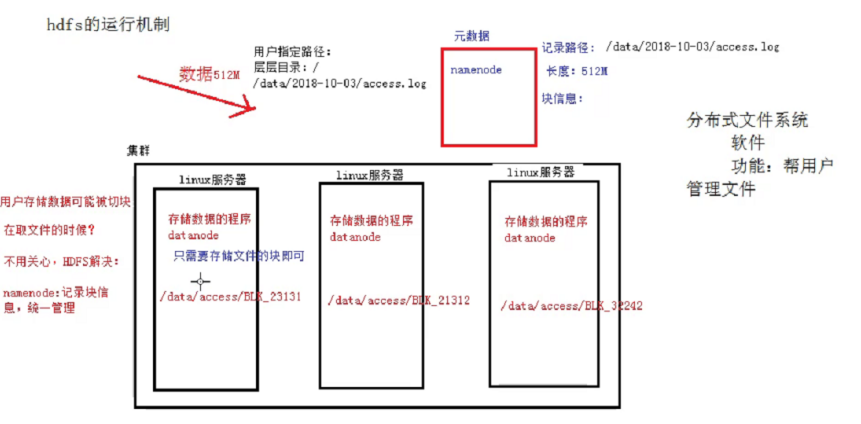
一、HDFS運行機制 概述:用戶的文件會被切塊後存儲在多台datanode節點中,並且每個文件在整個集群中存放多個副本,副本的數量可以通過修改配置自己設定。 HDFS:Hadoop Distributed file system,分散式文件系統。 HDFS的機制: HDFS集群中,有兩種節點,分別為 ...
一、HDFS運行機制
概述:用戶的文件會被切塊後存儲在多台datanode節點中,並且每個文件在整個集群中存放多個副本,副本的數量可以通過修改配置自己設定。
HDFS:Hadoop Distributed file system,分散式文件系統。
HDFS的機制:
HDFS集群中,有兩種節點,分別為Namenode,Datanode;
Namenode它的作用時記錄元數據信息,記錄塊信息和對節點進行統一管理。比如用戶要存儲一個很大的文件,HDFS系統會對這個文件進行切分,然後存儲在多台Namenode節點當中,那麼每個切的大小,存儲的路徑信息,文件的副本數等元數據信息會存儲在元數據當中,由Namenode進行管理和記錄。
Datanode節點的作用是存儲數據,Namenode將數據切塊後的分配給多個Datanode節點,Datanode對數據塊進行存儲,Datanode它預設的塊大小在hadoop1.x的版本中是64M,而hadoop2.x之後的版本預設塊大小為128M。
HDFS還有一個副本機制,它會預設給存在Datanode當中的每塊文件進行備份,預設的副本數量(republication)為3,這樣保證了數據的安全性。
大致如圖:
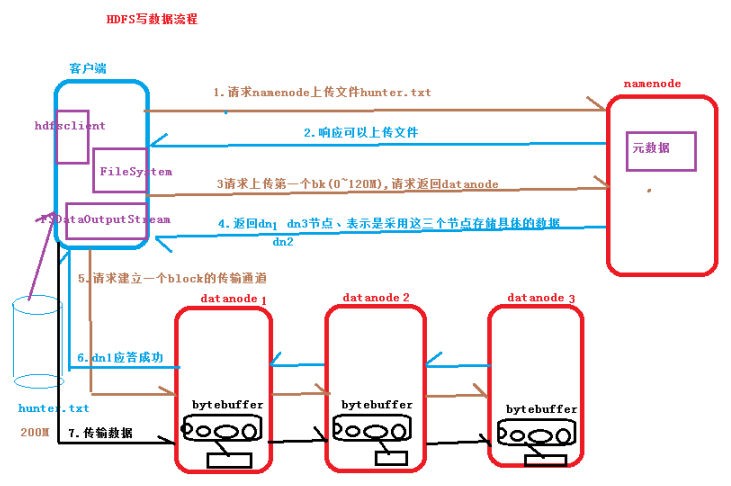
二、HDFS寫數據流程
1.客戶端向Namenode請求上傳文件數據Hunter.txt(大小:200M);
2.Namenode響應可以上傳文件;
3.客戶端向Namenode請求上傳第一個block(0~128M),請求返回Datanode節點;
4.Namenode返回三個Datanode節點(副本數預設為3),採用這三個節點存儲數據;
5.客戶端向Datanode請求建立一個block的傳輸通道;
6.Datanode應答通道建立成功;
7.客戶端向Datanode傳輸數據,數據寫入到HDFS文件系統當中。
三、hdfs讀數據流程
1.客戶端向Namenode請求下載文件hunter.txt(200M);
2.Namenode返回目標文件的元數據信息(block所在的datanode);
3.客戶端向Datanode請求讀取數據文件;
4.Datanode以FSDataInputStream流的形式向客戶端傳輸數據;
5.客戶端生成hunter.txt文件。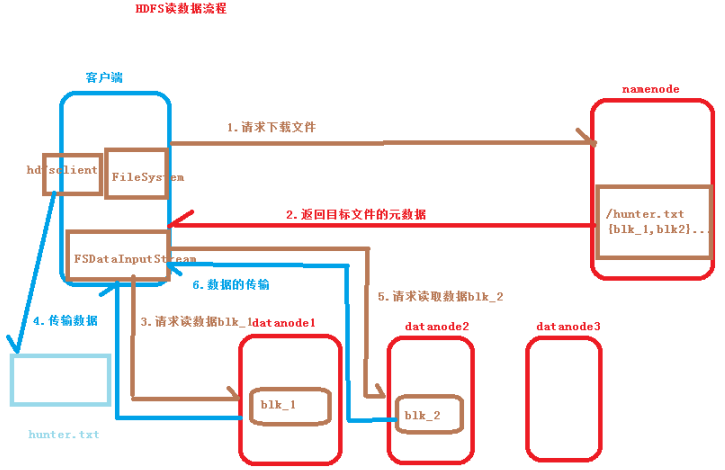
四、Namenode運行機制
首先去到主節點namenode的元數據信息dfs目錄中,可以看到很多種文件,如下:
edits:存放HDFS系統所有的更新操作的日誌文件
fsimage:HDFS元數據的永久性的檢查點,其中包含了hdfs系統所有的目錄和文件
seen_txid:最有一個edits文件的數字,即edits文件個數
VERSION:記錄了很多的id,如下:
namespaceID:每個節點的id,每個節點都不同
ClusterID:一個集群統一的id,是唯一的,一個集群中所有節點的ClusterID都相同
CTime:Namenode存儲系統的使用時間的時間戳
storageType:節點類型
blockpoolID:跨集群的全局唯一
layoutVersion:版本號
Namenode的運行機制:
1.首先啟動集群,會啟動Namenode和SecondaryNamenode,兩個節點的記憶體會載入日誌文件和鏡像文件(edits、fsimage文件);
2.當客戶端對HDFS集群進行增刪改查等操作時,日誌文件會更新滾動;
3.當eidts文件數量達到預設閾值,或checkpoint時間到達預設觸發時間時;
(dfs.namenode.checkpoint.period :多久checkpoint一次、
dfs.namenode.checkpoint.check.period:多久檢查一次操作的次數、
dfs.namenode.checkpoint.txns:多少次操作後chechpoint一次)
4.Namenode將edits文件拷貝到SecondarNamenode;
5.SecondarNamenode的記憶體會載入拷貝的edits文件併合並;
6.SecondarNamenode會生成新的鏡像文件fsimage.checkpoint;
7.SecondarNamenode將新生產的鏡像文件拷貝到Namenode;
8.Namenode將收到的鏡像文件重命名為fsimage;
9.Namenode將新的fsimage鏡像文件發送到SecondarNamenode
這樣兩個節點的元數據信息就相同了!!!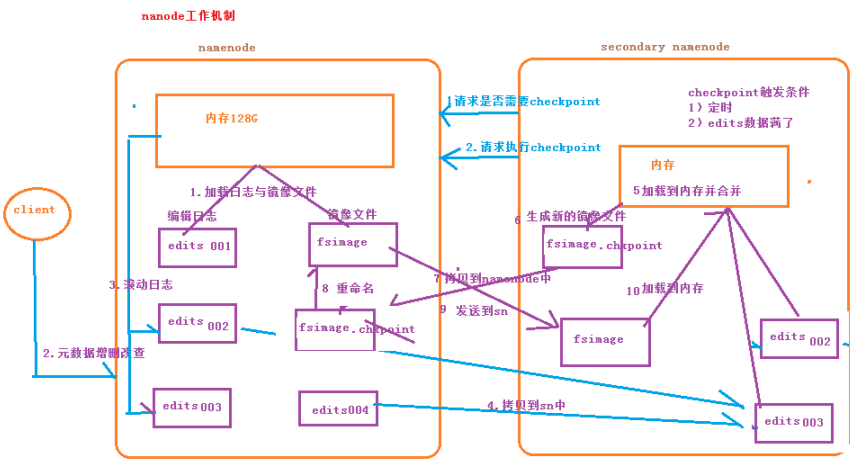
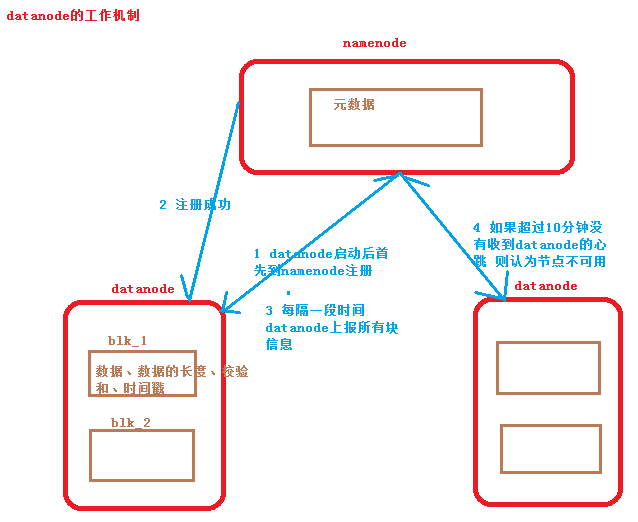
五、Datanode運行機制
1.HDFS集群啟動後,Datanode現象Namenode發送註冊信息;
2.Namenode返回註冊成功;
3.每隔一段時間Datanode會上傳所有的塊信息到Namenode;
(塊信息:數據、數據長度、校驗和、時間戳等)
4.預設如果超過10分鐘Namenode沒有收到Datanode的信息信息,則認為節點不可用