
爬蟲原理 瀏覽器獲取網頁內容的步驟:瀏覽器提交請求、下載網頁代碼、解析成頁面,爬蟲要做的就是: 簡單例子:利用Urllib庫爬取w3c網站教程 1、urllib的request模塊可以非常方便地抓取URL內容,也就是發送一個GET請求到指定的頁面,然後返回HTTP的響應:例如,對百度的一個w3c發送 ...
爬蟲原理
瀏覽器獲取網頁內容的步驟:瀏覽器提交請求、下載網頁代碼、解析成頁面,爬蟲要做的就是:
- 模擬瀏覽器發送請求:通過HTTP庫向目標站點發起請求Request,請求可以包含額外的header等信息,等待伺服器響應
- 獲取響應內容:如果伺服器正常響應,會得到一個響應Response,響應的內容便是所要獲取的頁面內容,類型可能是HTML,Json字元串,二進位數據(圖片或者視頻)等
- 解析響應內容:獲取響應內容後,解析各種數據,如:解析html數據:正則表達式,第三方解析庫,解析json數據:json模塊,解析二進位數據:進一步處理或以wb的方式寫入文件
- 保存數據:保存為文本,資料庫,或者保存特定格式的文件
簡單例子:利用Urllib庫爬取w3c網站教程
1、urllib的request模塊可以非常方便地抓取URL內容,也就是發送一個GET請求到指定的頁面,然後返回HTTP的響應:例如,對百度的一個w3c發送一個GET請求,並返迴響應:
# coding:utf-8 import urllib.request my_url='https://www.w3cschool.cn/tutorial'#要獲取課程的網址 page = urllib.request.urlopen(my_url) html = page.read().decode('utf-8') print(html)
把發送一個GET請求到指定的頁面,返回HTTP的響應寫成一個函數:
def get_html(url):#訪問url page = urllib.request.urlopen(url) html = page.read().decode('utf-8') return html
將返回如下內容,這與在瀏覽器查看源碼看到的是一樣的,接下來可以根據返回的內容進行解析:

2、利用正則表達式的分組提取課程名稱、課程簡介、課程鏈接,導入python裡面的re庫
reg = r'<a href="([\s\S]*?)" title=[\s\S]*?<h4>(.+)</h4>\n<p>([\s\S]*?)</p>'#運用正則表達式,分組提取數據 reg_tutorial = re.compile(reg)#編譯一下正則表達式,運行更快 tutorial_list = reg_tutorial.findall(get_html(my_url))#進行匹配,
到現在代碼如下:
# coding:utf-8 import urllib.request import re my_url='https://www.w3cschool.cn/tutorial'#要獲取課程的網址 def get_html(url):#訪問url page = urllib.request.urlopen(url) html = page.read().decode('utf-8') return html reg = r'<a href="([\s\S]*?)" title=[\s\S]*?<h4>(.+)</h4>\n<p>([\s\S]*?)</p>'#運用正則表達式,分組提取數據 reg_tutorial = re.compile(reg)#編譯一下正則表達式,運行更快 tutorial_list = reg_tutorial.findall(get_html(my_url))#進行匹配 print("一共有課程數:" + str(len(tutorial_list)))#列印出有多少課程 for i in range(len(tutorial_list)):#把課程名稱、課程簡介、課程鏈接寫到excel,python裡面excel從0開始計算 print (tutorial_list[i])
運行,列印結果:

3、保存數據,保存數據到excel裡面,用到excel第三方庫xlwt,也可以只用openpyxl,庫的使用可以參照官網:http://www.python-excel.org/
本次需要新建一個Excel,把課程名稱、課程簡介、課程鏈接寫到Excel裡面,課程鏈接用xlwt.Formula設置超鏈接,Excel第一行設置為宋體,加粗,寫一些課程內容外的東西
import xlwt excel_path=r'tutorial.xlsx'#excel的路徑 book = xlwt.Workbook(encoding='utf-8', style_compression=0)# 創建一個Workbook對象,這就相當於創建了一個Excel文件 sheet = book.add_sheet('課程',cell_overwrite_ok=True)# 添加表 style = xlwt.XFStyle()#初始化樣式 font = xlwt.Font()#創建字體 font.name = '宋體'#指定字體名字 font.bold = True#字體加粗 style.font = font#將該font設定為style的字體 sheet.write(0, 0, '序號',style)#用之前的style格式寫第一行,行、列從0開始計算 sheet.write(0, 1, '課程',style) sheet.write(0, 2, '簡介',style) sheet.write(0, 3, '課程鏈接',style)
寫課程內容到Excel
for i in range(len(tutorial_list)):#把課程名稱、課程簡介、課程鏈接寫到excel,python裡面excel從0開始計算 print (tutorial_list[i]) sheet.write(i+1, 0, i+1) sheet.write(i+1, 1, tutorial_list[i][1]) sheet.write(i+1, 2, tutorial_list[i][2]) sheet.write(i+1, 3, xlwt.Formula("HYPERLINK(" +'"'+"https:" + tutorial_list[i][0]+'"'+')'))#把鏈接寫進去,並用xlwt.Formula設置超鏈接 book.save(excel_path)#保存到excel
Excel內容:
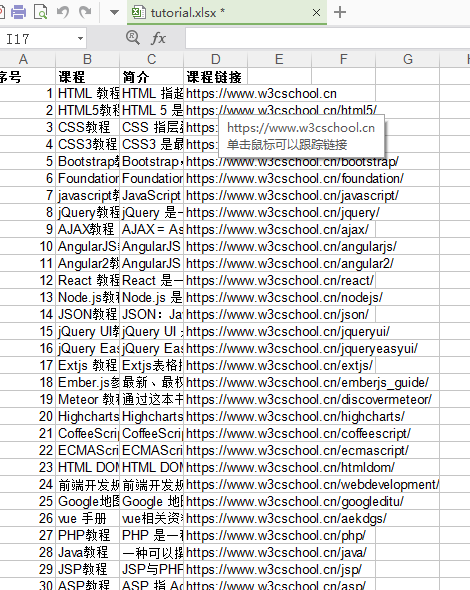
全部代碼如下:
# coding:utf-8 import urllib.request import re import xlwt excel_path=r'tutorial.xlsx'#excel的路徑 my_url='https://www.w3cschool.cn/tutorial'#要獲取課程的網址 book = xlwt.Workbook(encoding='utf-8', style_compression=0)# 創建一個Workbook對象,這就相當於創建了一個Excel文件 sheet = book.add_sheet('課程',cell_overwrite_ok=True)# 添加表 style = xlwt.XFStyle()#初始化樣式 font = xlwt.Font()#創建字體 font.name = '宋體'#指定字體名字 font.bold = True#字體加粗 style.font = font#將該font設定為style的字體 sheet.write(0, 0, '序號',style)#用之前的style格式寫第一行,行、列從0開始計算 sheet.write(0, 1, '課程',style) sheet.write(0, 2, '簡介',style) sheet.write(0, 3, '課程鏈接',style) def get_html(url):#訪問url page = urllib.request.urlopen(url) html = page.read().decode('utf-8') return html reg = r'<a href="([\s\S]*?)" title=[\s\S]*?<h4>(.+)</h4>\n<p>([\s\S]*?)</p>'#運用正則表達式,分組提取數據 reg_tutorial = re.compile(reg)#編譯一下正則表達式,運行更快 tutorial_list = reg_tutorial.findall(get_html(my_url))#進行匹配 print("一共有課程數:" + str(len(tutorial_list)))#列印出有多少課程 for i in range(len(tutorial_list)):#把課程名稱、課程簡介、課程鏈接寫到excel,python裡面excel從0開始計算 print (tutorial_list[i]) sheet.write(i+1, 0, i+1) sheet.write(i+1, 1, tutorial_list[i][1]) sheet.write(i+1, 2, tutorial_list[i][2]) sheet.write(i+1, 3, xlwt.Formula("HYPERLINK(" +'"'+"https:" + tutorial_list[i][0]+'"'+')'))#把鏈接寫進去,並用xlwt.Formula設置超鏈接 book.save(excel_path)#保存到excel


